
Base de datos: “pisos” - UMH
13
1 Solución Práctica Grupal Base de datos: “pisos” Pregunta 1. ¿Cuál es el modelo teórico de regresión a ajustar? ¿Cuál es la variable respuesta? ¿Cuáles son las covariables? El modelo teórico a ajustar es: pv = β 0 + β 1 m2 + β 2 euribor + β 3 pmbarrio La variable respuesta (Y) es el precio de venta de los pisos en Elche. Las covariables (X) son las variables explicativas analizadas, concretamente el número de metros cuadrados de los pisos, el Euribor cuando se vendieron los pisos y el precio medio del barrio donde se ubica la vivienda. Pregunta 2. Realiza el análisis preliminar de los datos. Explica todos los resultados que obtengas. datos=read.table("pisos.txt",header=T) attach(datos) plot(datos) En primer lugar, en el análisis preliminar vamos a realizar el análisis gráfico, para lo que estudiamos el gráfico de dispersión que nos dará una idea inicial de las relaciones existentes entre las variables. Así, podemos deducir que no se detectan relaciones lineales entre el precio de los pisos y las variables metros cuadrados y Euribor, por el contrario sí que existe una clara relación lineal entre el precio de los pisos y el precio medio del barrio donde se ubican, siendo ésta creciente (a mayor precio medio del barrio mayor precio final de venta de los pisos).
Transcript of Base de datos: “pisos” - UMH

1
Solución Práctica Grupal
Base de datos: “pisos”
Pregunta 1. ¿Cuál es el modelo teórico de regresión a ajustar? ¿Cuál es la variable respuesta?
¿Cuáles son las covariables?
El modelo teórico a ajustar es: pv = β0 + β1m2 + β2euribor + β3pmbarrio
La variable respuesta (Y) es el precio de venta de los pisos en Elche.
Las covariables (X) son las variables explicativas analizadas, concretamente el número
de metros cuadrados de los pisos, el Euribor cuando se vendieron los pisos y el precio
medio del barrio donde se ubica la vivienda.
Pregunta 2. Realiza el análisis preliminar de los datos. Explica todos los resultados que obtengas.
datos=read.table("pisos.txt",header=T)
attach(datos)
plot(datos)
En primer lugar, en el análisis preliminar vamos a realizar el análisis gráfico, para lo
que estudiamos el gráfico de dispersión que nos dará una idea inicial de las relaciones
existentes entre las variables. Así, podemos deducir que no se detectan relaciones
lineales entre el precio de los pisos y las variables metros cuadrados y Euribor, por el
contrario sí que existe una clara relación lineal entre el precio de los pisos y el precio
medio del barrio donde se ubican, siendo ésta creciente (a mayor precio medio del
barrio mayor precio final de venta de los pisos).

2
Corroboramos las impresiones del análisis gráfico mediante el estudio numérico.
En este estudio cuantificaremos el grado de linealidad existente entre la variable
respuesta y las variables explicativas mediante la correlación simple, y el grado de
relación entre las variables cuando consideramos la información de las restantes
mediante la correlación parcial (creando además un ranking de importancia de las
covariables).
Obtenemos tanto las correlaciones simples como las parciales.
cor(datos)
pv m2 euribor pmbarrio
pv 1.000 0.0216 -0.000278 0.978
Ciertamente, y como cabía esperar, la correlación simple entre pv y pmbarrio es altísima
y positiva.
Correlaciones Parciales
library(Rcmdr)
partial.cor(datos)

3
pv m2 euribor pmbarrio
pv 1.000 0.608 -0.337 0.987
Deducimos pues que la variable explicativa “precio medio barrio” es la que tiene un
mayor grado de relación lineal con la variable respuesta. El segundo mayor grado de
relación se da con los metros cuadros, y por último con el euribor. El orden es el mismo
tanto para las correlaciones simples como las parciales, aunque las correlaciones
aumentan considerablemente para las variables m2 y euribor cuando se considera el
cálculo de las parciales.
