Bayesian methods for parameter estimation and model comparison · Bayesian methods for parameter...
101
Bayesian methods for parameter estimation and model comparison Carson C Chow, LBM, NIDDK, NIH Monday, April 26, 2010
Transcript of Bayesian methods for parameter estimation and model comparison · Bayesian methods for parameter...

Bayesian methods for parameter estimation and
model comparison
Carson C Chow, LBM, NIDDK, NIH
Monday, April 26, 2010

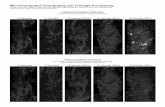
Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Monday, April 26, 2010
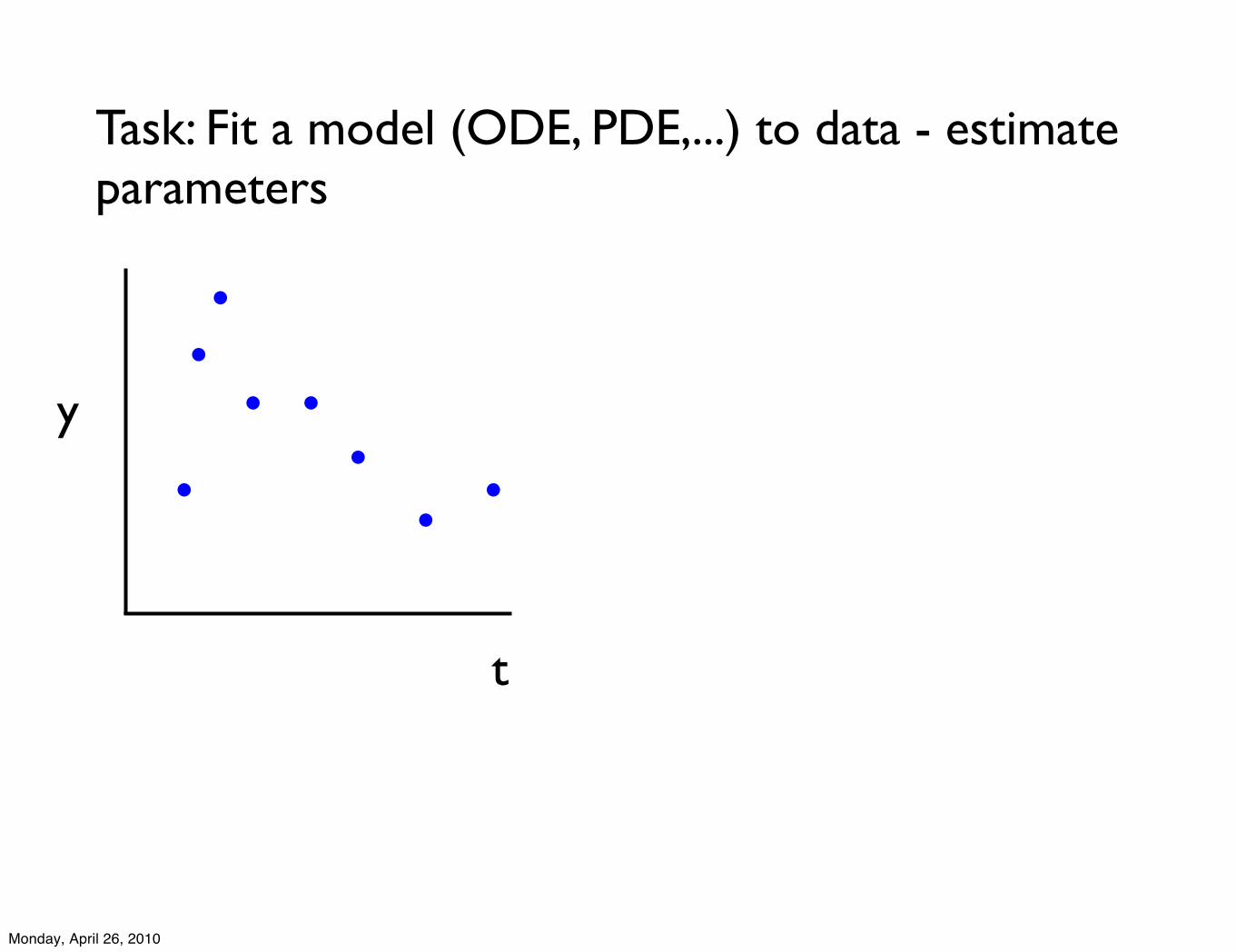
Task: Fit a model (ODE, PDE,...) to data - estimate parameters
t
y
Monday, April 26, 2010
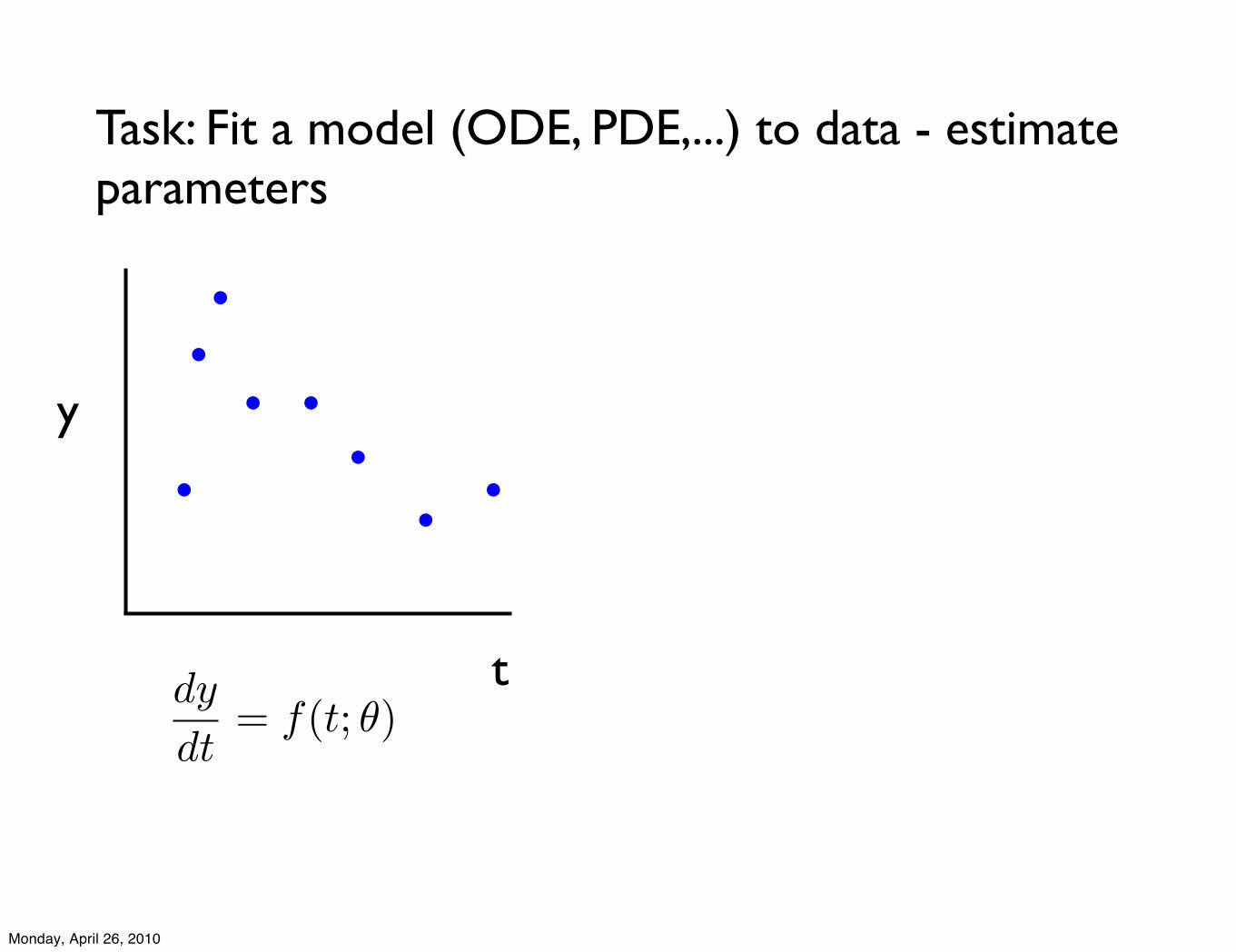
Task: Fit a model (ODE, PDE,...) to data - estimate parameters
dy
dt= f(t; !)
t
y
Monday, April 26, 2010
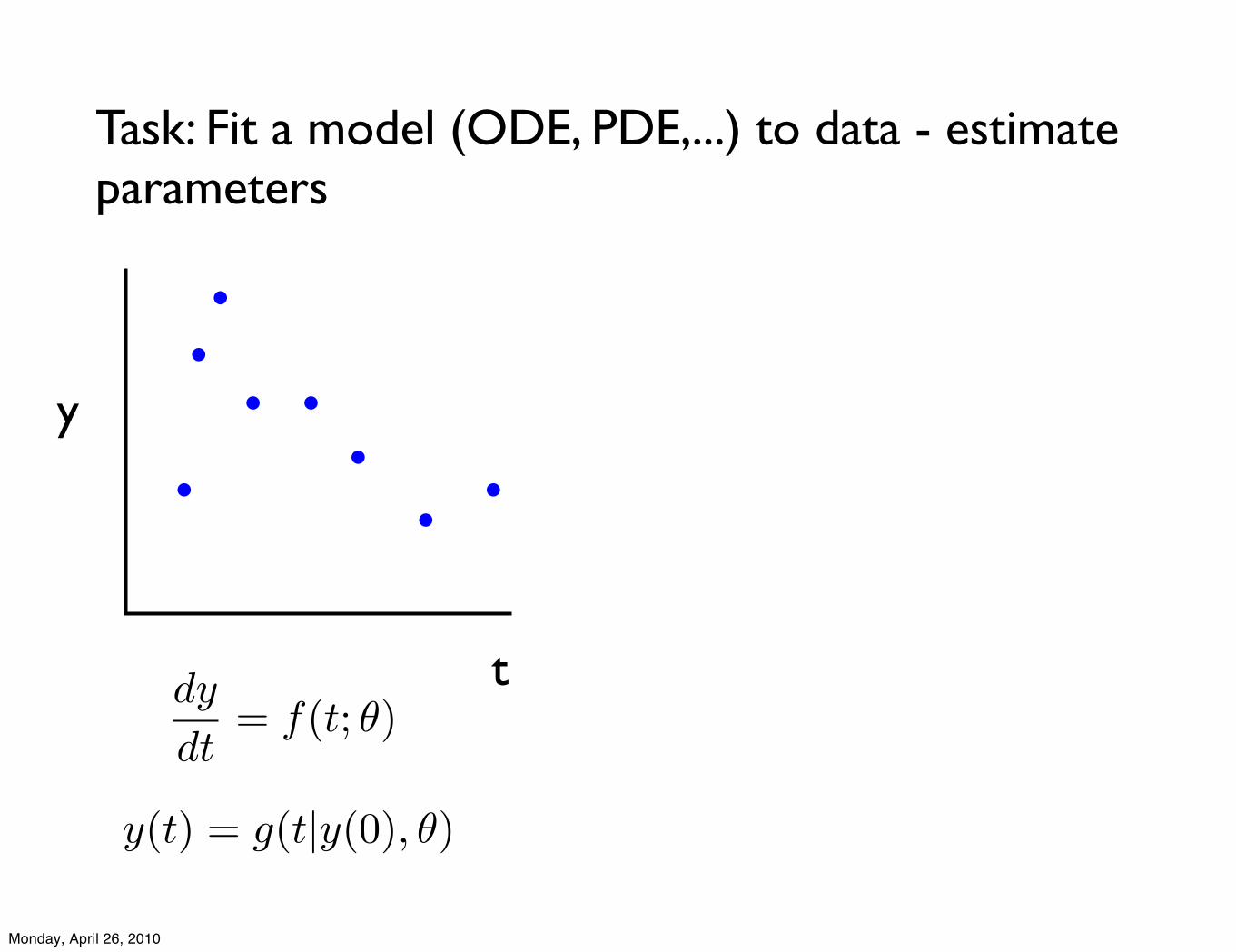
Task: Fit a model (ODE, PDE,...) to data - estimate parameters
dy
dt= f(t; !)
t
y
y(t) = g(t|y(0), !)
Monday, April 26, 2010
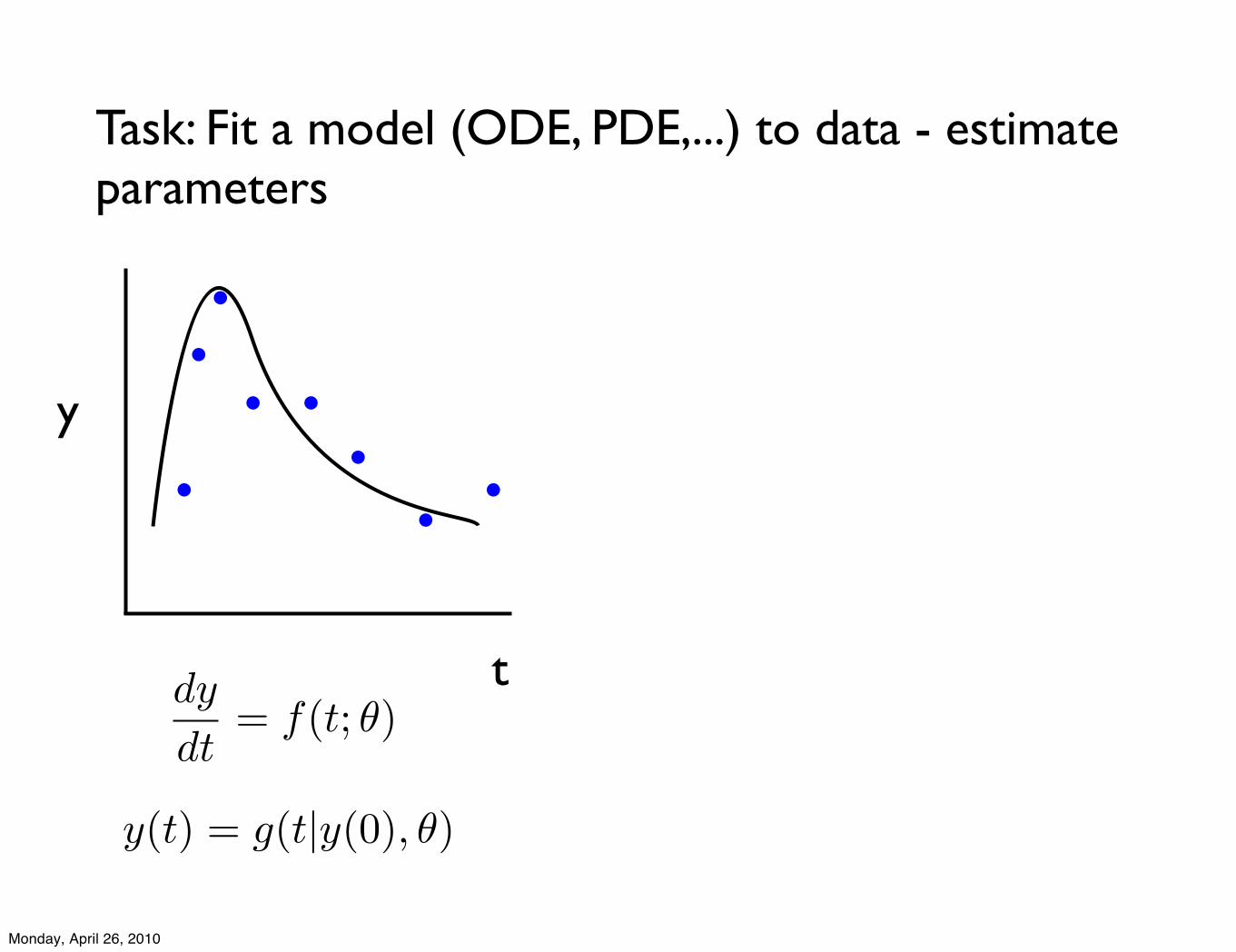
Task: Fit a model (ODE, PDE,...) to data - estimate parameters
dy
dt= f(t; !)
t
y
y(t) = g(t|y(0), !)
Monday, April 26, 2010
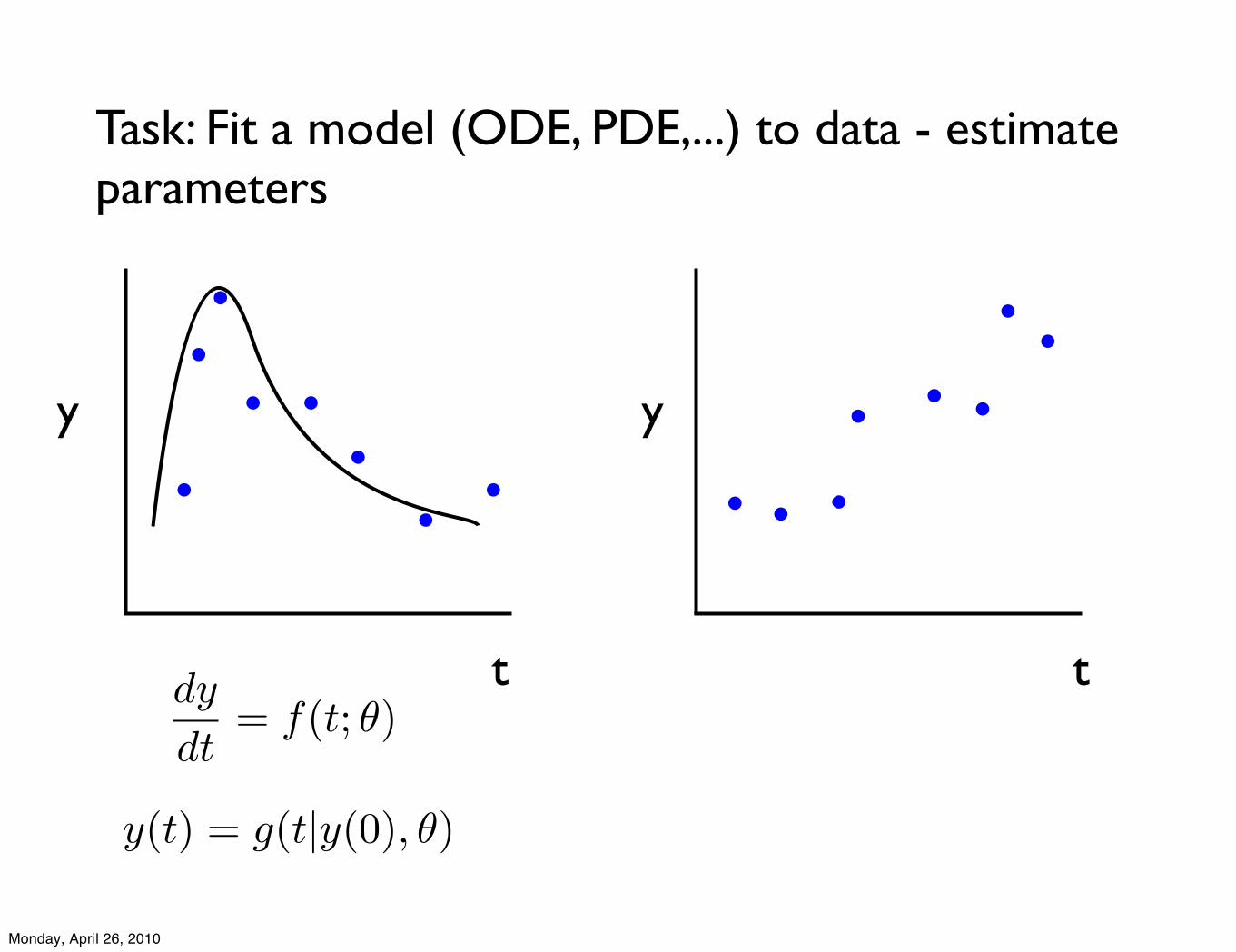
Task: Fit a model (ODE, PDE,...) to data - estimate parameters
dy
dt= f(t; !)
t
y y
t
y(t) = g(t|y(0), !)
Monday, April 26, 2010
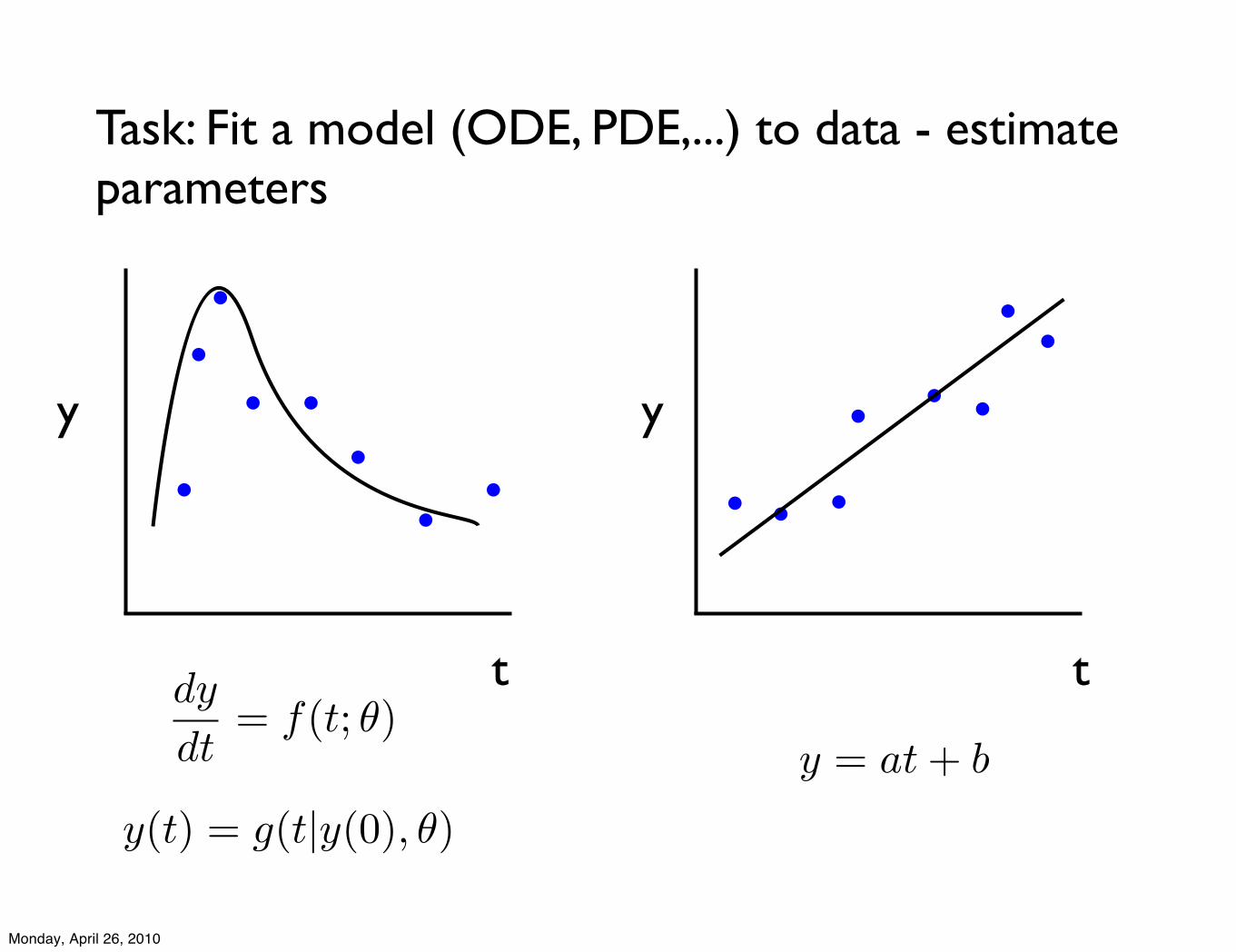
Task: Fit a model (ODE, PDE,...) to data - estimate parameters
dy
dt= f(t; !)
t
y y
t
y = at + b
y(t) = g(t|y(0), !)
Monday, April 26, 2010

Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Questions:
Monday, April 26, 2010

Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Questions: What algorithm to use?
Monday, April 26, 2010

Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Questions: What algorithm to use?
How good is the fit?
Monday, April 26, 2010

Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Questions:
Is there a better model?
What algorithm to use?
How good is the fit?
Monday, April 26, 2010

Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Questions:
Is there a better model?
What algorithm to use?
Sensitivity?
How good is the fit?
Monday, April 26, 2010

Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Questions:
Is there a better model?
What algorithm to use?
Answer: Use Bayesian inference and MCMC
Sensitivity?
How good is the fit?
Monday, April 26, 2010

Task: Fit a model (ODE, PDE,...) to data - estimate parameters
Questions:
Is there a better model?
What algorithm to use?
Sensitivity?
How good is the fit?
Answer: Invert vs. infer
Monday, April 26, 2010

Bayesian inference
Frequentist: Probability is a frequency (of a random variable)
Monday, April 26, 2010

Bayesian inference
Frequentist: Probability is a frequency (of a random variable)
Bayesian: Probability is a measure of uncertainty
Monday, April 26, 2010

Bayesian inference
Frequentist: Probability is a frequency (of a random variable)
Bayesian: Probability is a measure of uncertainty
Jaynes: Probability is extended logic
Monday, April 26, 2010

Bayesian inference
Models and parameters have probabilities
Anything can be assigned a probability
Makes everything straightforward
Monday, April 26, 2010

D = Data θ = Parameters
Parameter estimationy(θ,t): solution
i.e. Maximum likelihood estimation
θ that maximizes likelihood
!
i
(Di ! yi(!))2e.g. Minimize mean square error
P (D|!) ! exp
!"
i
" (Di " yi(!))2
2"2
#
Monday, April 26, 2010

D = Data θ = Parameters
Parameter estimationy(θ,t): solution
i.e. Maximum likelihood estimation
θ that maximizes likelihood
!
i
(Di ! yi(!))2e.g. Minimize mean square error
P (D|!) ! exp
!"
i
" (Di " yi(!))2
2"2
#
Monday, April 26, 2010

Statistics
But in frequentist statistics models and parameters cannot have probabilities
Confidence intervals of a parameter are with respect to sampling errors
“Natural” thing to do is to find the probability distribution for a model or parameters
Monday, April 26, 2010

Bayes theorem
P (!, D) = P (!|D)P (D) = P (D|!)P (!)
Monday, April 26, 2010

Bayes theorem
P (!|D) =P (D|!)P (!)
P (D)
P (!, D) = P (!|D)P (D) = P (D|!)P (!)
Monday, April 26, 2010

Bayes theorem
PriorP (!|D) =
P (D|!)P (!)P (D)
P (!, D) = P (!|D)P (D) = P (D|!)P (!)
Monday, April 26, 2010
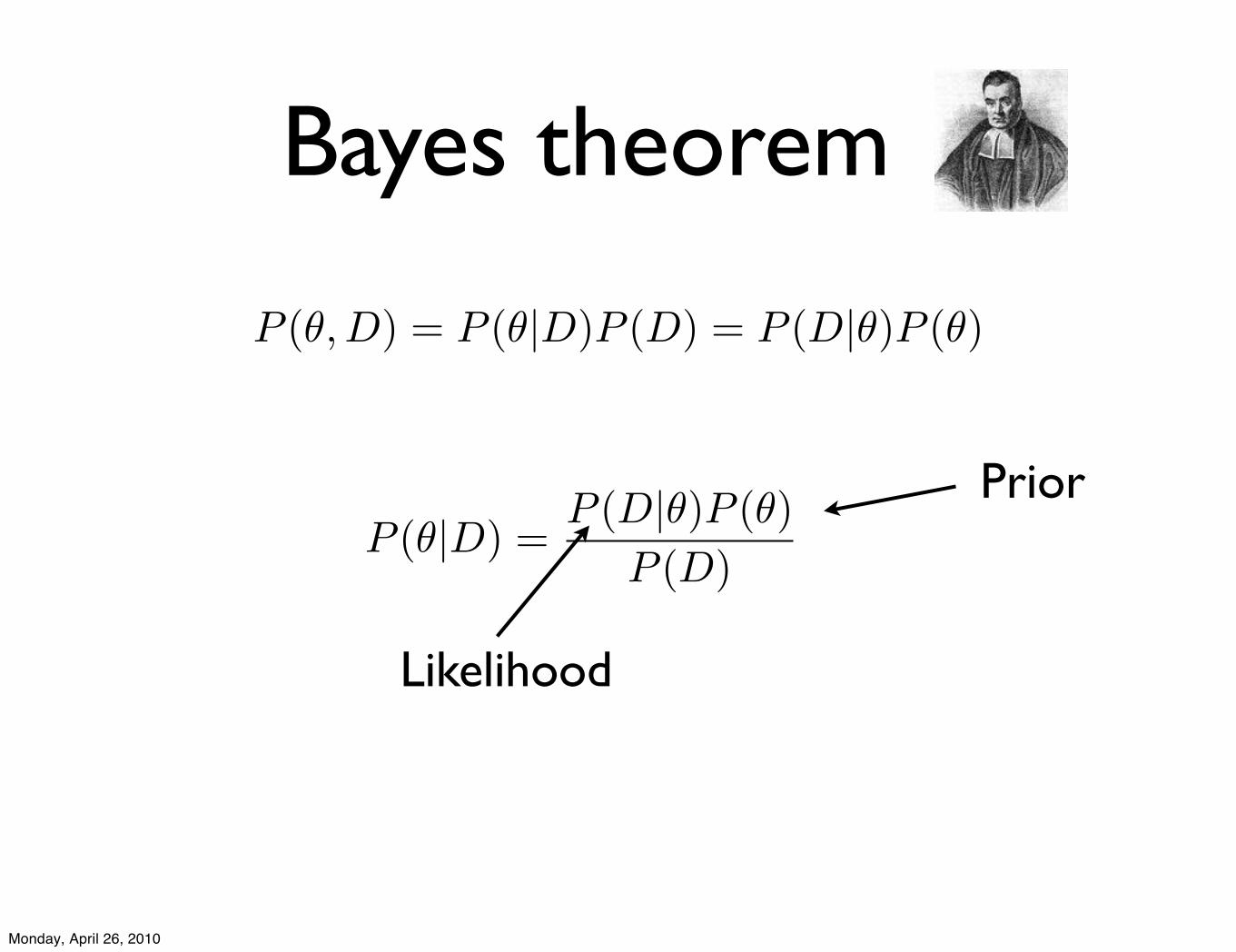
Bayes theorem
Prior
Likelihood
P (!|D) =P (D|!)P (!)
P (D)
P (!, D) = P (!|D)P (D) = P (D|!)P (!)
Monday, April 26, 2010
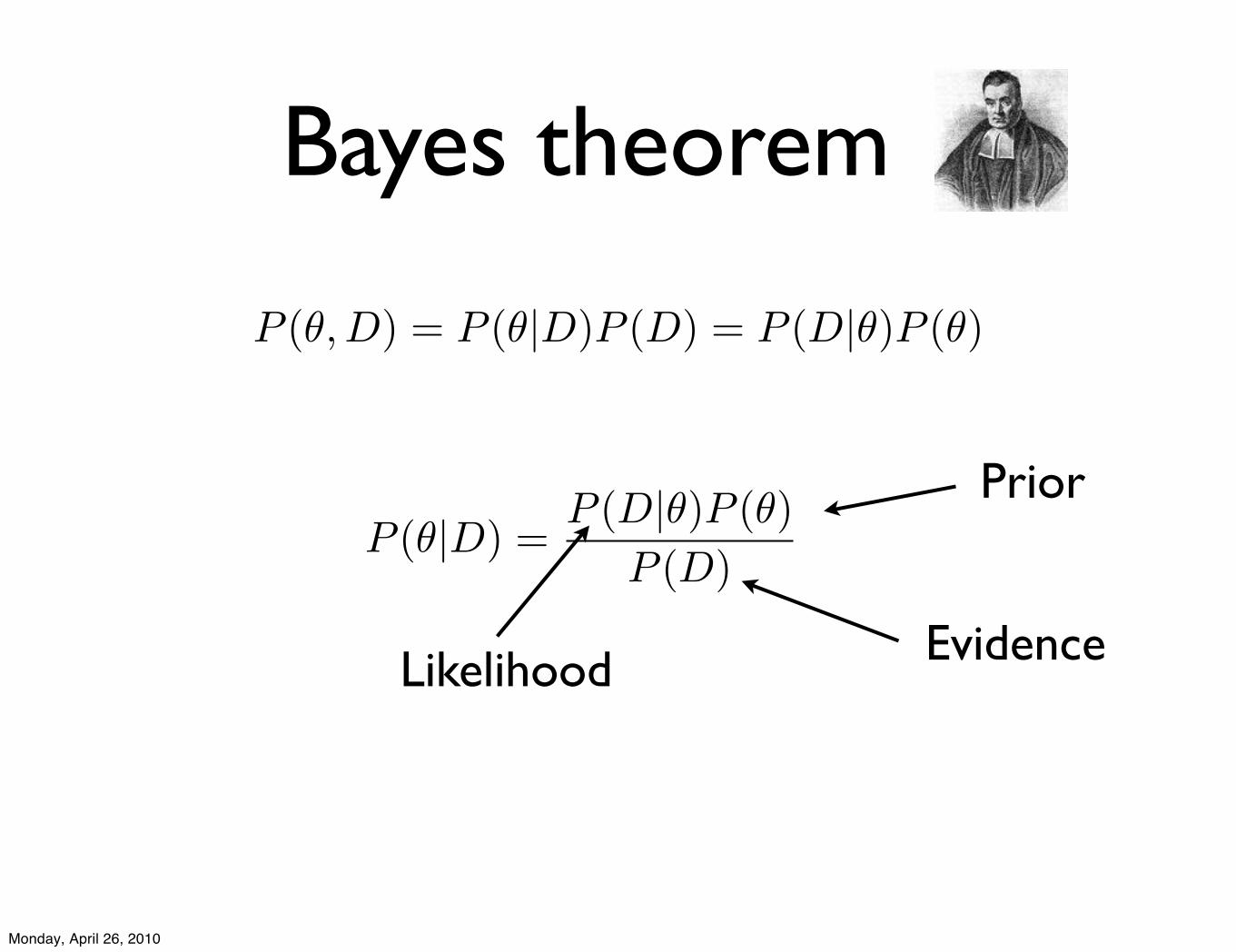
Bayes theorem
Prior
Likelihood
P (!|D) =P (D|!)P (!)
P (D)
Evidence
P (!, D) = P (!|D)P (D) = P (D|!)P (!)
Monday, April 26, 2010
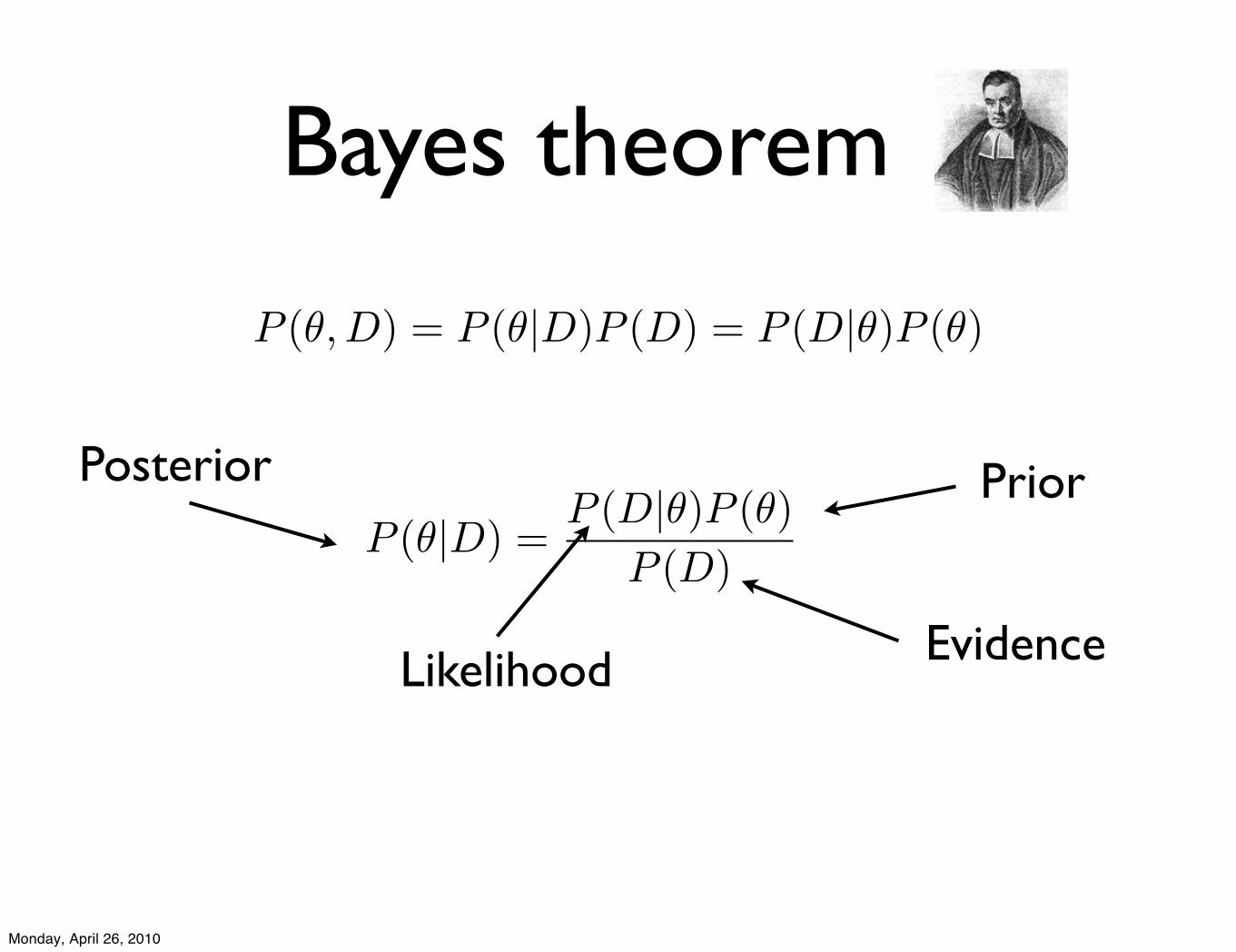
Bayes theorem
PriorPosterior
Likelihood
P (!|D) =P (D|!)P (!)
P (D)
Evidence
P (!, D) = P (!|D)P (D) = P (D|!)P (!)
Monday, April 26, 2010

Bayes theorem
Bayesian inference reduces statistics to one equation
PriorPosterior
Likelihood
P (!|D) =P (D|!)P (!)
P (D)
Evidence
P (!, D) = P (!|D)P (D) = P (D|!)P (!)
Monday, April 26, 2010

D = Data θ = Parameters
Parameter estimation
P (!|D) =P (D|!)P (!)
P (D)
P (!|D) ! P (D|!)P (!)
P (D) =!
P (D|!)P (!)d!
y(θ,t): solution
Monday, April 26, 2010

D = Data θ = Parameters
Parameter estimation
P (!|D) =P (D|!)P (!)
P (D)
P (!|D) ! P (D|!)P (!)
P (D) =!
P (D|!)P (!)d!
! exp
!"
i
" (Di " yi(!))2
2"2
#y(θ,t): solution
Monday, April 26, 2010

D = Data θ = Parameters
Parameter estimation
P (!|D) =P (D|!)P (!)
P (D)
P (!|D) ! P (D|!)P (!)
P (D) =!
P (D|!)P (!)d!
! exp
!"
i
" (Di " yi(!))2
2"2
#y(θ,t): solution
Probability of parameter given the data
Monday, April 26, 2010
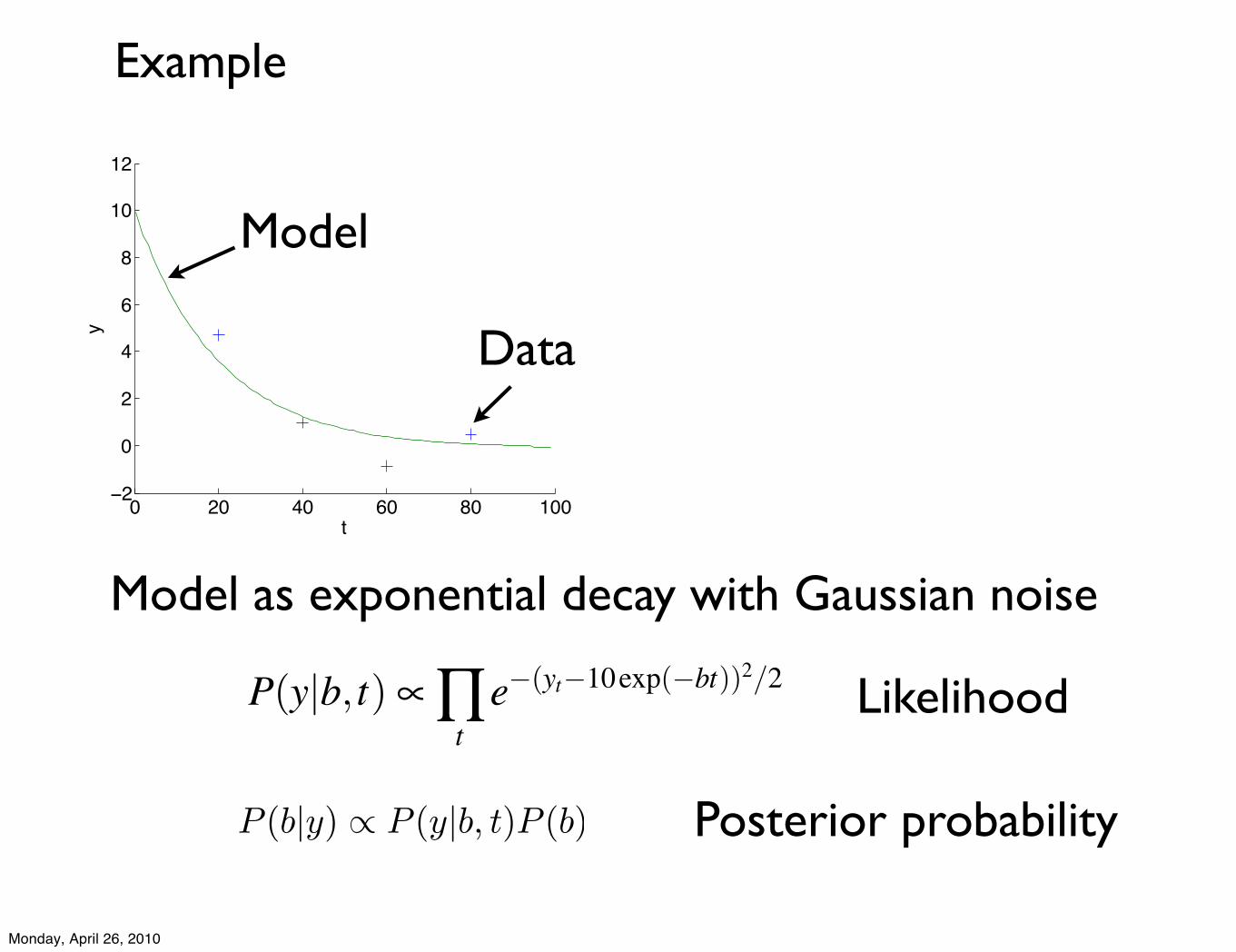
0 20 40 60 80 100−2
0
2
4
6
8
10
12
0 20 40 60 80 100−2
0
2
4
6
8
10
12
t
y
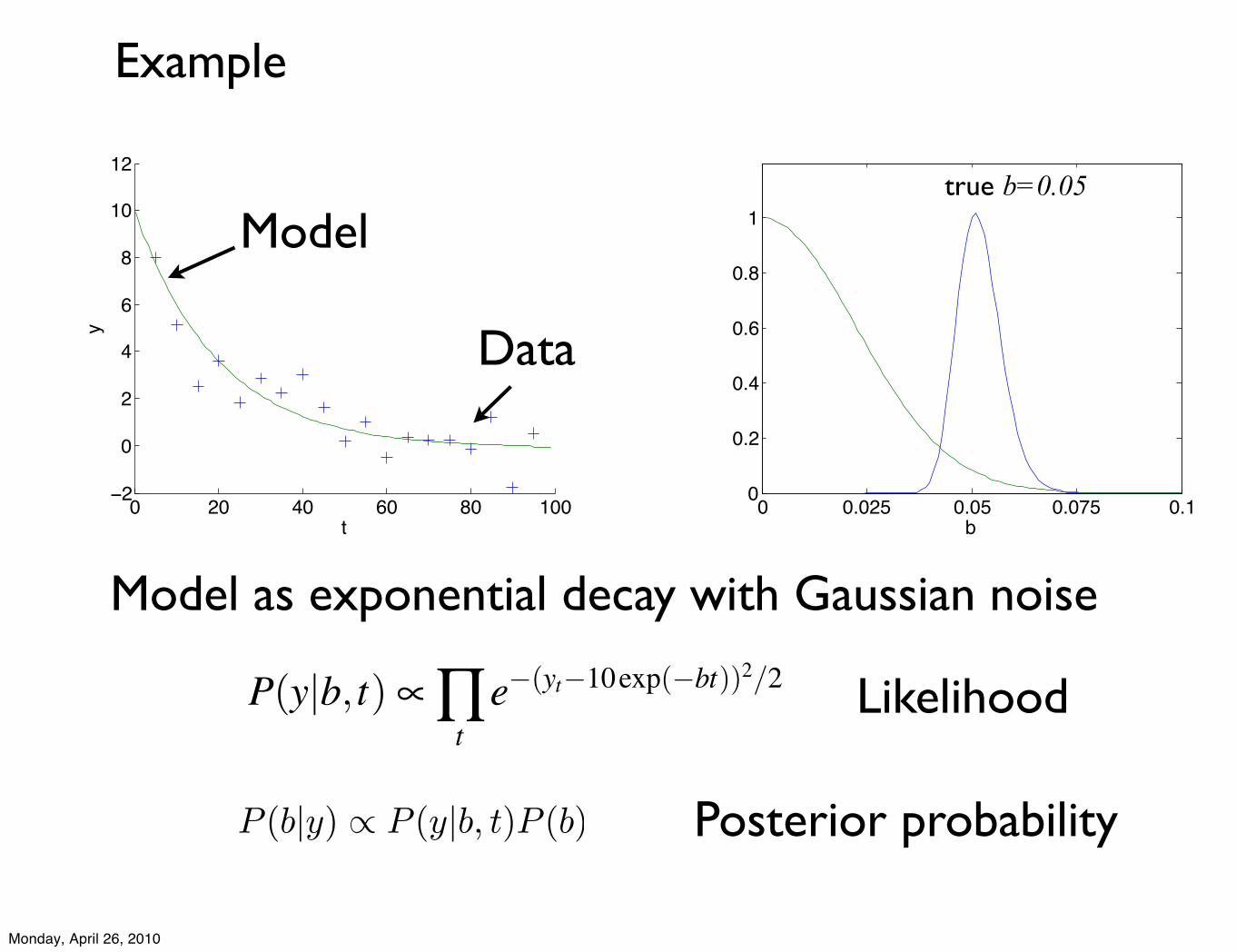
Model as exponential decay with Gaussian noise
Posterior probability
Likelihood
Model
Data
P(y|b, t) ! "t
e!(yt!10exp(!bt))2/2
P (b|y) ! P (y|b, t)P (b)
Example
Monday, April 26, 2010
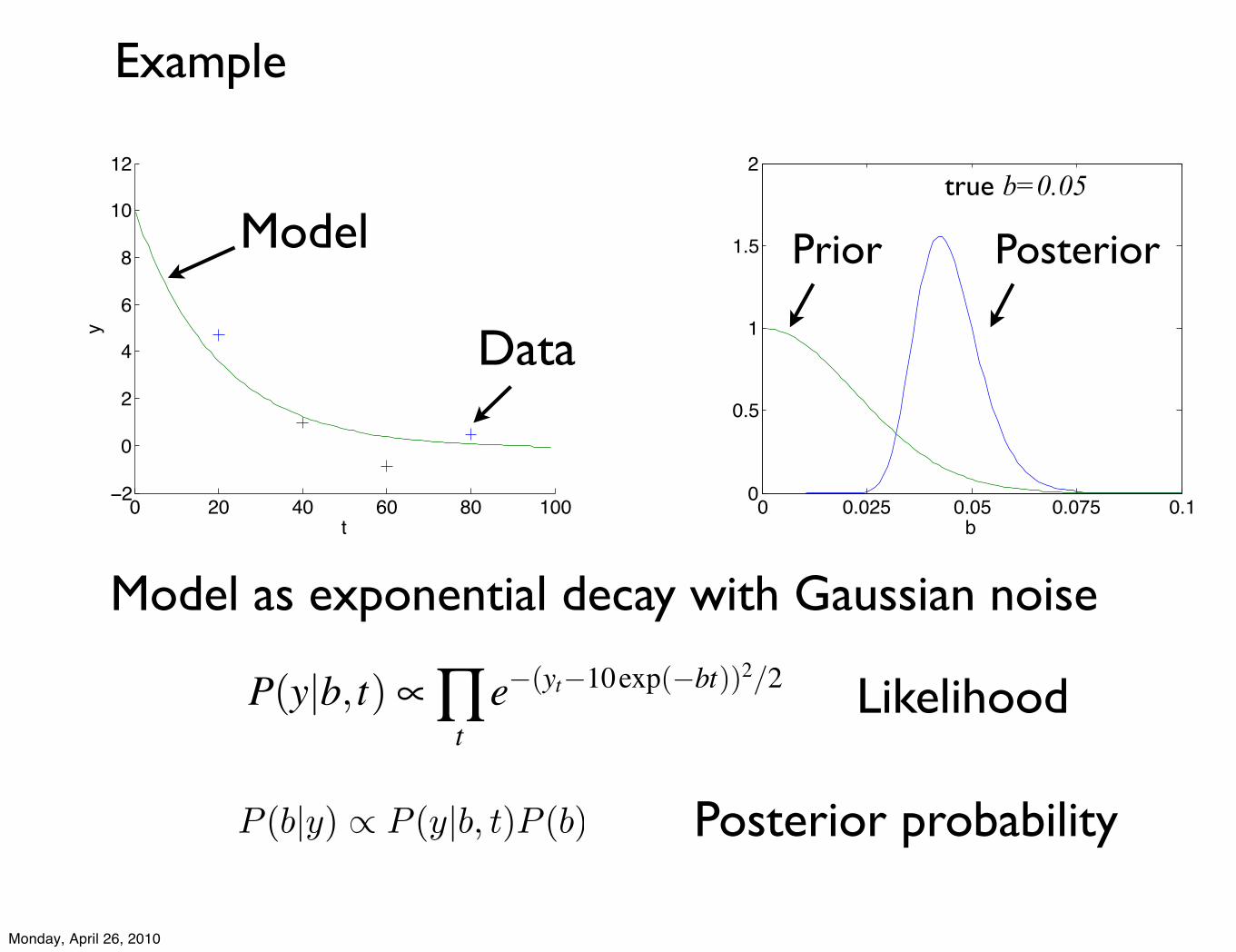
0 0.025 0.05 0.075 0.10
0.5
1
1.5
2
b0 20 40 60 80 100−2
0
2
4
6
8
10
12
0 20 40 60 80 100−2
0
2
4
6
8
10
12
t
y
Model as exponential decay with Gaussian noise
Posterior probability
Likelihood
true b=0.05
Model
Data
Prior Posterior
P(y|b, t) ! "t
e!(yt!10exp(!bt))2/2
P (b|y) ! P (y|b, t)P (b)
Example
Monday, April 26, 2010
0 20 40 60 80 100−2
0
2
4
6
8
10
12
0 20 40 60 80 100−2
0
2
4
6
8
10
12
t
y
0 0.025 0.05 0.075 0.10
0.2
0.4
0.6
0.8
1
b
Model as exponential decay with Gaussian noise
Posterior probability
Likelihood
true b=0.05
Model
Data
P(y|b, t) ! "t
e!(yt!10exp(!bt))2/2
P (b|y) ! P (y|b, t)P (b)
Example
Monday, April 26, 2010

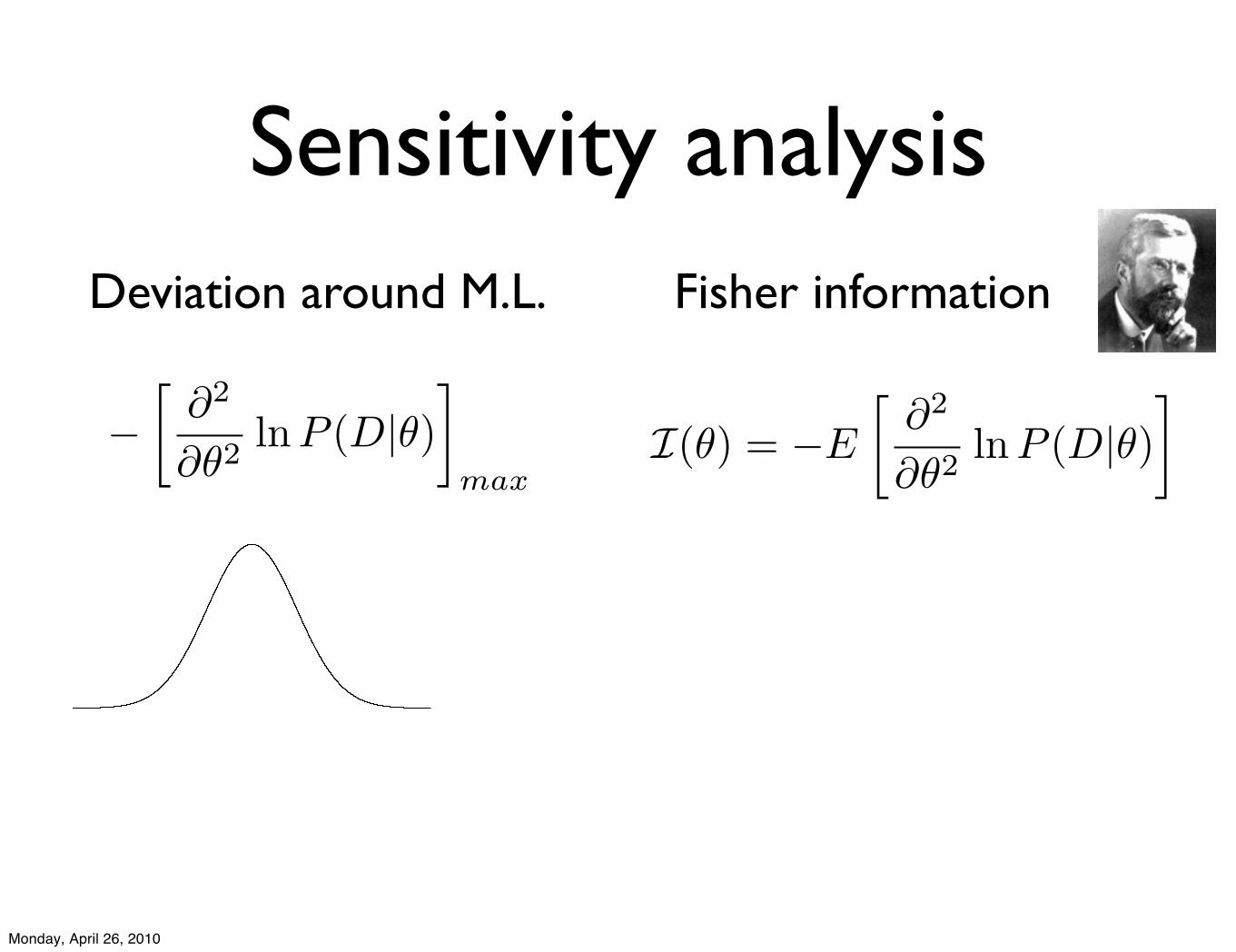
Sensitivity analysis
!!
!2
!"2lnP (D|")
"
max
Deviation around M.L. Fisher information
I(!) = !E
!"2
"!2lnP (D|!)
"
Monday, April 26, 2010
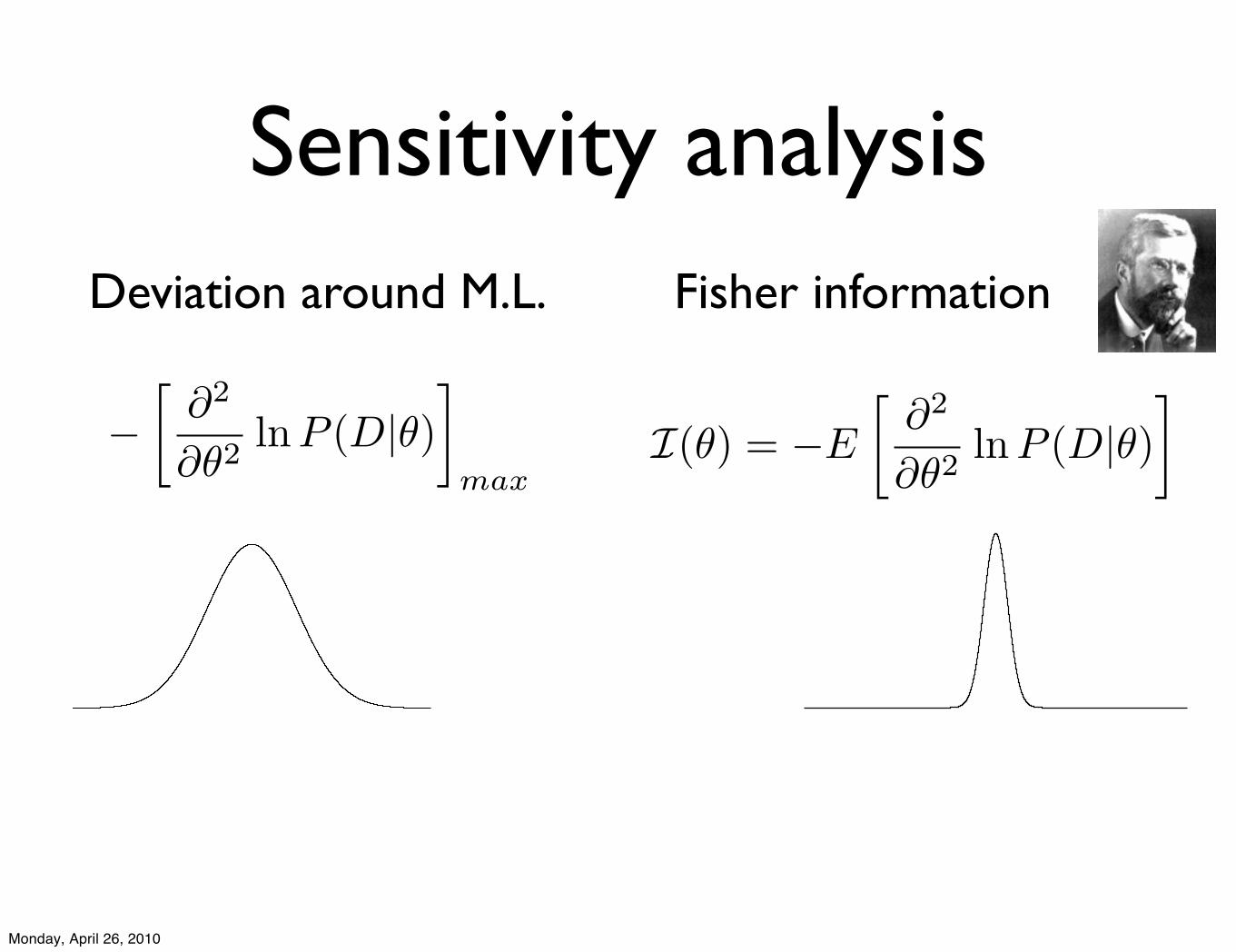
Sensitivity analysis
!!
!2
!"2lnP (D|")
"
max
Deviation around M.L. Fisher information
I(!) = !E
!"2
"!2lnP (D|!)
"
Monday, April 26, 2010
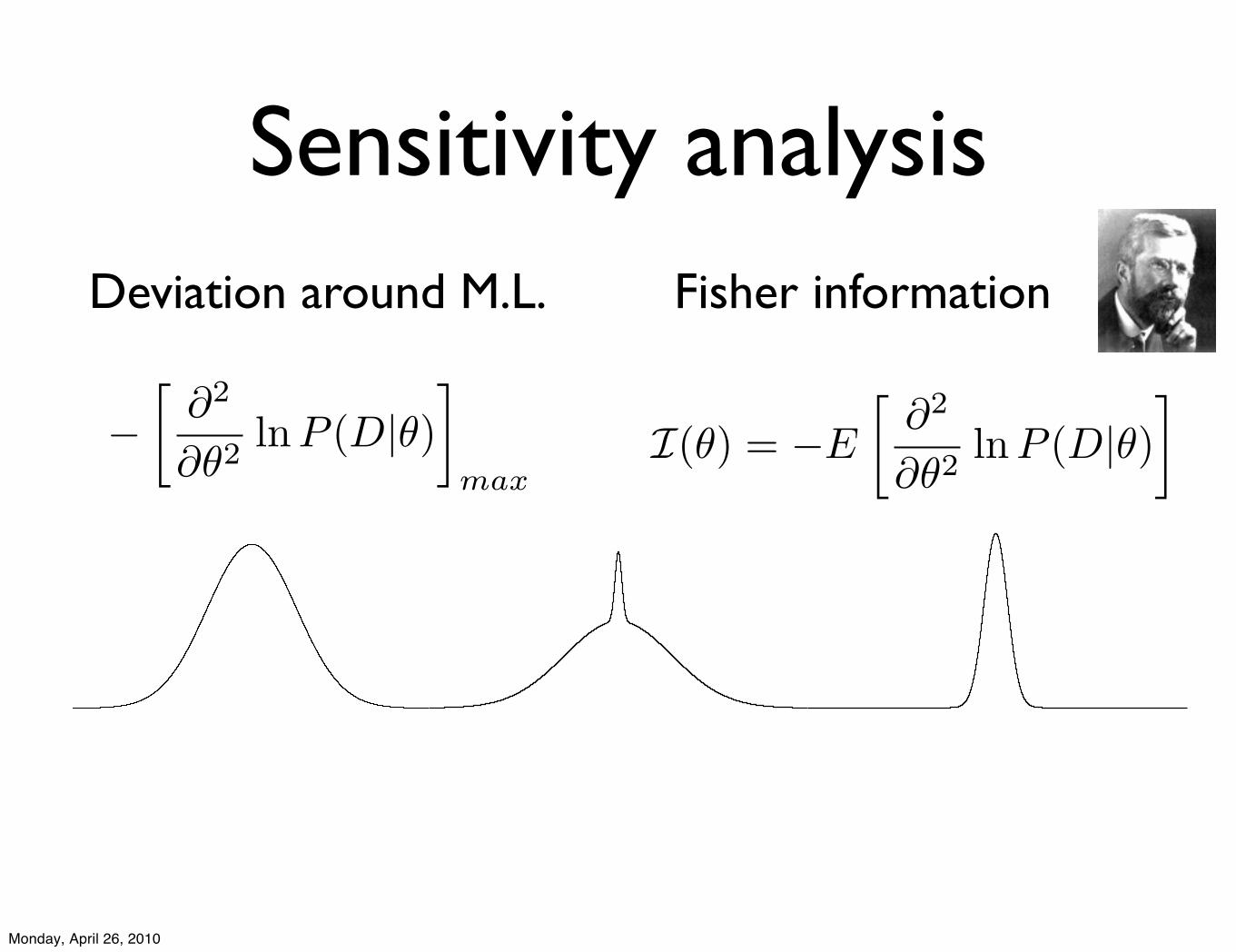
Sensitivity analysis
!!
!2
!"2lnP (D|")
"
max
Deviation around M.L. Fisher information
I(!) = !E
!"2
"!2lnP (D|!)
"
Monday, April 26, 2010
Sensitivity analysis
!!
!2
!"2lnP (D|")
"
max
Deviation around M.L. Fisher information
I(!) = !E
!"2
"!2lnP (D|!)
"
Monday, April 26, 2010
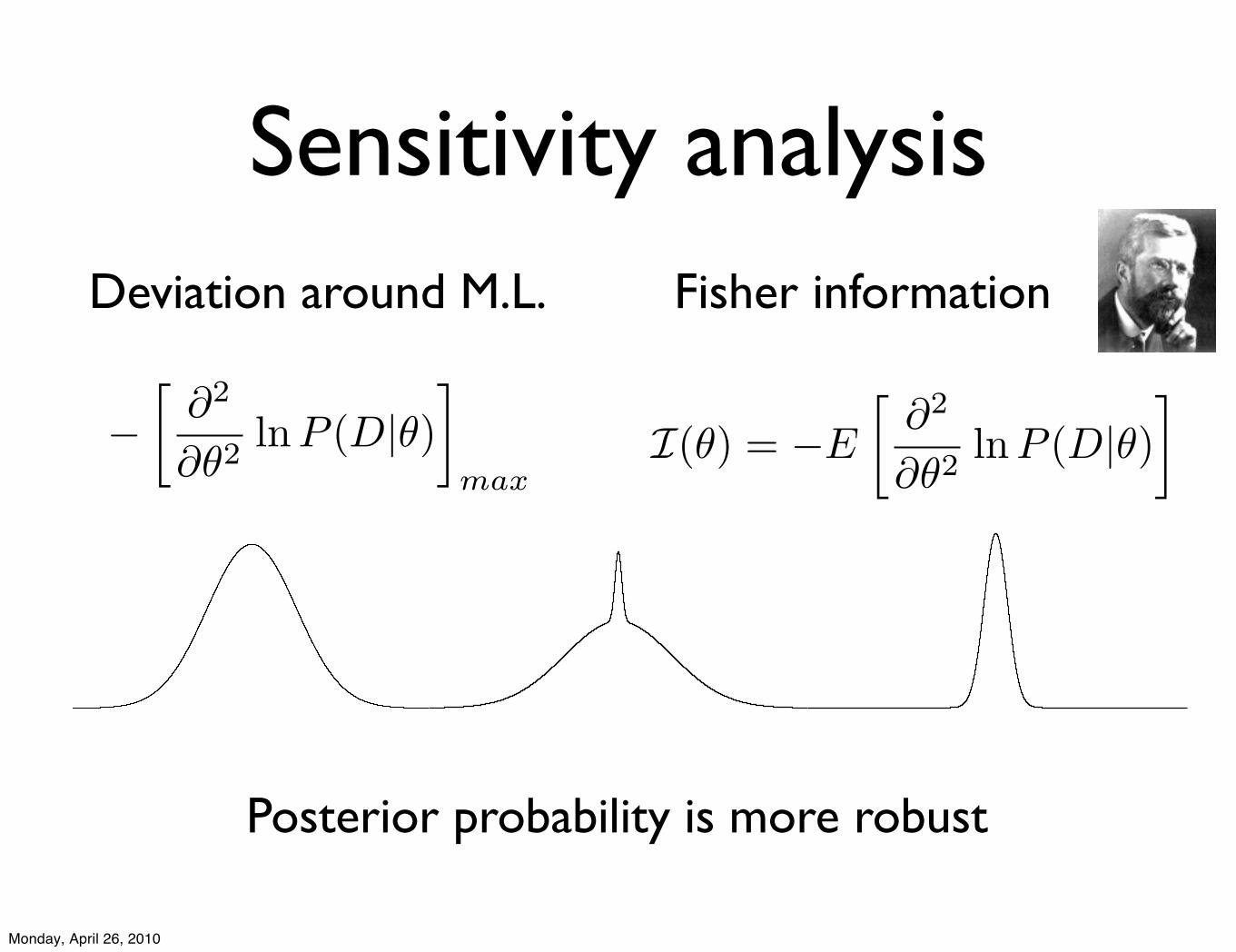
Sensitivity analysis
!!
!2
!"2lnP (D|")
"
max
Deviation around M.L.
Posterior probability is more robust
Fisher information
I(!) = !E
!"2
"!2lnP (D|!)
"
Monday, April 26, 2010

Model comparison
Given some data, what is the best model?
Fit the data and penalize extra parameters
Monday, April 26, 2010