Pregunta 3. Ajusta el Modelo (escribe el modelo estimado). ¿Qué significa que alguno de los betas
sea negativo? Evalúa lo bueno o lo malo que es dicho modelo. Comprueba que se
cumplen todas las hipótesis básicas del modelo.
AJUSTE DEL MODELO:
En el ajuste del modelo obtenemos los valores que estima R para 0, 1, 2 y 3, así como
sus intervalos de confianza al 95% y los contrastes de hipótesis asociados. En concreto,
resolveremos el contraste de hipótesis asociado a la pregunta de si cada coeficiente es
igual a cero o distinto de cero; cuando rechazamos la hipótesis de coeficiente cero la
variable es verdaderamente útil para explicar el precio de venta del piso, por el
contrario, cuando el coeficiente puede ser cero podemos llegar a plantearnos la
idoneidad de mantener o no en el modelo la covariable (X) asociada.
fit=lm(pv~m2+euribor+pmbarrio) sfit=summary(fit);sfit
MODELO DE REGRESIÓN (Estimación Puntual)
pv = 6.66 + 0.021m2 – 0.283euribor + 0.049pmbarrio
El 2 es negativo, (-0.283), de lo que deducimos que cuando aumentamos en una unidad
el precio del euribor y mantenemos el resto de variables constantes (ceteris paribus), la
variable respuesta (precio de venta) disminuye en 0.28 unidades.
Por otra parte, los intervalos de confianza al 95% de los coeficientes son:
confint(fit)
IC 95% 0 (4.96233, 8.36833) IC 95% m2 (0.01007, 0.03239)
IC 95% euribor (-0.60271, 0.03586)
IC 95% pmbarrio (0.04674, 0.05309)
Contraste de Hipótesis para las distintas variables:
H0: β1 = 0
H1: β1 0.

4
A β1 le corresponde un p-valor de 0.000588, con lo que es menor que 0,05, por tanto
rechazamos H0 y concluimos que m2 es una variable estadísticamente significativa a la
hora de explicar el precio de venta de los pisos (Y).
A β2 le corresponde un p-valor de 0.07956, con lo que es mayor que 0,05, por tanto no
podemos rechazar H0 a favor de H1. Lo que, en definitiva, significa que Euribor no es
una variable relevante en el modelo de regresión si tenemos en cuenta el resto de
covariables.
A β3 le corresponde un p-valor de 2x10-16
, con lo que es mucho menor que 0,05, por
tanto rechazamos H0 y y concluimos que pmbarrio es una variable estadísticamente
significativa a la hora de explicar el precio de venta de los pisos (Y).
BONDAD DEL AJUSTE:
Para evaluar lo bueno o malo del modelo realizamos la Bondad del Ajuste, para lo que
contamos con varias medidas para cuantificarla.
Como mostramos a continuación los tres criterios concluyen que el modelo es bueno.
cv=100*(0.4708/mean(pv));cv
El Error Estándar Residual. Es una medida relativa a la escala de medida
utilizada. Se prefieren valores bajos para el error estándar residual. Nuestro
modelo nos da un valor de 0,4708 (si acudimos al summary de fit), y para
esclarecer si es un valor grande o pequeño (es bueno cuando es inferior al 10%)
calculamos el coeficiente de variación de la siguiente manera:
cv=100*(0.4708/la media de pv)% = 3.08 %. Al ser claramente inferior a 10%,
concluimos que el modelo es bueno según este criterio.
Tabla de ANOVA. Vamos a cuantificar cuánta de la variabilidad contenida en los
datos ha conseguido ser explicada por nuestro modelo. Lo obtenemos mediante
la respuesta al siguiente contrate :
H0: β1 = β2 = β3 = 0
H1: Lo contrario.
Dado que el p-valor que nos ofrece el modelo es de 2.2x10-16
(si acudimos al summary
de fit) es menor que 0,05, rechazamos H0 en favor de H1, dando el modelo como bueno
según este criterio.
Coeficiente de determinación. : es la proporción de la varianza que es explicada
por la recta de regresión. El valor que obtengamos nos indica el valor en tanto
por ciento de la variabilidad total de los datos, cuánto más se aproxime al 100%
es evidente que más parte de la varianza es explicada por la recta de regresión.