Model comparison- Two competing models M1 and M2
where
P (M1|D) =P (D|M1)P (M1)
P (D)P (M2|D) =
P (D|M2)P (M2)P (D)
P (D|M) =!
P (D|M, !)P (!|M)d!
M1 : y! = f1(y, !)
M2 : y! = f2(y, !)
Monday, April 26, 2010

Model comparison- Two competing models M1 and M2
where
P (M1|D) =P (D|M1)P (M1)
P (D)P (M2|D) =
P (D|M2)P (M2)P (D)
P (D|M) =!
P (D|M, !)P (!|M)d!
P (M1|D)P (M2|D)
=P (D|M1)P (D|M2)
P (M1)P (M2)
odds
M1 : y! = f1(y, !)
M2 : y! = f2(y, !)
Monday, April 26, 2010

Model comparison- Two competing models M1 and M2
where
Bayes factor
P (M1|D) =P (D|M1)P (M1)
P (D)P (M2|D) =
P (D|M2)P (M2)P (D)
P (D|M) =!
P (D|M, !)P (!|M)d!
P (M1|D)P (M2|D)
=P (D|M1)P (D|M2)
P (M1)P (M2)
odds
M1 : y! = f1(y, !)
M2 : y! = f2(y, !)
Monday, April 26, 2010

Model comparison- Two competing models M1 and M2
where
P (M1|D) =P (D|M1)P (M1)
P (D)P (M2|D) =
P (D|M2)P (M2)P (D)
P (D|M) =!
P (D|M, !)P (!|M)d!
P (M1|D)P (M2|D)
=P (D|M1)P (D|M2)
P (M1)P (M2)
odds
M1 : y! = f1(y, !)
M2 : y! = f2(y, !)
Monday, April 26, 2010

Model comparison- Two competing models M1 and M2
where
P (M1|D) =P (D|M1)P (M1)
P (D)P (M2|D) =
P (D|M2)P (M2)P (D)
P (D|M) =!
P (D|M, !)P (!|M)d!
P (M1|D)P (M2|D)
=P (D|M1)P (D|M2)
P (M1)P (M2)
odds
M1 : y! = f1(y, !)
M2 : y! = f2(y, !)
log odds log P (D|M1)! log P (D|M2)
Monday, April 26, 2010

Likelihood integrated over parameters
P (D|M) =!
P (D|M, !)P (!|M)d!
e.g. for 0 < θ < σP (!|M) =1"
P (D|M) =1!
! !
0P (D|M, ")d"∴
Prior
Monday, April 26, 2010
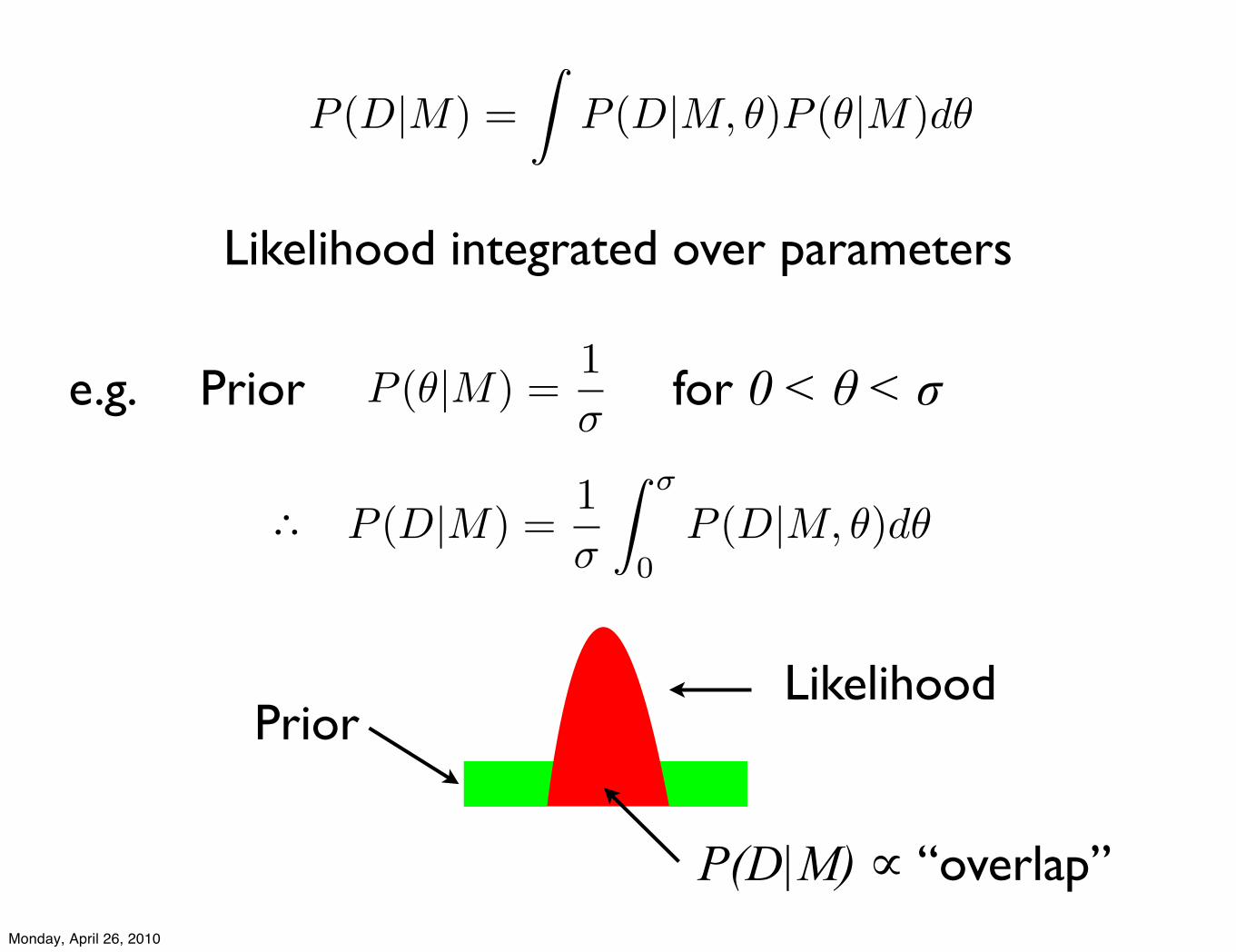
Likelihood integrated over parameters
P (D|M) =!
P (D|M, !)P (!|M)d!
e.g. for 0 < θ < σP (!|M) =1"
P (D|M) =1!
! !
0P (D|M, ")d"∴
Prior
P(D|M) ∝ “overlap”
LikelihoodPrior
Monday, April 26, 2010

for k parametersP (D|M) ! 1!k
! !
0P (D|M, ")dk"
! !
0P (D|M, !)dk! = L"k
Maximum likelihood
Monday, April 26, 2010
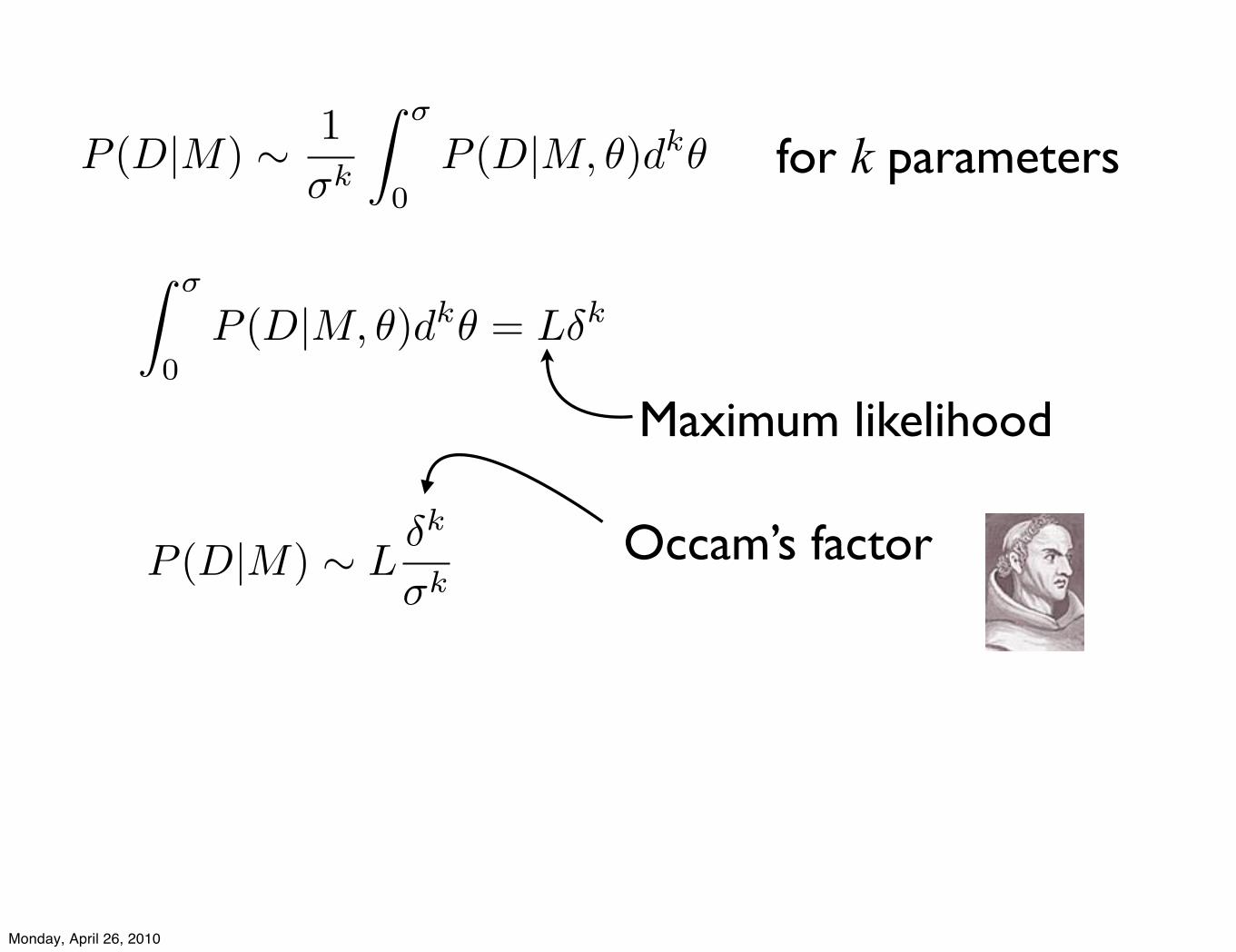
for k parametersP (D|M) ! 1!k
! !
0P (D|M, ")dk"
! !
0P (D|M, !)dk! = L"k
P (D|M) ! L!k
"kOccam’s factor
Maximum likelihood
Monday, April 26, 2010
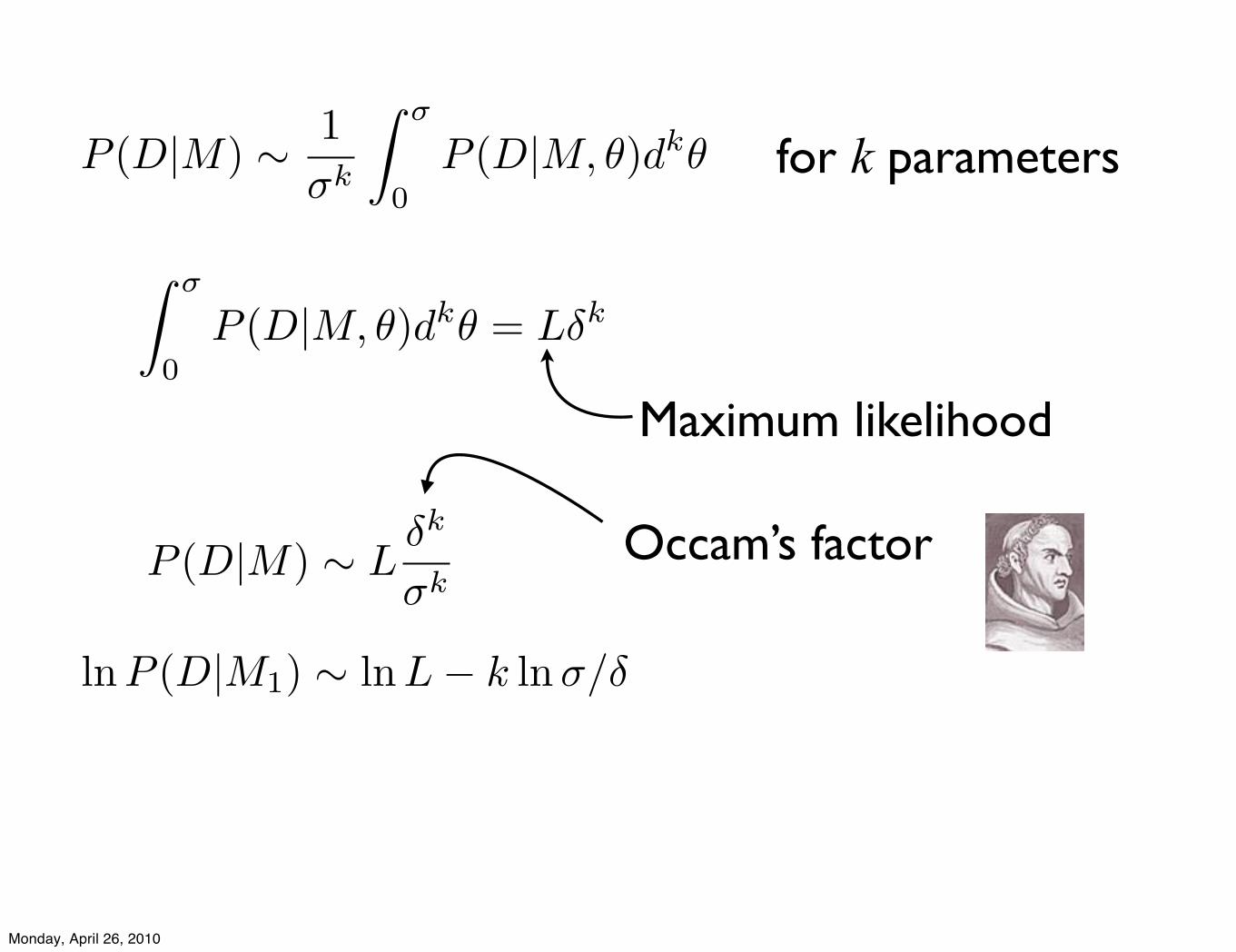
for k parametersP (D|M) ! 1!k
! !
0P (D|M, ")dk"
lnP (D|M1) ! lnL" k ln!/"
! !
0P (D|M, !)dk! = L"k
P (D|M) ! L!k
"kOccam’s factor
Maximum likelihood
Monday, April 26, 2010
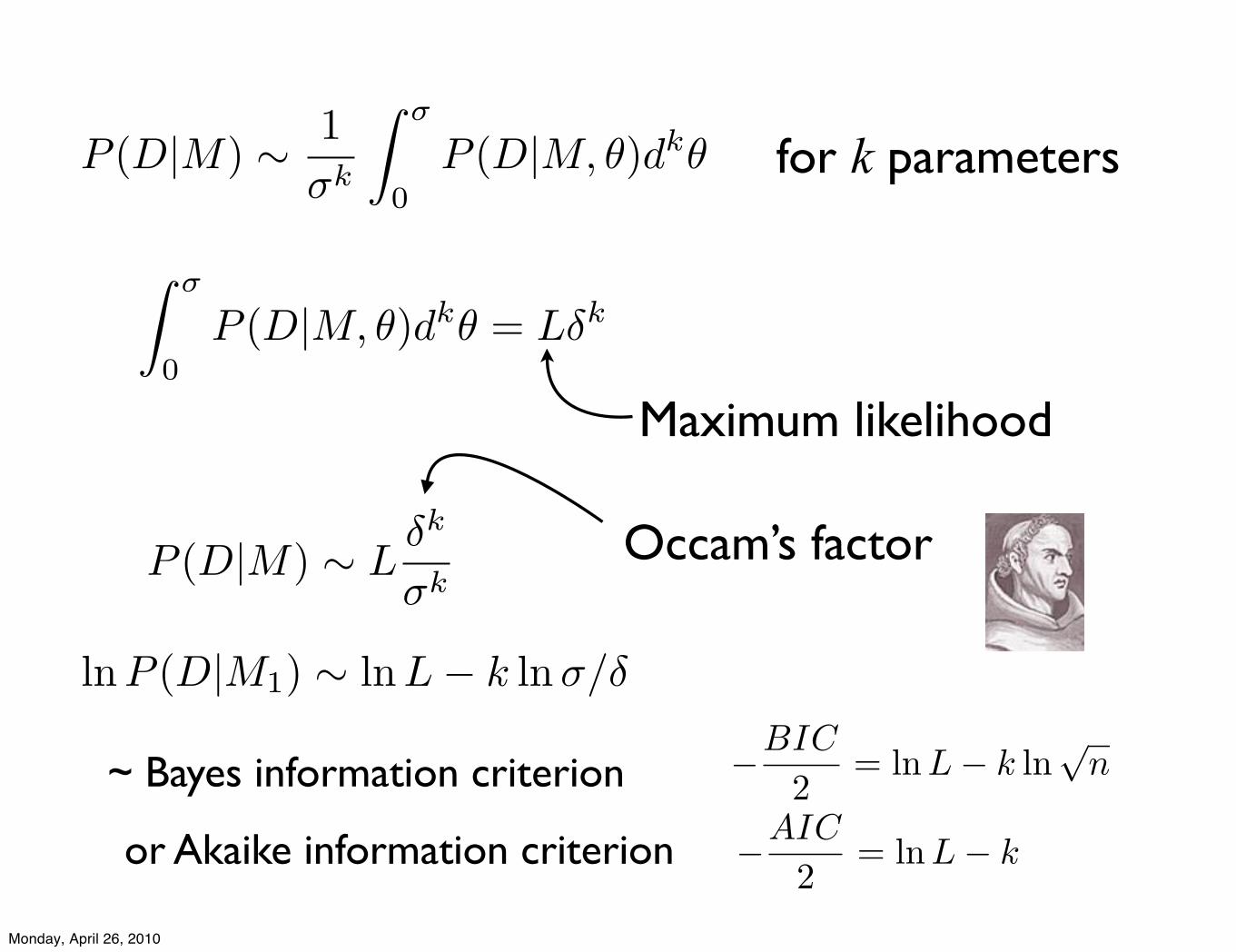
for k parametersP (D|M) ! 1!k
! !
0P (D|M, ")dk"
lnP (D|M1) ! lnL" k ln!/"
! !
0P (D|M, !)dk! = L"k
P (D|M) ! L!k
"kOccam’s factor
Maximum likelihood
~ Bayes information criterion !BIC
2= ln L! k ln
"n
or Akaike information criterion !AIC
2= lnL! k
Monday, April 26, 2010

AIC and BIC: penalize the log of the likelihood with the number of parameters
Caveat: These approximations generally only valid if likelihood function near normal and peaked
Real criterion: maximize likelihood and the overlap of likelihood with prior
e.g. constants are not penalized
Monday, April 26, 2010

Priors
• Main complaint about Bayesian framework is the necessity of a prior
• All modeling is biased by prior information
• Assuming modeling is possible is already a prior
• Bayesian perspective just makes this systematic and consistent
Monday, April 26, 2010

Curse of dimensionality
k parameters sampled at p points is pk
100 parameters at 10 points is a googol
Consider a model with k parameters
Monday, April 26, 2010

Curse of dimensionality
k parameters sampled at p points is pk
100 parameters at 10 points is a googol >>
Consider a model with k parameters
Monday, April 26, 2010

Curse of dimensionality
k parameters sampled at p points is pk
100 parameters at 10 points is a googol >>
Modeling is impossible without priors
Consider a model with k parameters
Monday, April 26, 2010

Markov Chain Monte Carlo
MCMC method is the de facto method to compute posteriors and do model comparison
Combined with parallel tempering can do parameter estimation and model comparison in one computation
Probabilistic way to compute integrals
Monday, April 26, 2010

MCMC: Metropolis algorithm
1. Start with θ, guess θ´
3. Accept with probability min(r,1)
2. Compute
4. Repeat
r =P (!!|D)P (!|D)
=P (D|!!)P (!!)P (D|!)P (!)
Monday, April 26, 2010

MCMC: Metropolis algorithm
1. Start with θ, guess θ´
3. Accept with probability min(r,1)
2. Compute
4. Repeat
r =P (!!|D)P (!|D)
=P (D|!!)P (!!)P (D|!)P (!)
Time series converges to posterior
Monday, April 26, 2010
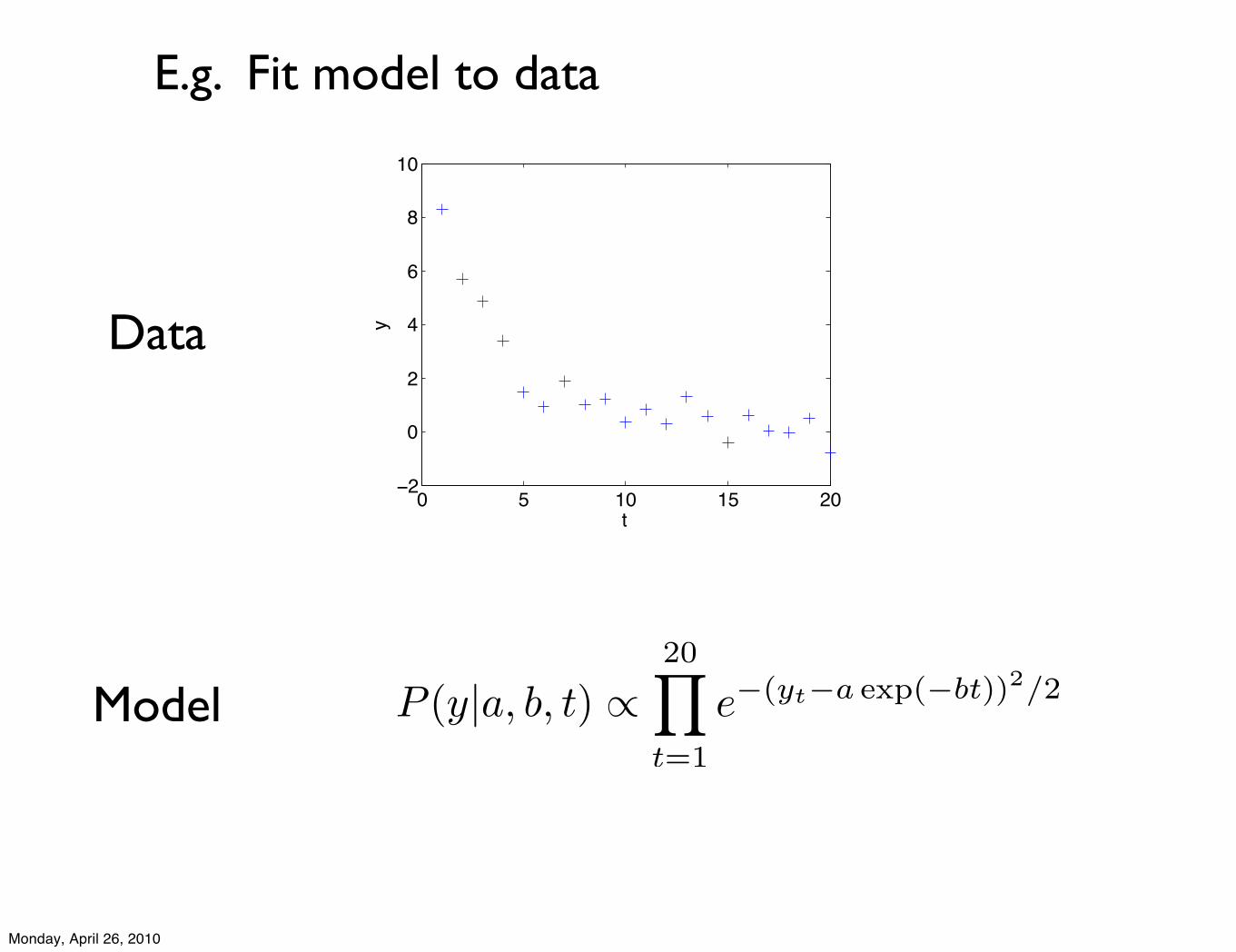
E.g. Fit model to data
0 5 10 15 20−2
0
2
4
6
8
10
t
y
P (y|a, b, t) !20!
t=1
e!(yt!a exp(!bt))2/2Model
Data
Monday, April 26, 2010

0 200 400 600 800 10000.2
0.4
0.6
0.8
1
1.2
Iterations
bP (y|a, b, t) !
20!
t=1
e!(yt!a exp(!bt))2/2
0 200 400 600 800 10006
8
10
12
14
16
Iterations
a
0 0.2 0.4 0.6 0.80
100
200
300
400
500
600
700
800
b5 10 15 200
50
100
150
200
250
300
350
400
a
0.33±0.06 11.4±1.7
Monday, April 26, 2010
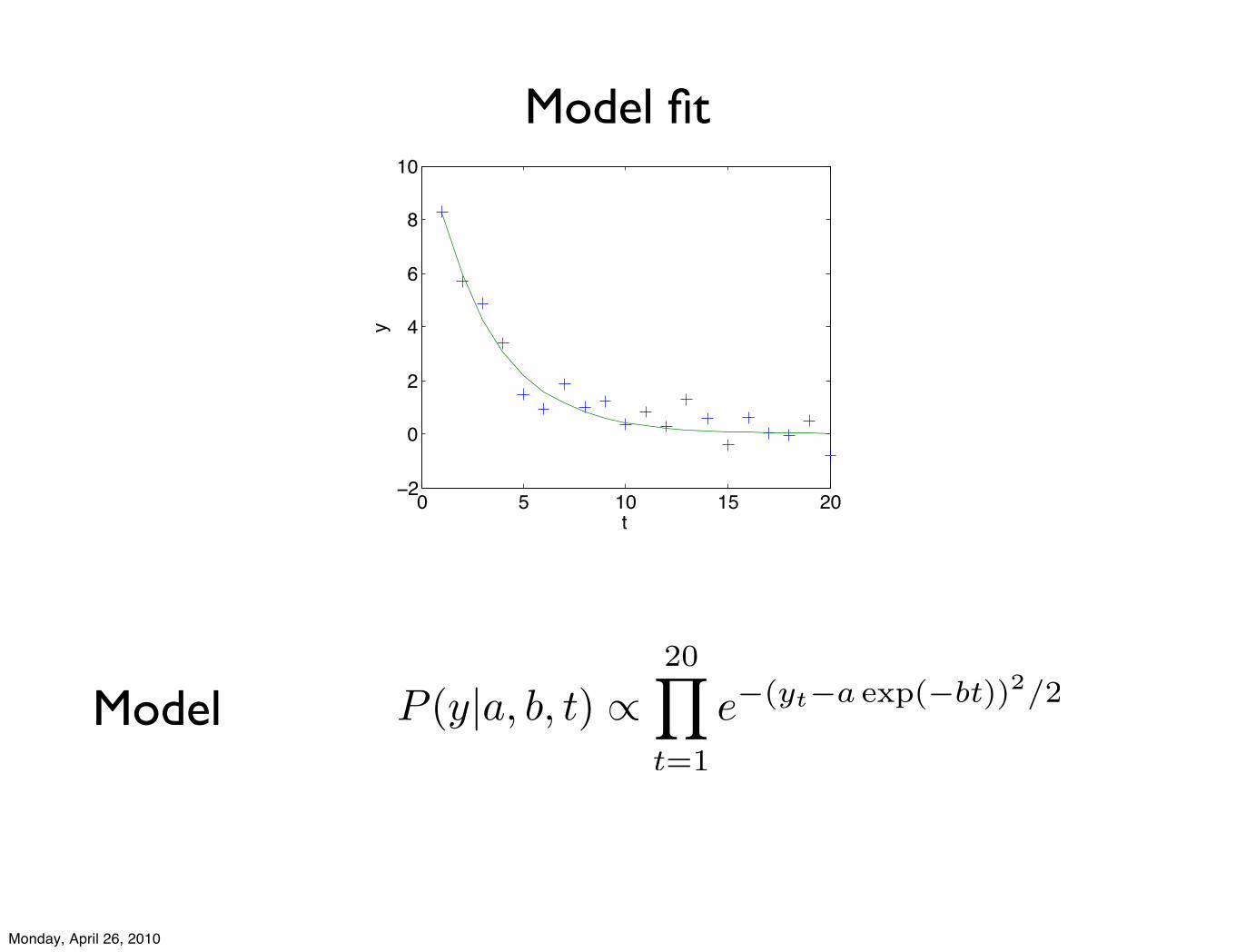
0 5 10 15 20−2
0
2
4
6
8
10
t
y
P (y|a, b, t) !20!
t=1
e!(yt!a exp(!bt))2/2Model
Model fit
Monday, April 26, 2010

Posterior is stationary distribution of MCMC
since if θ is in the posterior, so is θ´
Transition probability P (!!|!) = min!1,
P (!!|D)P (!|D)
"
=!
min"1,
P (!|D)P (!!|D)
#P (!!|D)d!
!P (!!|!)P (!|D)d!
= P (!!|D)!
P (!|!!)d! = P (!!|D)
Monday, April 26, 2010

Parallel temperingIntroduce inverse temperature β
0 ! ! ! 1
Run at multiple β and swap randomly
Smaller β runs search more of parameter space
Model comparison in same run since
!("|D) ! p(D|")!P (D)
ln p(D|M) =! 1
0!ln p(D|!,M)"!d"
Monday, April 26, 2010

Applications
1. Cell state transitions in embryonic stem cells
2. The effect of insulin on the free fatty acidsin the blood
Monday, April 26, 2010
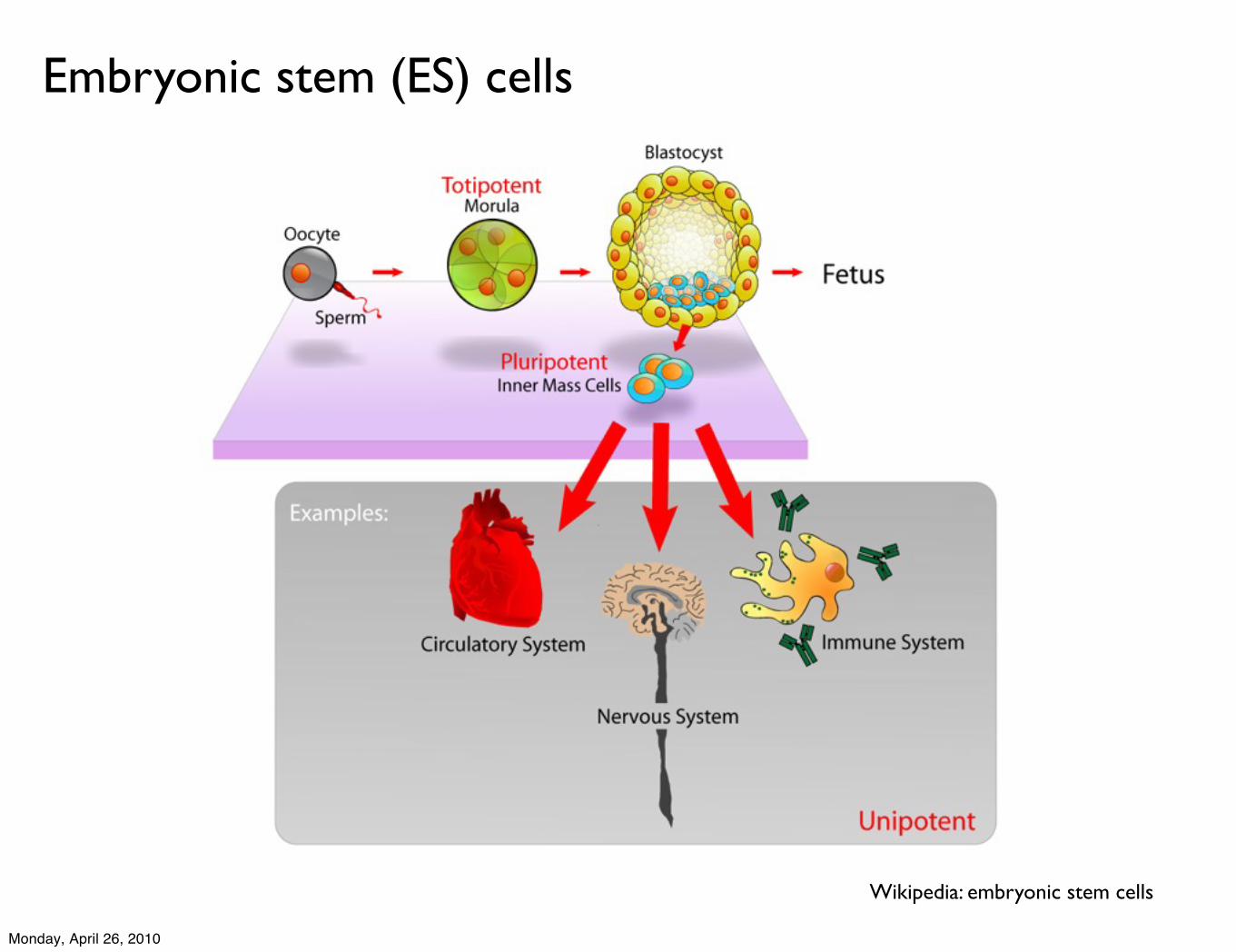
Embryonic stem (ES) cells
Wikipedia: embryonic stem cells
Monday, April 26, 2010
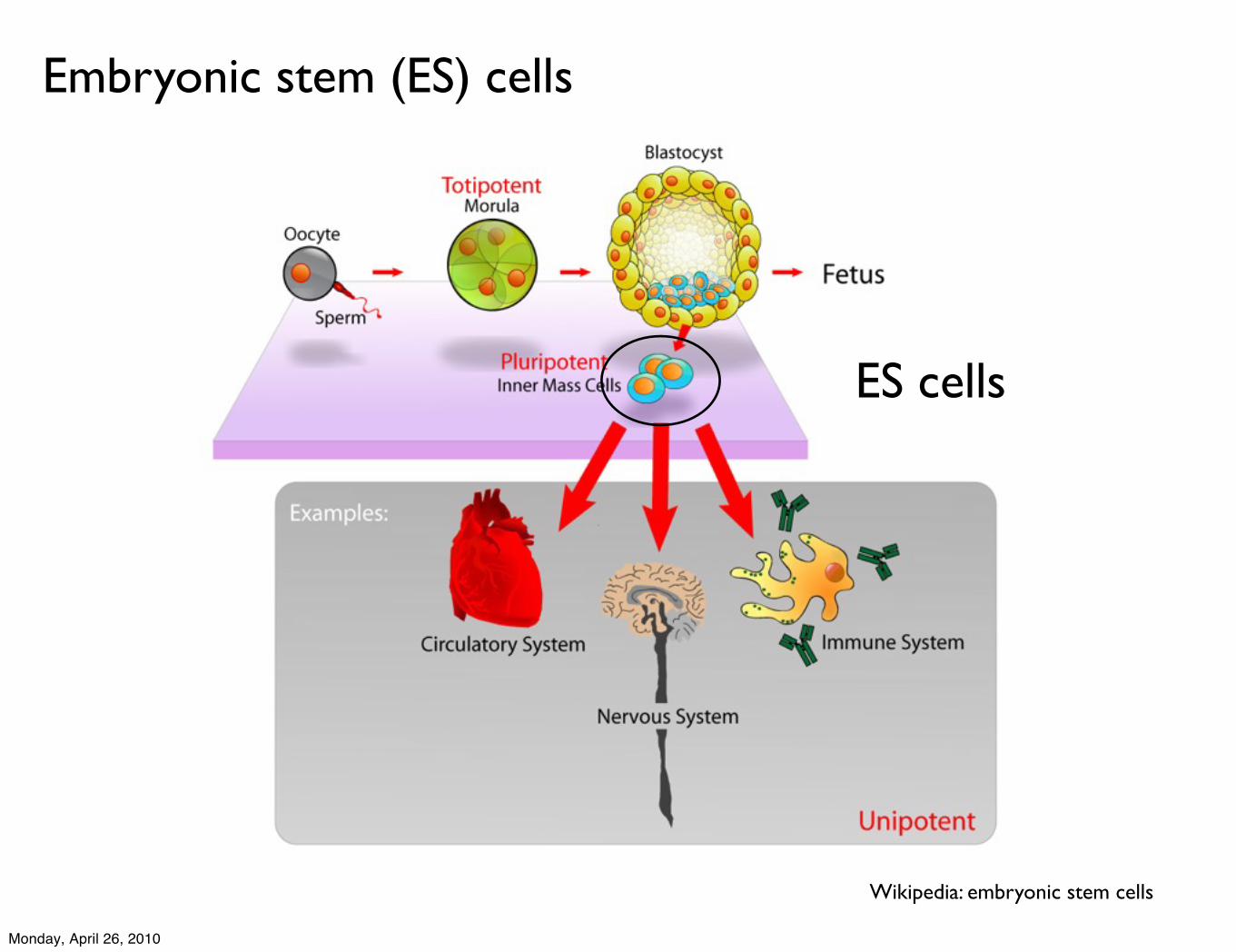
Embryonic stem (ES) cells
Wikipedia: embryonic stem cells
ES cells
Monday, April 26, 2010
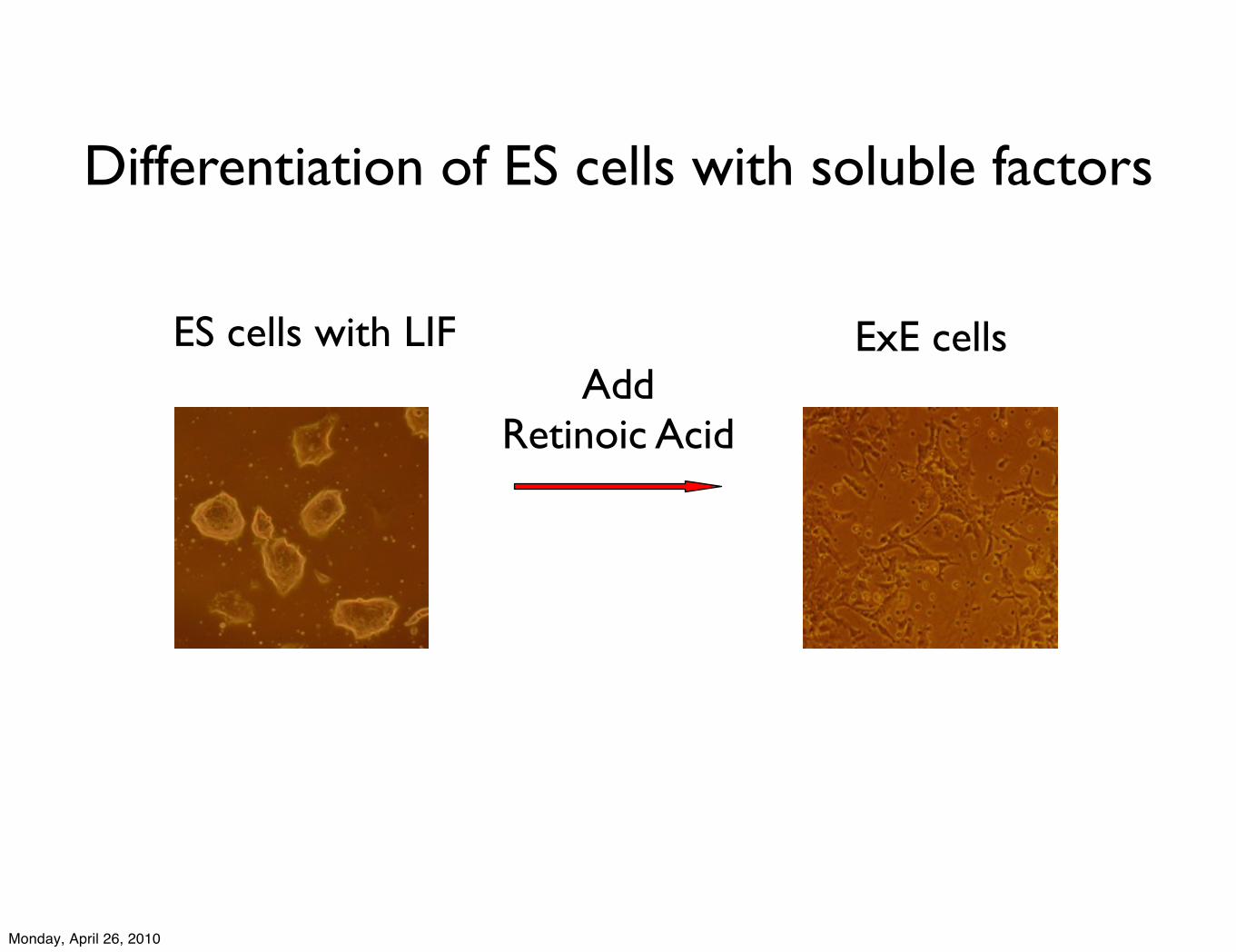
Differentiation of ES cells with soluble factors
ES cells with LIFAdd
Retinoic Acid
ExE cells
Monday, April 26, 2010
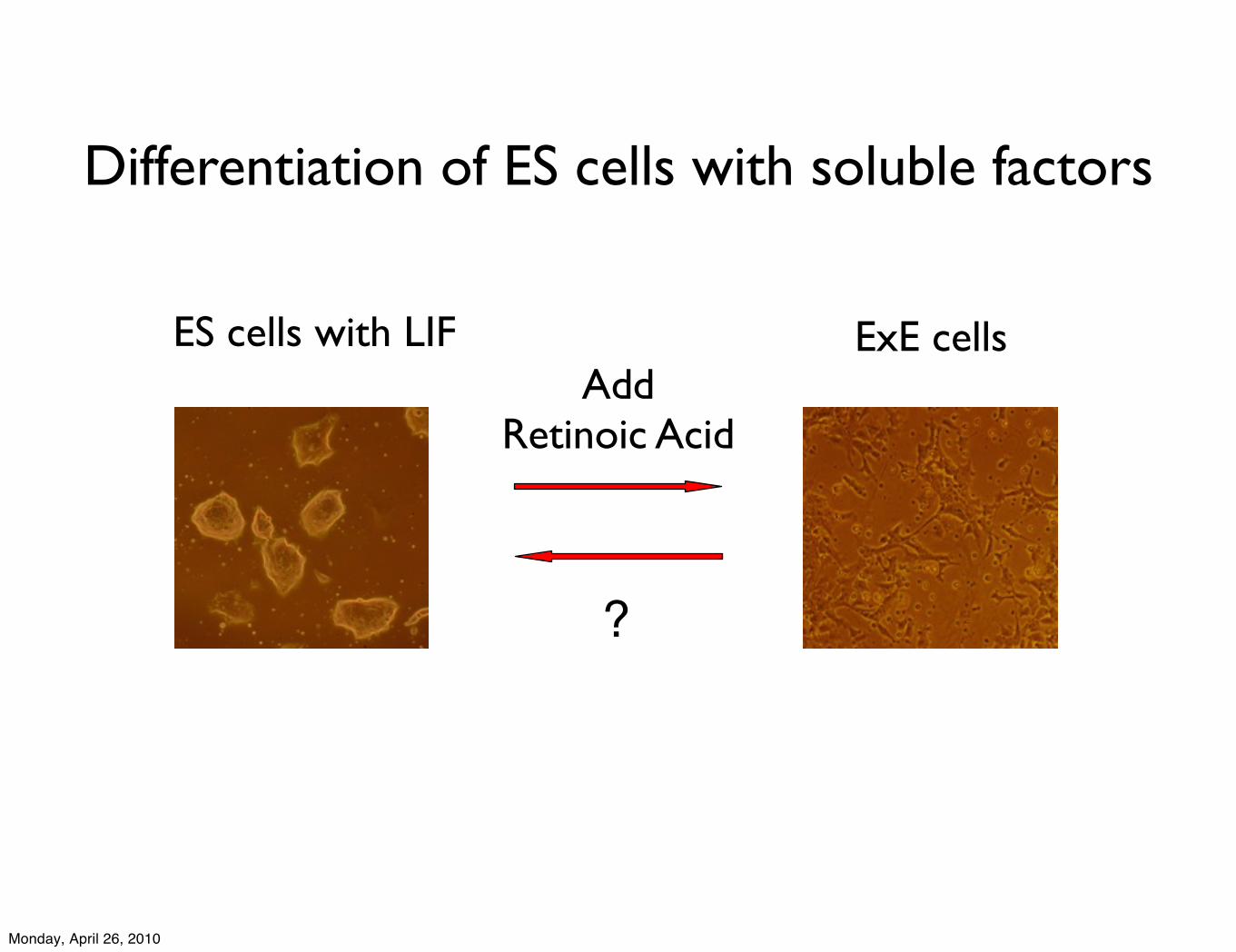
Differentiation of ES cells with soluble factors
ES cells with LIFAdd
Retinoic Acid
ExE cells
?
Monday, April 26, 2010