Obtenemos los datos del resumen.
Multiple R-square: 0.97, lo que indica que es muy bueno, el modelo de regresión
estimado explica el 97% de la variabilidad total de la variable pv.

5
Finalmente, comparamos el R2 (0,9757) y el R
2 (0,9729) Ajustado, esto lo realizamos
porque el mero hecho de tener varias variables explicativas puede distorsionar el valor
del R2 original. En nuestro estudio son prácticamente iguales, por lo que tomamos como
referencia el R2.
En definitiva, el modelos es bueno según los tres criterios analizados.
DIAGNÓSTICO DEL MODELO:
Diagnosticamos a continuación si el modelo satisface las distintas hipótesis básicas del
modelo de regresión lineal para los errores:
La media de los errores son igual a 0. Hipótesis que siempre se verifica porque
usamos el método de máxima verosimilitud que nos asegura que la media de los
residuos es siempre cero.
La hipótesis de normalidad. Para verificar esta hipótesis construiremos un
histograma para ver las desviaciones respecto a la campana de Gauss y
analizaremos el gráfico qqplot donde se representa los residuos ordenados
versus los cuantiles correspondientes de una normal.
par(mfrow=c(2,2)) plot(fit)
e<-residuals(fit) d<-e/sfit$sigma hist(d,probability=T,xlab="Residuo standarizados",main="",xlim=c(-3,3)) d.seq<-seq(-3,3,length=50) lines(d.seq,dnorm(d.seq,mean(d),sd(d)))
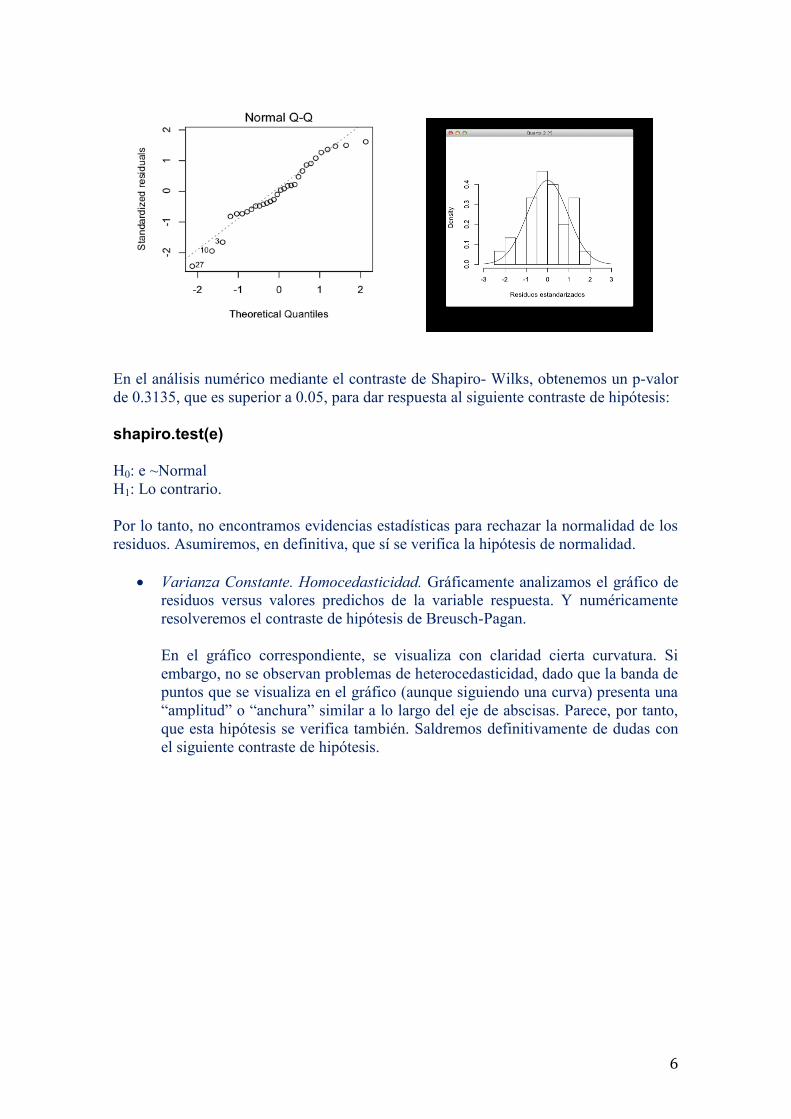
En el gráfico qqplot no todos los puntos están sobre la línea discontinua de
referencia. Se observan desviaciones de la normalidad en ambas colas. Por otra
parte, el histograma correspondiente también presenta una clara desviación de la
simetría, por lo que concluimos que existen ciertas dudas sobre la normalidad
que el test de Shapiro-Wilks puede despejar.