Experiments
Experiments: • forward: treat ES cells with RA (no LIF) for 2-5 days• reverse: replace RA with LIF
Measurements: • quantitative RT-PCR (population average gene expression)• Nanog-GFP reporter (single cell gene expression)• Flow cytometry
Monday, April 26, 2010
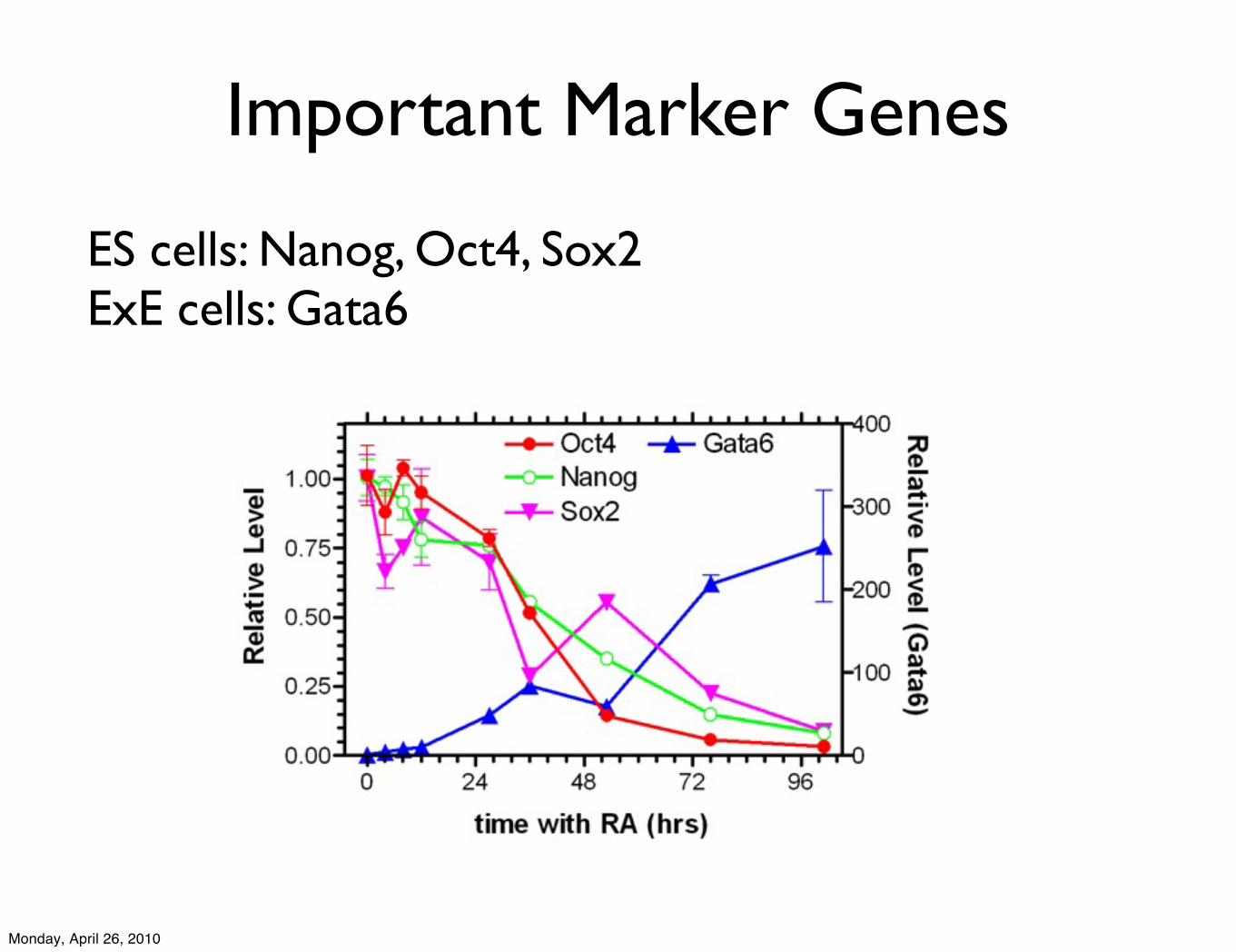
Important Marker Genes
ES cells: Nanog, Oct4, Sox2ExE cells: Gata6
Monday, April 26, 2010
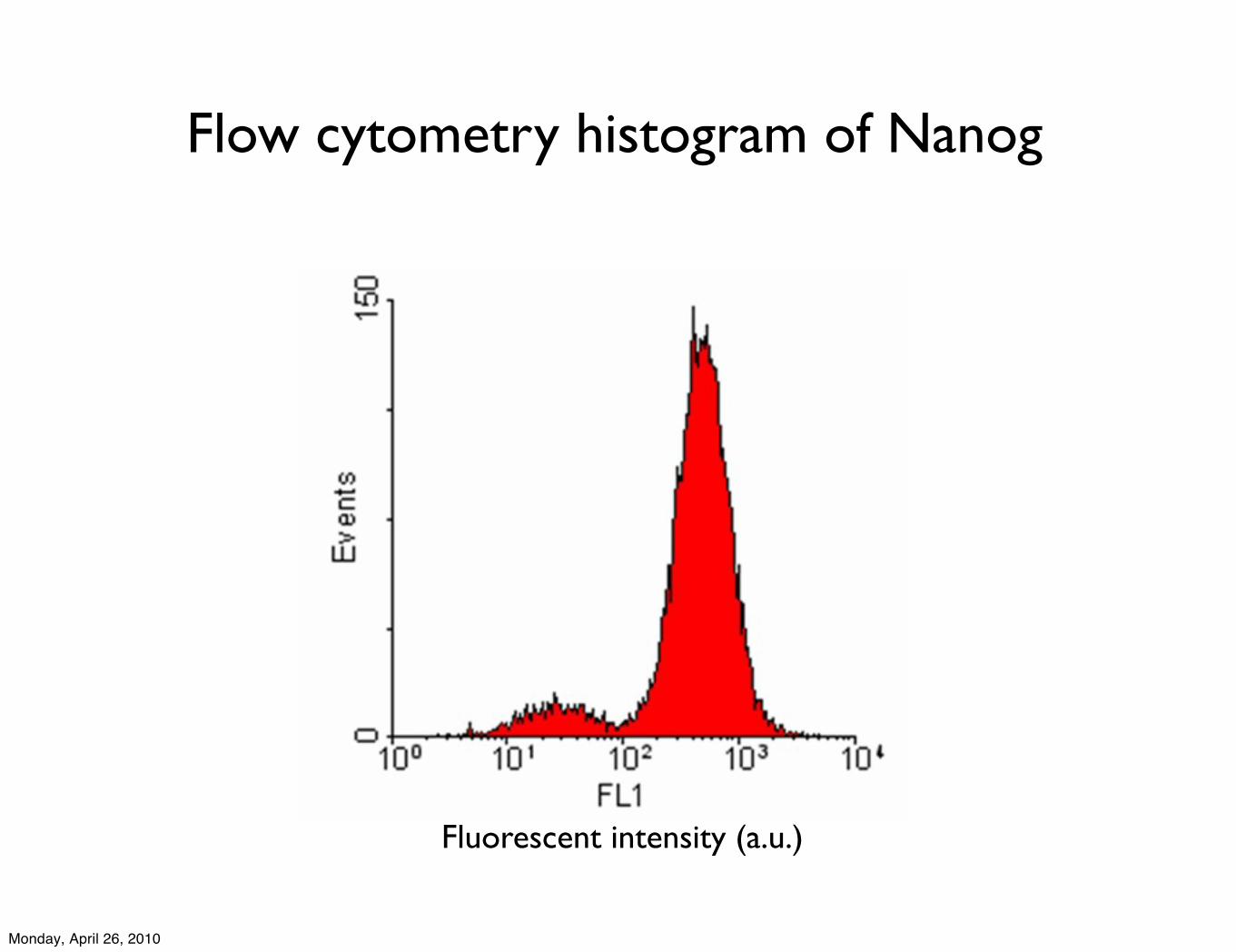
Flow cytometry histogram of Nanog
Fluorescent intensity (a.u.)
Monday, April 26, 2010

Reverse transition
Monday, April 26, 2010
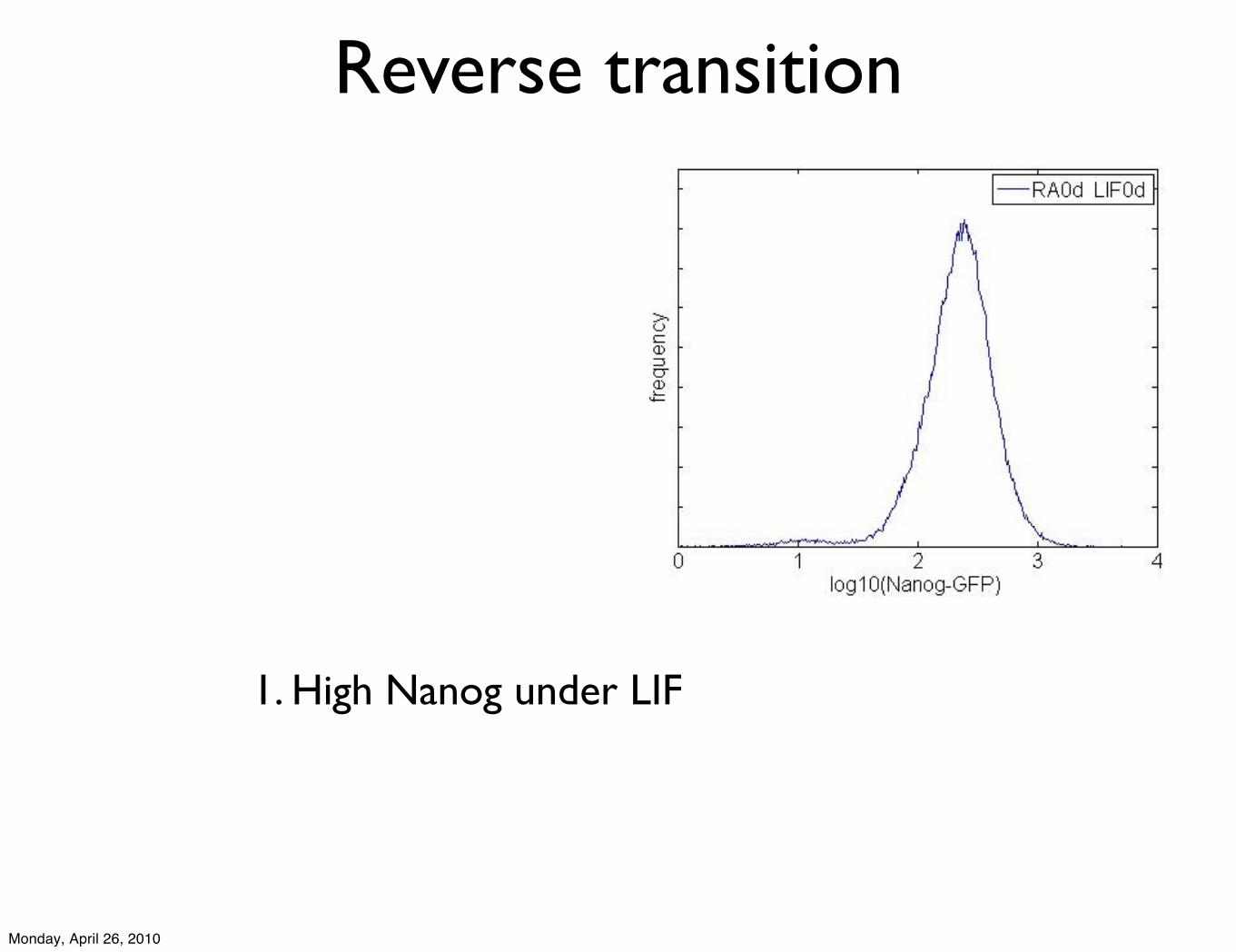
1. High Nanog under LIF
Reverse transition
Monday, April 26, 2010
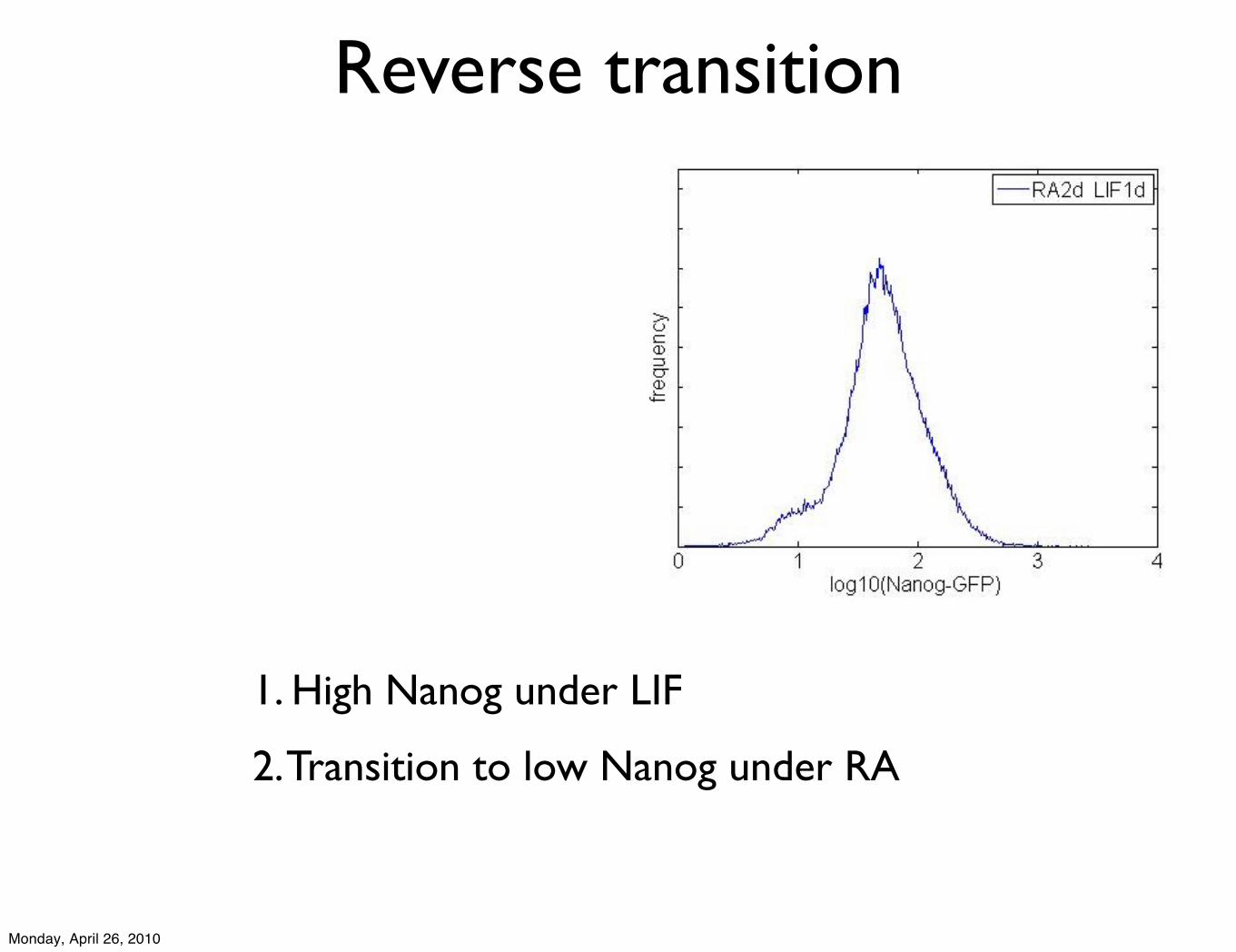
2. Transition to low Nanog under RA
1. High Nanog under LIF
Reverse transition
Monday, April 26, 2010
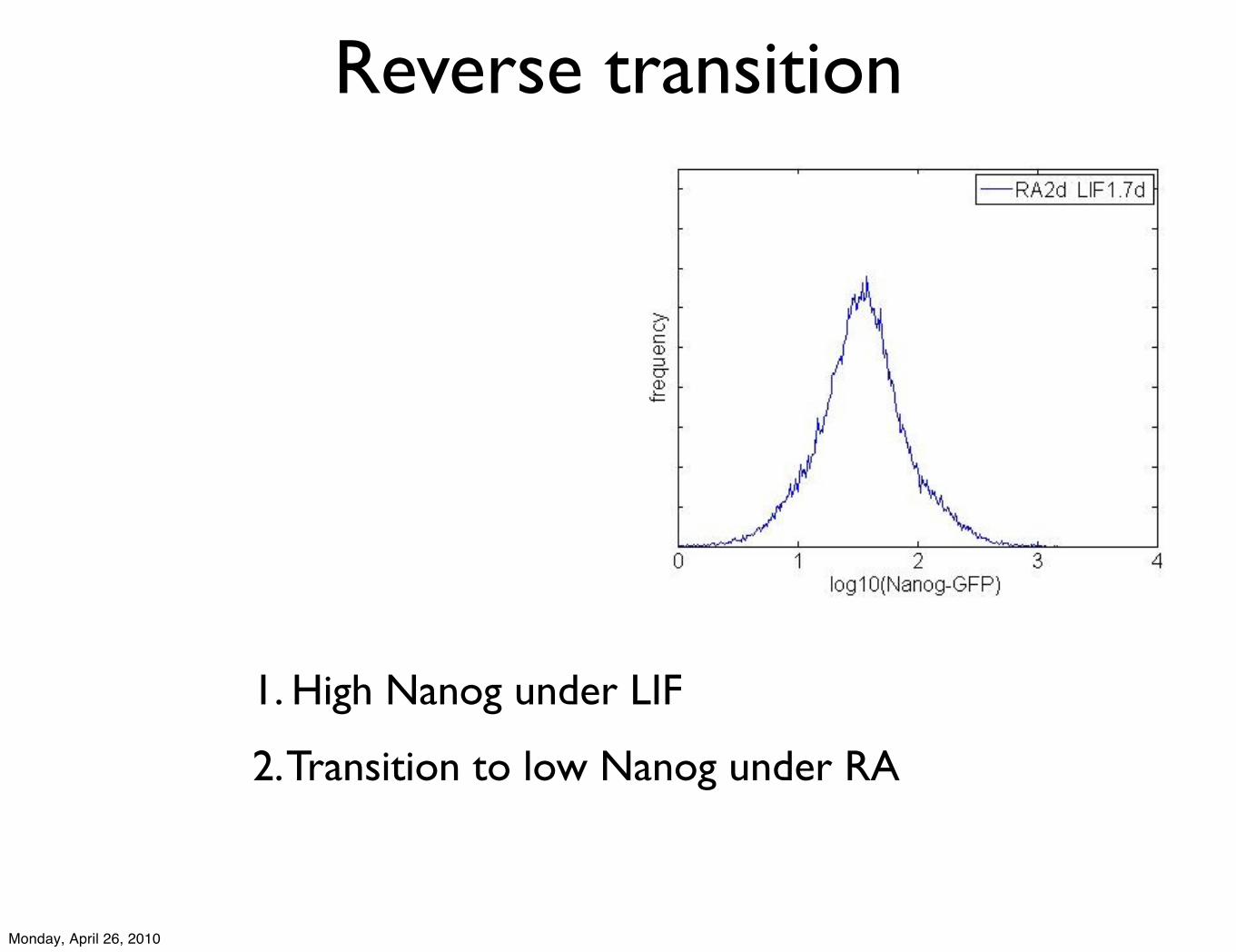
2. Transition to low Nanog under RA
1. High Nanog under LIF
Reverse transition
Monday, April 26, 2010
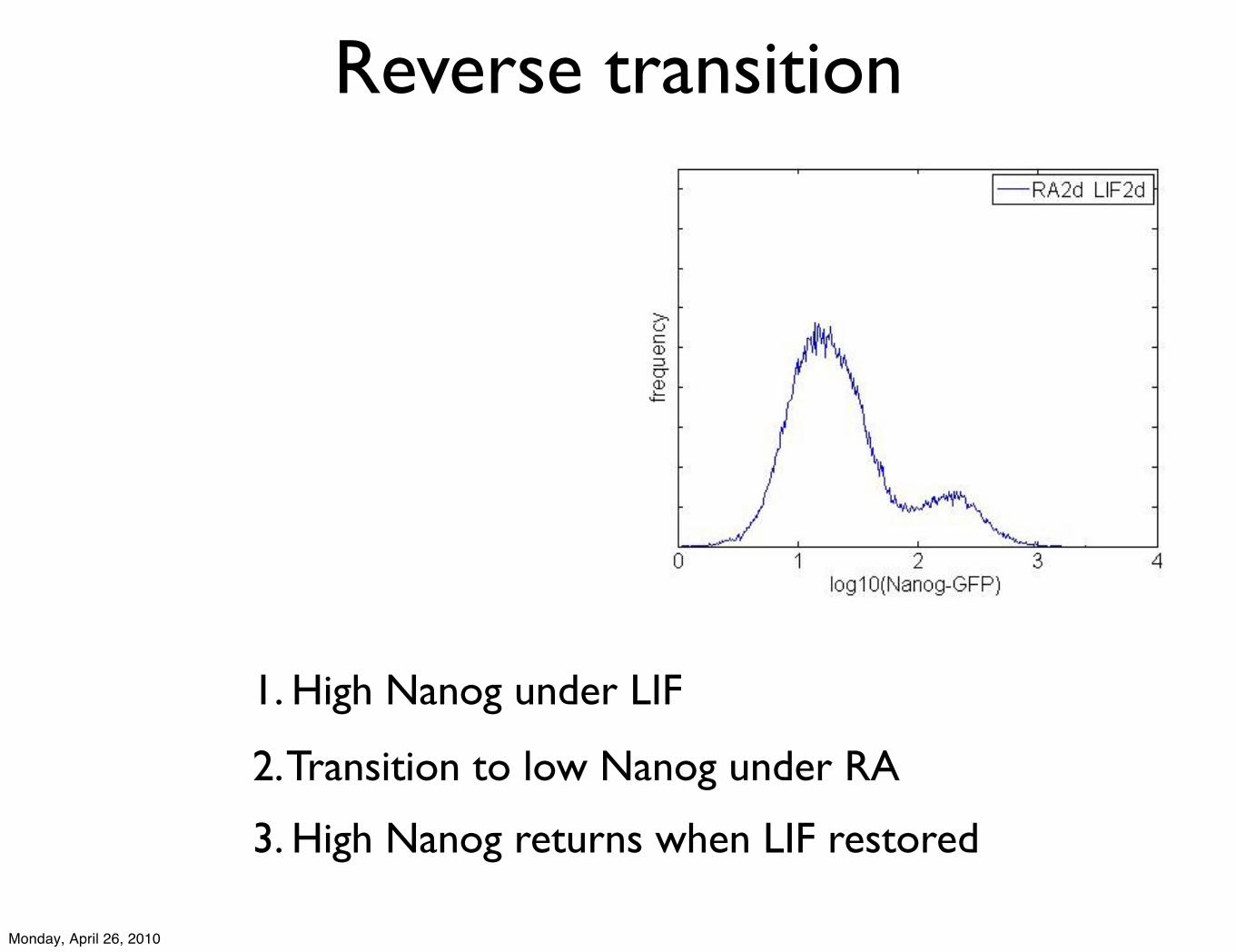
2. Transition to low Nanog under RA
3. High Nanog returns when LIF restored
1. High Nanog under LIF
Reverse transition
Monday, April 26, 2010
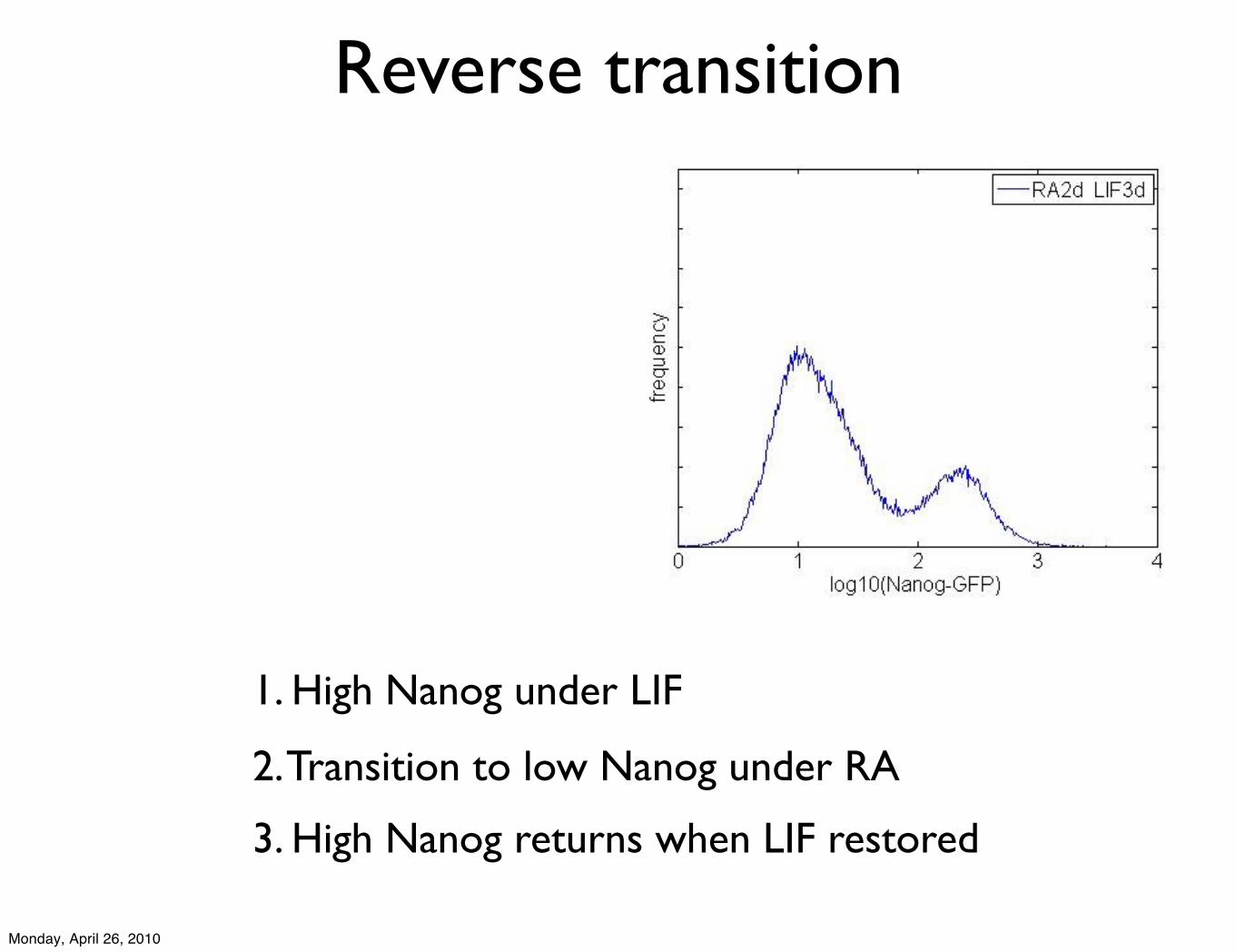
2. Transition to low Nanog under RA
3. High Nanog returns when LIF restored
1. High Nanog under LIF
Reverse transition
Monday, April 26, 2010
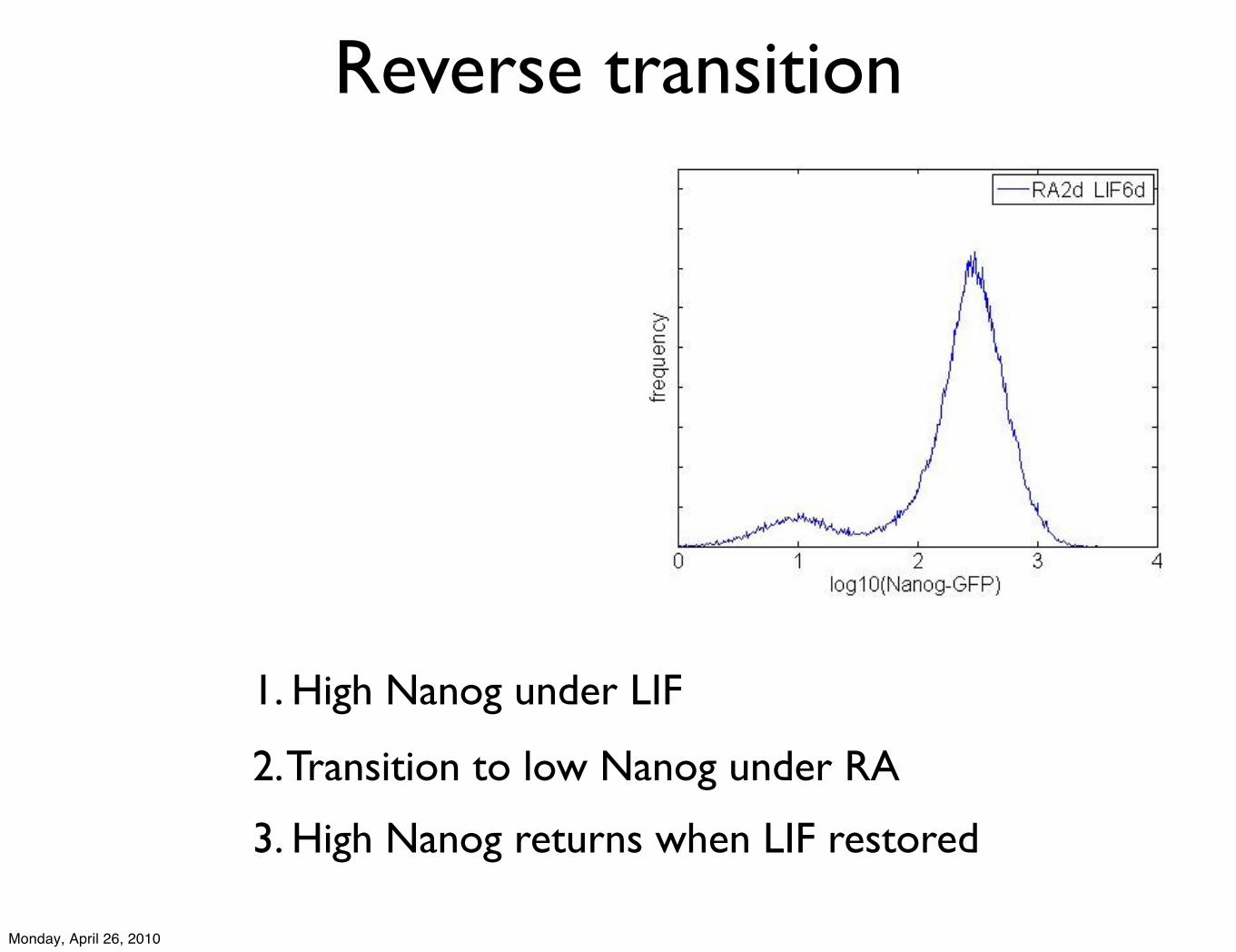
2. Transition to low Nanog under RA
3. High Nanog returns when LIF restored
1. High Nanog under LIF
Reverse transition
Monday, April 26, 2010
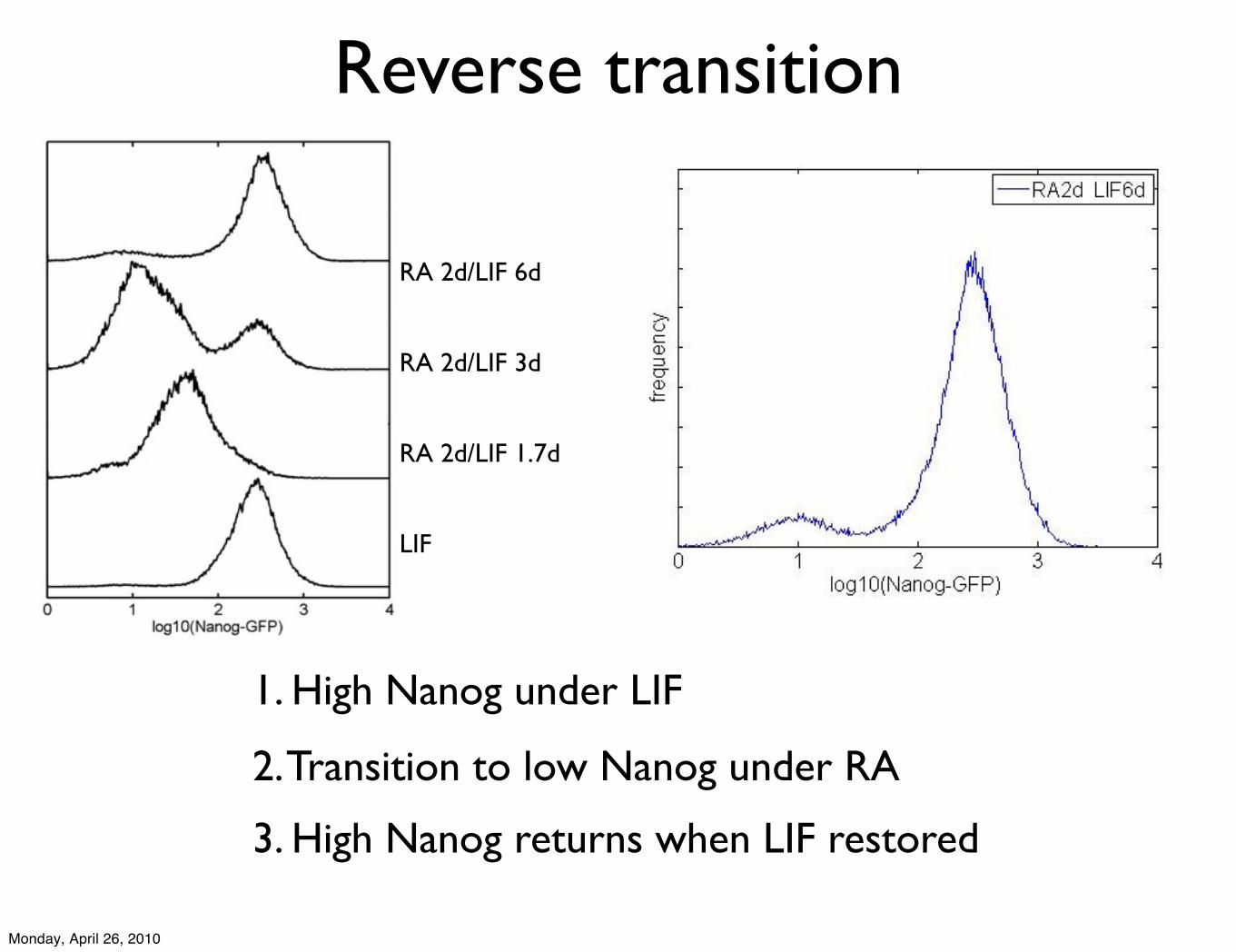
2. Transition to low Nanog under RA
3. High Nanog returns when LIF restored
1. High Nanog under LIF
Reverse transition
RA 2d/LIF 6d
RA 2d/LIF 3d
RA 2d/LIF 1.7d
LIF
Monday, April 26, 2010