6
En el análisis numérico mediante el contraste de Shapiro- Wilks, obtenemos un p-valor
de 0.3135, que es superior a 0.05, para dar respuesta al siguiente contraste de hipótesis:
shapiro.test(e)
H0: e ~Normal
H1: Lo contrario.
Por lo tanto, no encontramos evidencias estadísticas para rechazar la normalidad de los
residuos. Asumiremos, en definitiva, que sí se verifica la hipótesis de normalidad.
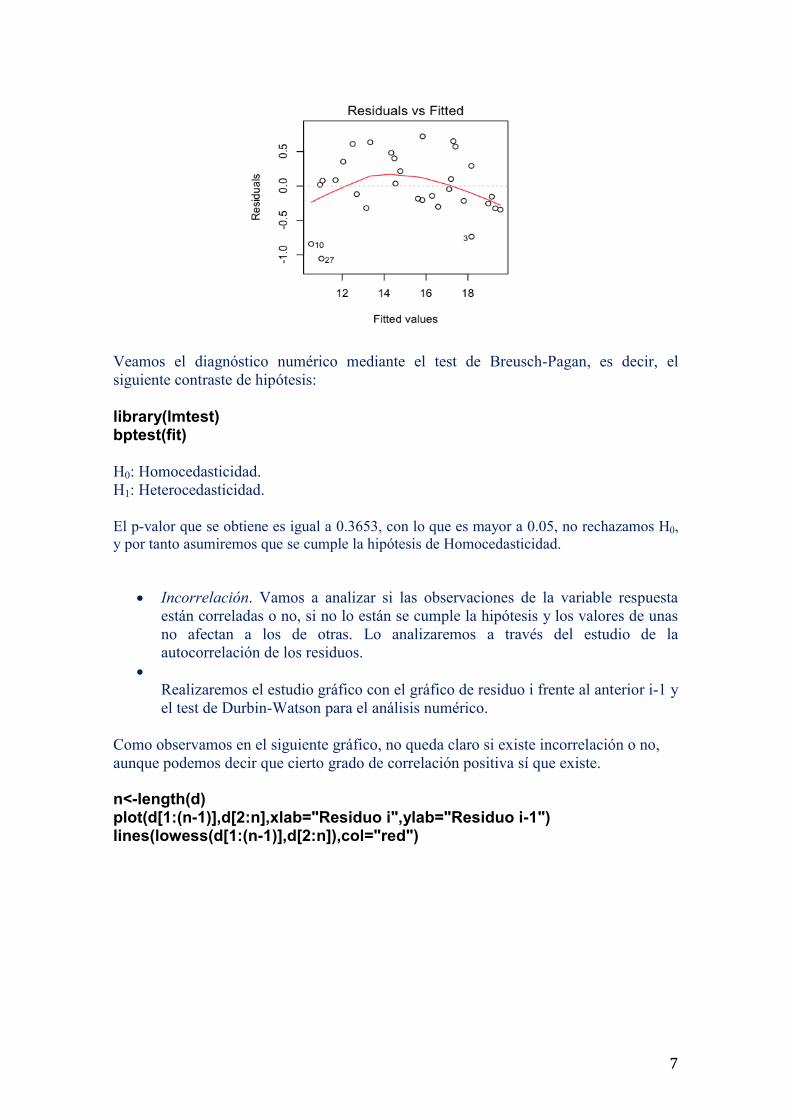
Varianza Constante. Homocedasticidad. Gráficamente analizamos el gráfico de
residuos versus valores predichos de la variable respuesta. Y numéricamente
resolveremos el contraste de hipótesis de Breusch-Pagan.