Questions
Are low and high Nanog distinct stable states?
Are there transitions between states?
Or is it just the growth rates are different?
Monday, April 26, 2010

Questions
Are low and high Nanog distinct stable states?
Are there transitions between states?
Or is it just the growth rates are different?
Answer with PDE model and Bayesian inference
Monday, April 26, 2010

!w(y, t)!t
=!
!y2Dw ! !
!yf(y)w + r(y)w
V (y) = !! y
0f(s)ds
Drift-diffusion-growth equation
diffusion drift growth
y = Nanog levelw = probability density
EffectivePotential
Monday, April 26, 2010

Test 23 model hypotheses
5 double-well potential models
Monday, April 26, 2010

with 4 net proliferation rate models
Monday, April 26, 2010

3 single well potential models with bimodal net proliferation rate
Monday, April 26, 2010

Likelihood function
data point i for trial j
model prediction
Fit to 6 time dependent experiments
Monday, April 26, 2010
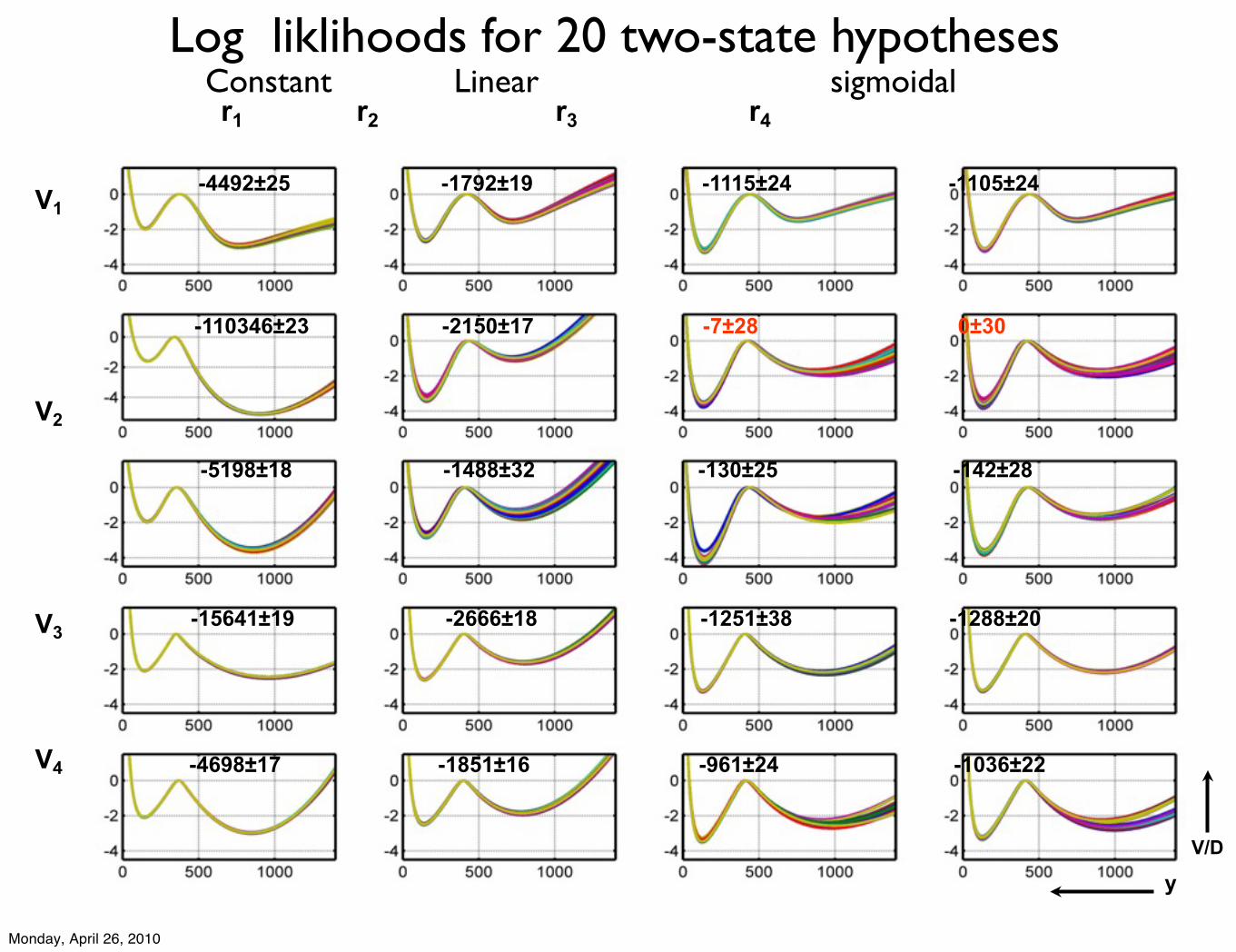
r1 r2 r3 r4
yV/D
V1
V2
V3
V4
V5
Constant Linear sigmoidal
-4492±25 -1792±19 -1115±24 -1105±24
-110346±23 -2150±17 -7±28 0±30
-5198±18 -1488±32 -130±25 -142±28
-15641±19 -2666±18 -1251±38 -1288±20
-4698±17 -1851±16 -961±24 -1036±22
Log liklihoods for 20 two-state hypotheses
Monday, April 26, 2010
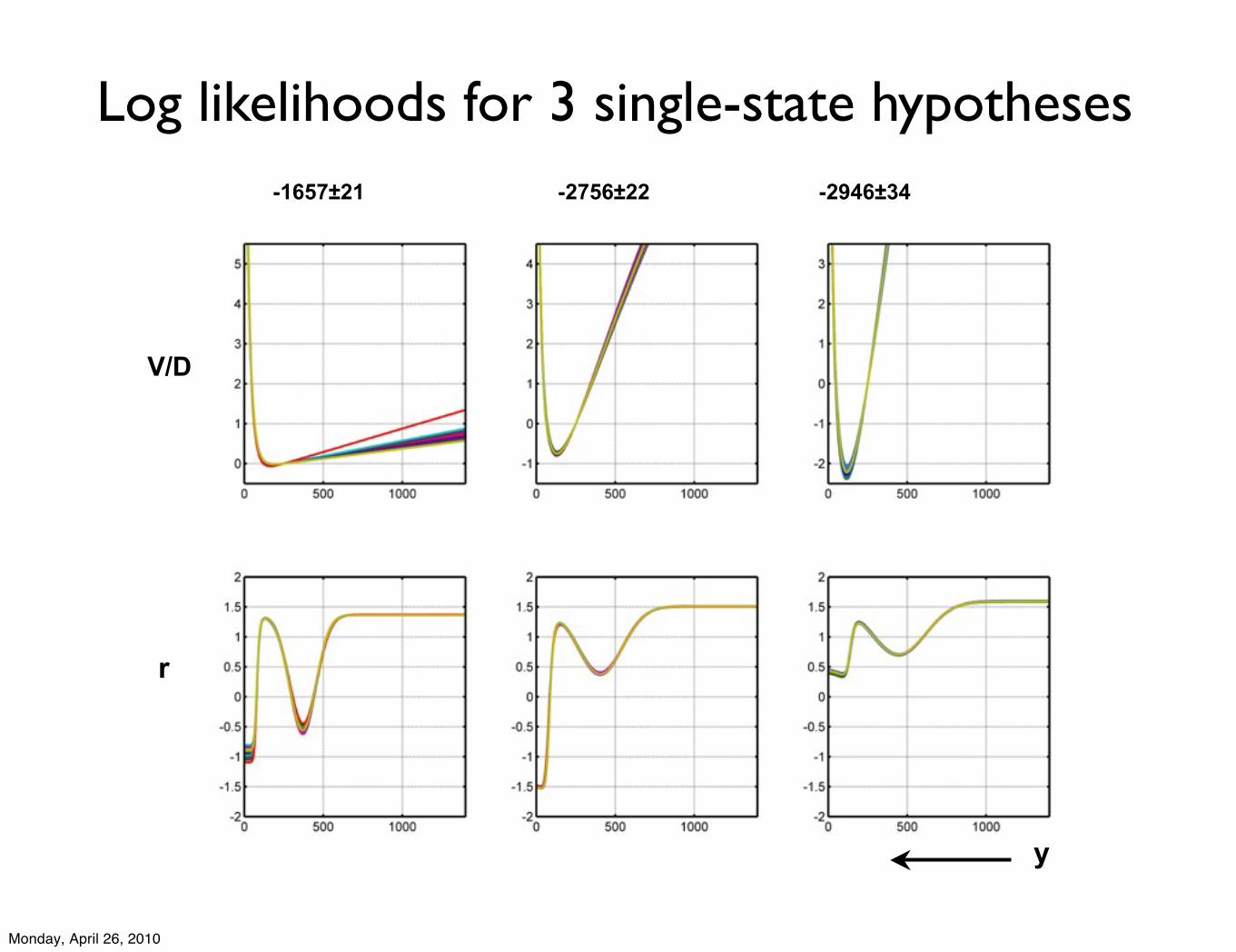
y
r
V/D
-1657±21 -2756±22 -2946±34
Log likelihoods for 3 single-state hypotheses
Monday, April 26, 2010
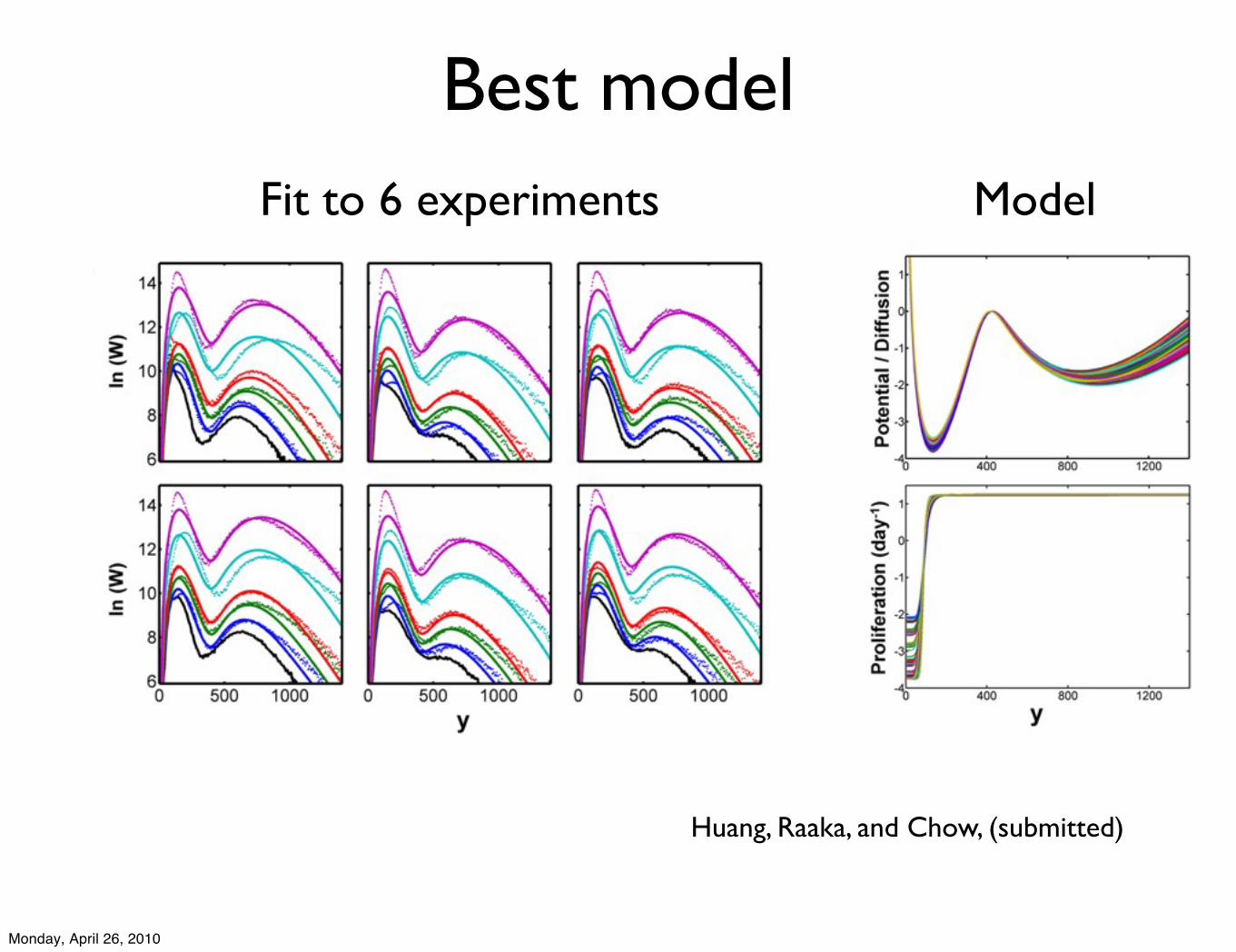
Best modelFit to 6 experiments Model
Huang, Raaka, and Chow, (submitted)
Monday, April 26, 2010
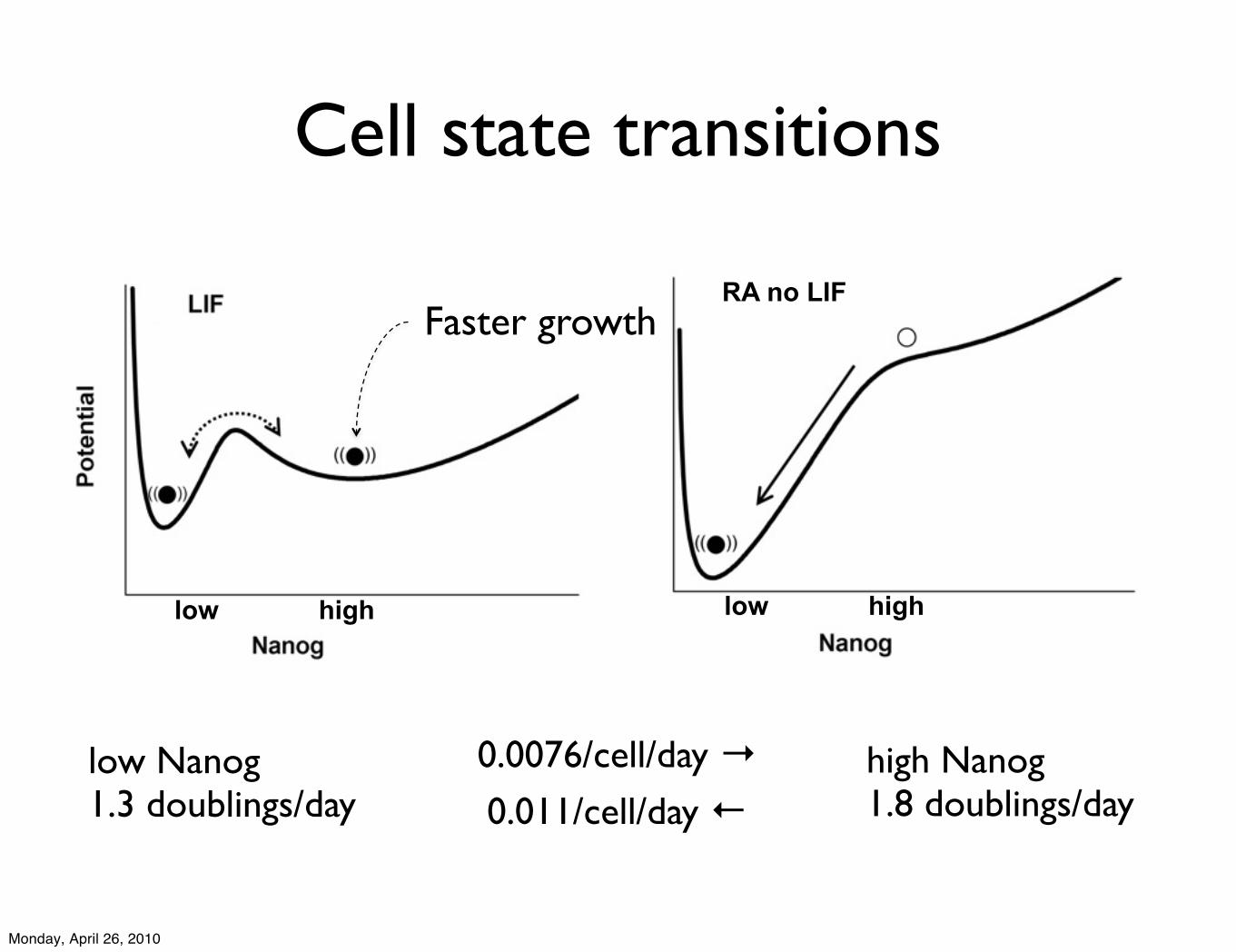
Cell state transitions
low high
RA no LIF
low high
Faster growth
0.0076/cell/day →0.011/cell/day ←
low Nanog1.3 doublings/day
Text high Nanog1.8 doublings/day
Monday, April 26, 2010

Insulin’s effect on Free Fatty Acids
Insulin resistance and Type 2 diabetes major health concern
Insulin increases glucose uptake by muscle andsuppresses release of FFAs by fat cells (lipolysis)
Need a way to quantitatively measure sensitivity to insulin
Monday, April 26, 2010
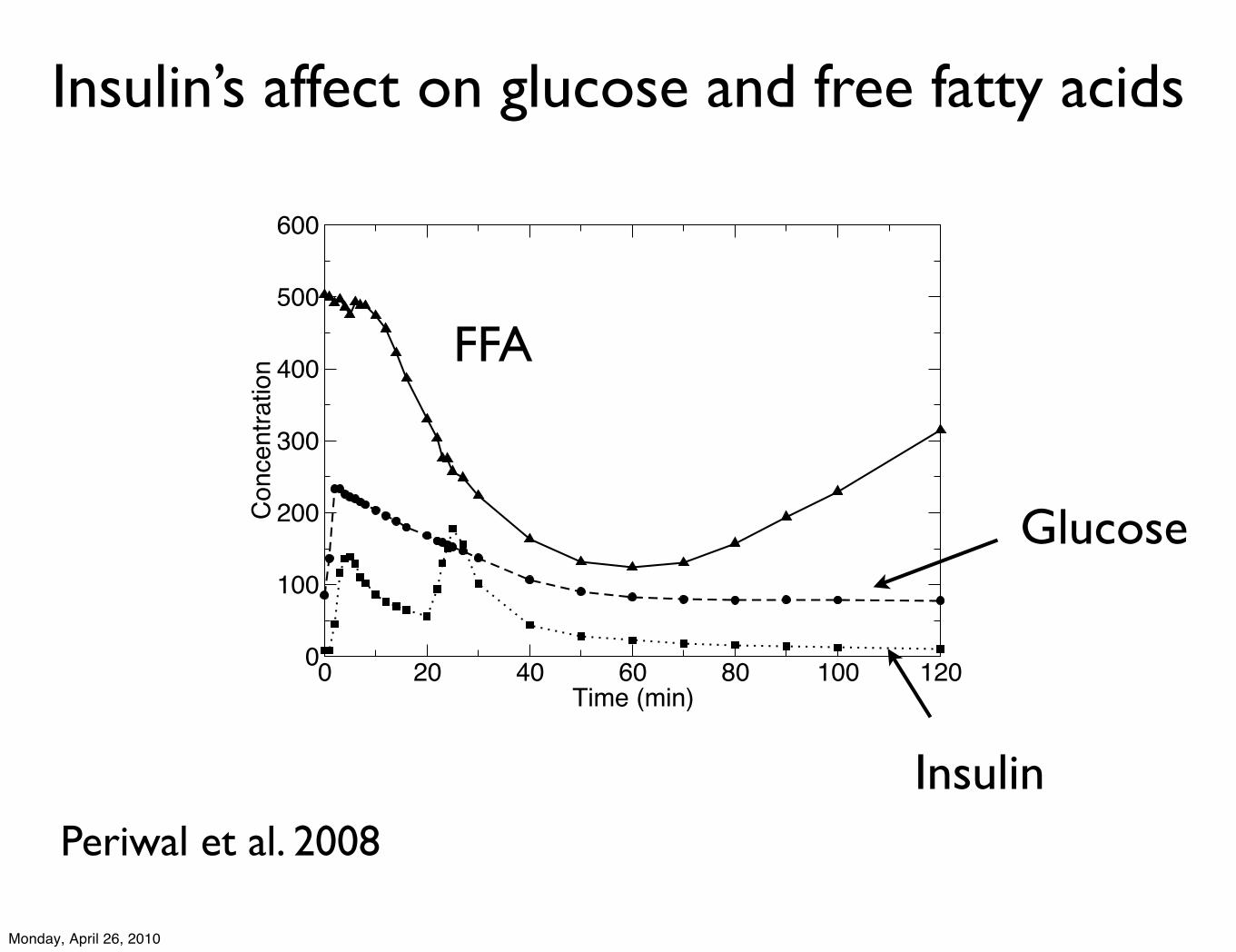
0 20 40 60 80 100 120Time (min)
0
100
200
300
400
500
600Co
ncen
tratio
n FFA
Glucose
Insulin
Insulin’s affect on glucose and free fatty acids
Periwal et al. 2008
Monday, April 26, 2010
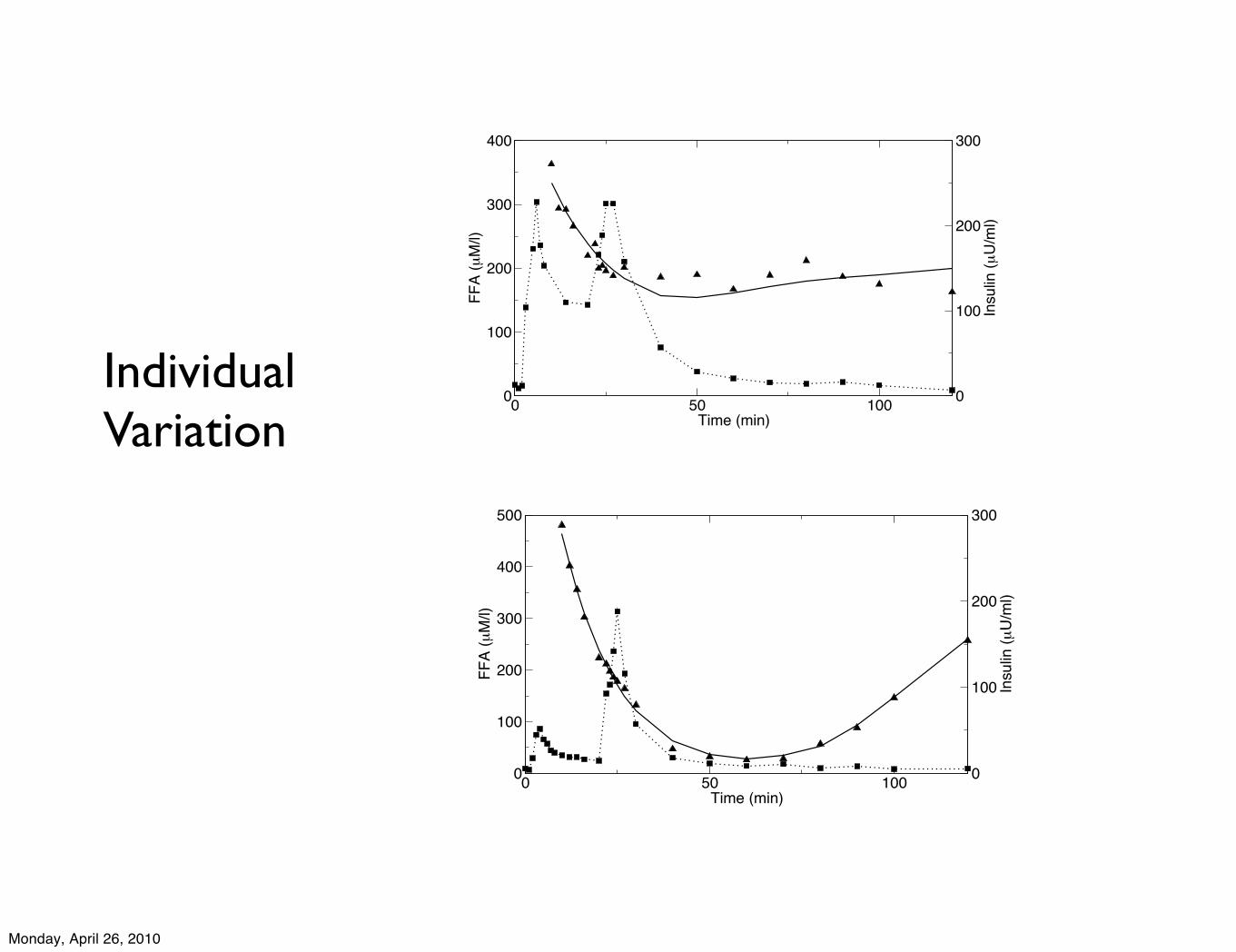
0 50 100Time (min)
0
100
200
300
400
FFA
(µM
/l)
0
100
200
300
Insu
lin (µ
U/m
l)
0 50 100Time (min)
0
100
200
300
400
500
FFA
(µM
/l)
0
100
200
300
Insu
lin (µ
U/m
l)
IndividualVariation
Monday, April 26, 2010
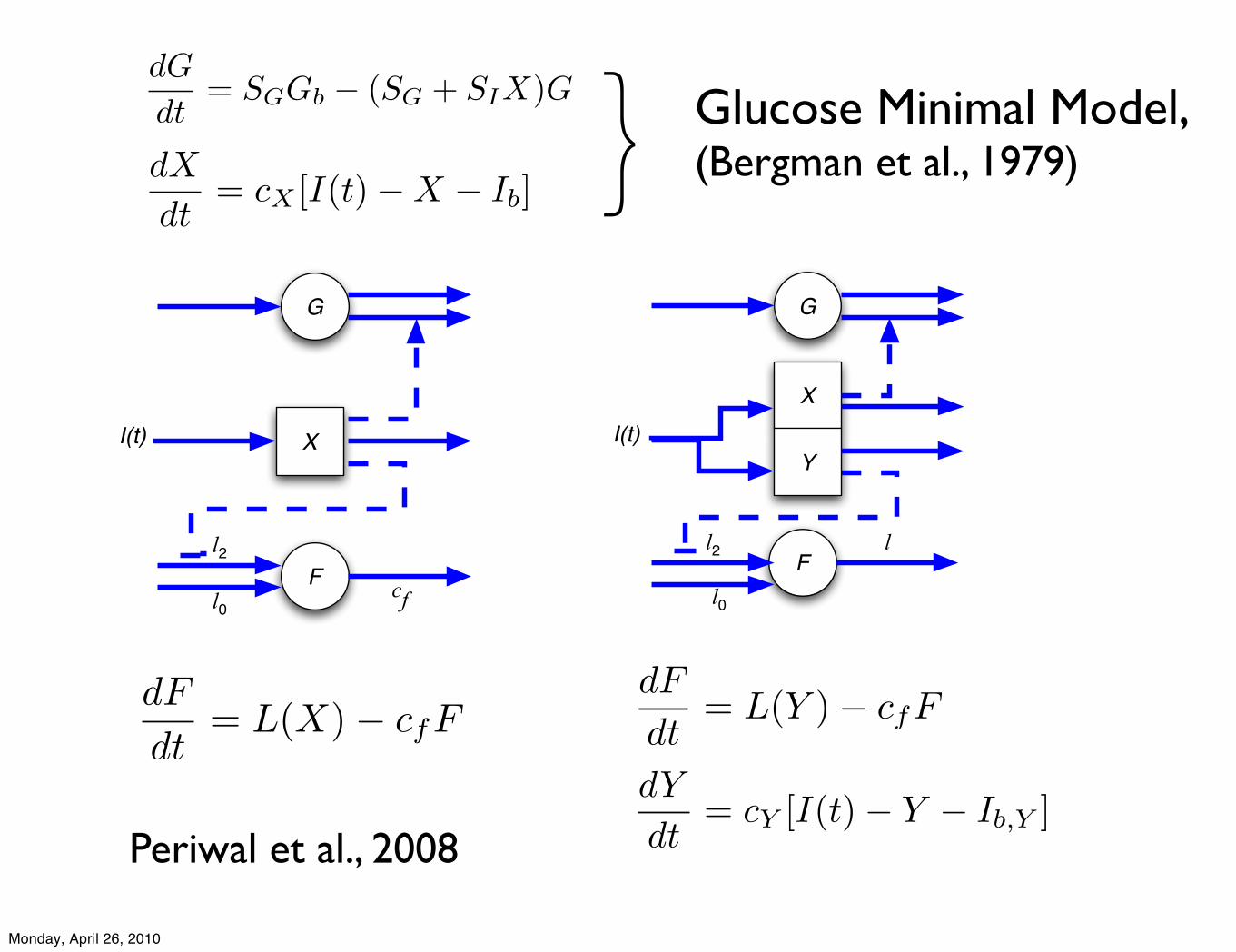
X
F
l2
cf
I(t)
G
l0
X
Fl2
l
I(t)
G
Y
l0
dG
dt= SGGb ! (SG + SIX)G
dX
dt= cX [I(t)!X ! Ib]
dF
dt= L(X)! cfF
dF
dt= L(Y )! cfF
dY
dt= cY [I(t)! Y ! Ib,Y ]
} Glucose Minimal Model,(Bergman et al., 1979)
Periwal et al., 2008
Monday, April 26, 2010

Models Results
Fit to 102 subjects
Monday, April 26, 2010

Models Results
Fit to 102 subjects
Monday, April 26, 2010
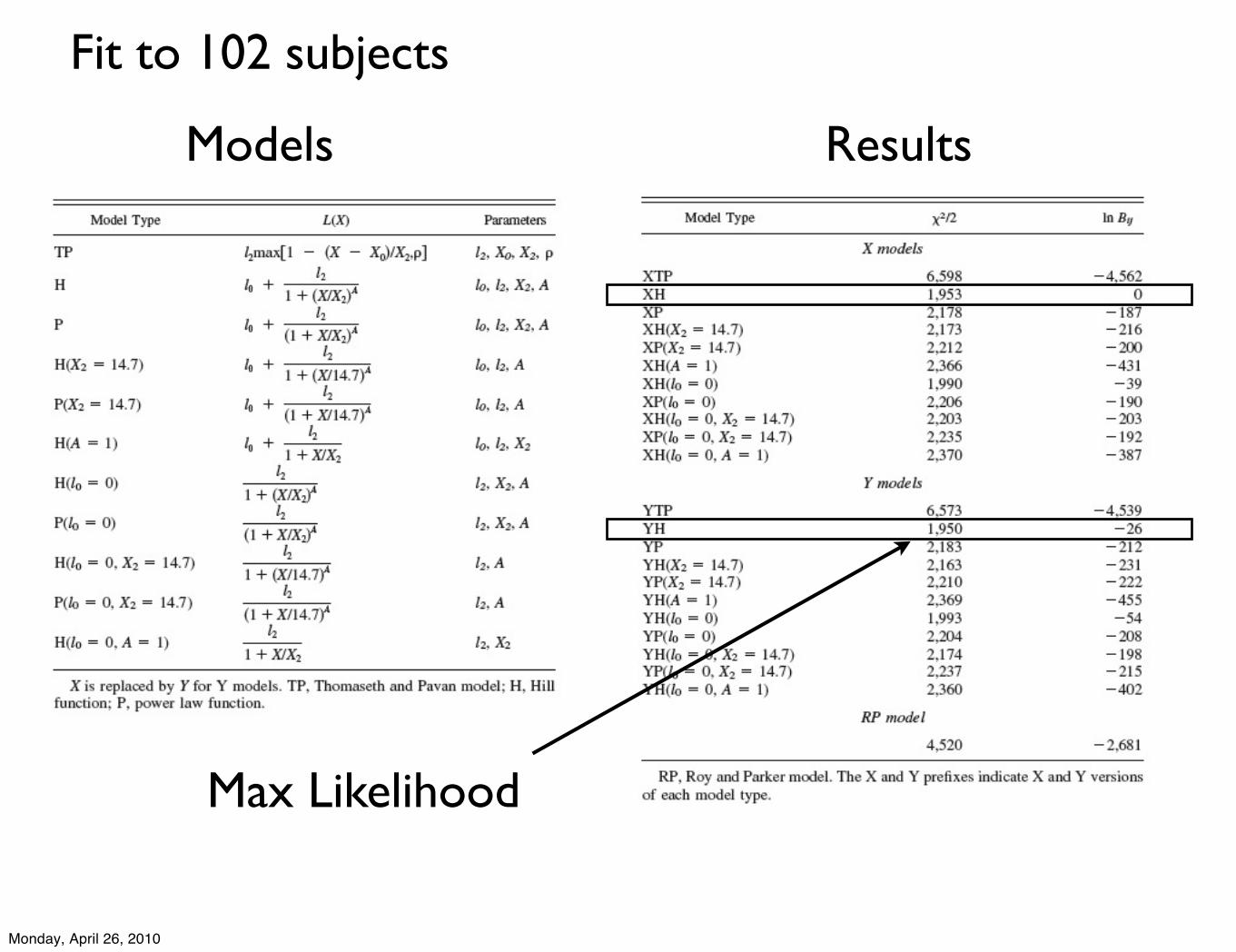
Models Results
Max Likelihood
Fit to 102 subjects
Monday, April 26, 2010

Summary
Bayesian methods give a straightforward means for parameter estimation and model comparison
Combined with Markov Chain Monte Carlo method, provides a one stop shop for all your model fit and evaluation needs
Many mathematical challenges, e.g. estimate for convergence time of MCMC
Monday, April 26, 2010

FFA: Vipul Periwal, Ann Sumner, Madia Ricks, NIDDK, Gloria Vega, UT, Richard Bergman, USC
Acknowledgments
Stem Cells: Wei Huang, Bruce Raaka, NIDDK
slides on sciencehouse.wordpress.com
Monday, April 26, 2010