En el gráfico correspondiente, se visualiza con claridad cierta curvatura. Si
embargo, no se observan problemas de heterocedasticidad, dado que la banda de
puntos que se visualiza en el gráfico (aunque siguiendo una curva) presenta una
“amplitud” o “anchura” similar a lo largo del eje de abscisas. Parece, por tanto,
que esta hipótesis se verifica también. Saldremos definitivamente de dudas con
el siguiente contraste de hipótesis.
7
Veamos el diagnóstico numérico mediante el test de Breusch-Pagan, es decir, el
siguiente contraste de hipótesis:
library(lmtest) bptest(fit)
H0: Homocedasticidad.
H1: Heterocedasticidad.
El p-valor que se obtiene es igual a 0.3653, con lo que es mayor a 0.05, no rechazamos H0,
y por tanto asumiremos que se cumple la hipótesis de Homocedasticidad.
Incorrelación. Vamos a analizar si las observaciones de la variable respuesta
están correladas o no, si no lo están se cumple la hipótesis y los valores de unas
no afectan a los de otras. Lo analizaremos a través del estudio de la
autocorrelación de los residuos.
Realizaremos el estudio gráfico con el gráfico de residuo i frente al anterior i-1 y
el test de Durbin-Watson para el análisis numérico.
Como observamos en el siguiente gráfico, no queda claro si existe incorrelación o no,
aunque podemos decir que cierto grado de correlación positiva sí que existe.
n<-length(d) plot(d[1:(n-1)],d[2:n],xlab="Residuo i",ylab="Residuo i-1") lines(lowess(d[1:(n-1)],d[2:n]),col="red")

8
Para salir de dudas, realizamos el diagnóstico numérico mediante el contraste siguiente
(el test de Dubin-Watson).
library(lmtest) dwtest(fit,alternative="two.sided")
H0: = 0
H1: 0
El p-valor resultante es de 0.03123, por lo que al ser inferior a 0.05 debemos rechazar H0, y
concluir que atendiendo a este diagnóstico la hipótesis de incorrelación no se verificaría.
En definitiva, y a modo de resumen, el modelo cumple con todas las hipótesis básicas
excepto con la de incorrelación.
Pregunta 4. ¿Cuál sería la transformación de la variable respuesta que propone el método de Box-
Cox? Realiza el ajuste del nuevo modelo. ¿Consigue solucionar los problemas que
teníamos con el modelo original? [A este modelo le llamaremos MODELO FINAL].
library(MASS)
bc<-boxcox(fit,plotit=F) lambda<-bc$x[which.max(bc$y)];lambda lambda
Mediante el modelo Box-Cox, obtenemos un valor de lamba de 1,9.
Al dar un valor distinto de cero realizamos la trasformación de la variable elevada a
lambda en vez de la transformación en logaritmo neperiano que sería el adecuado si
lambda hubiera valido cero (o próximo a cero).
Transformamos la variable respuesta pv en z:
library(labstatR) z<-(pv^lambda-1)/(lambda*mean.g(pv)^(lambda-1));z

9
Realizamos el ajuste del nuevo modelo (MODELO FINAL), llamando a la variable
respuesta z. (precio de la vivienda transformada.)
fit=lm(z~m2+euribor+ pmbarrio) sfit=summary(fit);sfit
Modelo de Regresión Ajustado sería:
z= 0,1841 + 0.01757m2 – 0.2864euribor + 0.04943pmbarrio
Aunque deberíamos realizar los cuatro pasos fundamentales en el análisis
pormenorizado del nuevo modelo (MODELO FINAL), a continuación realizaremos
directamente el diagnóstico del modelo para ver si se han solucionado los problemas del
modelo original (incorrelación).
Diagnóstico del modelo. Modelo Final.
Estudiamos a continuación las distintas hipótesis, mediante el análisis de los residuos.
La media de los errores son igual a 0. Hipótesis que siempre se verifica por
hacer uso del Estimador Máximo Verosímil.
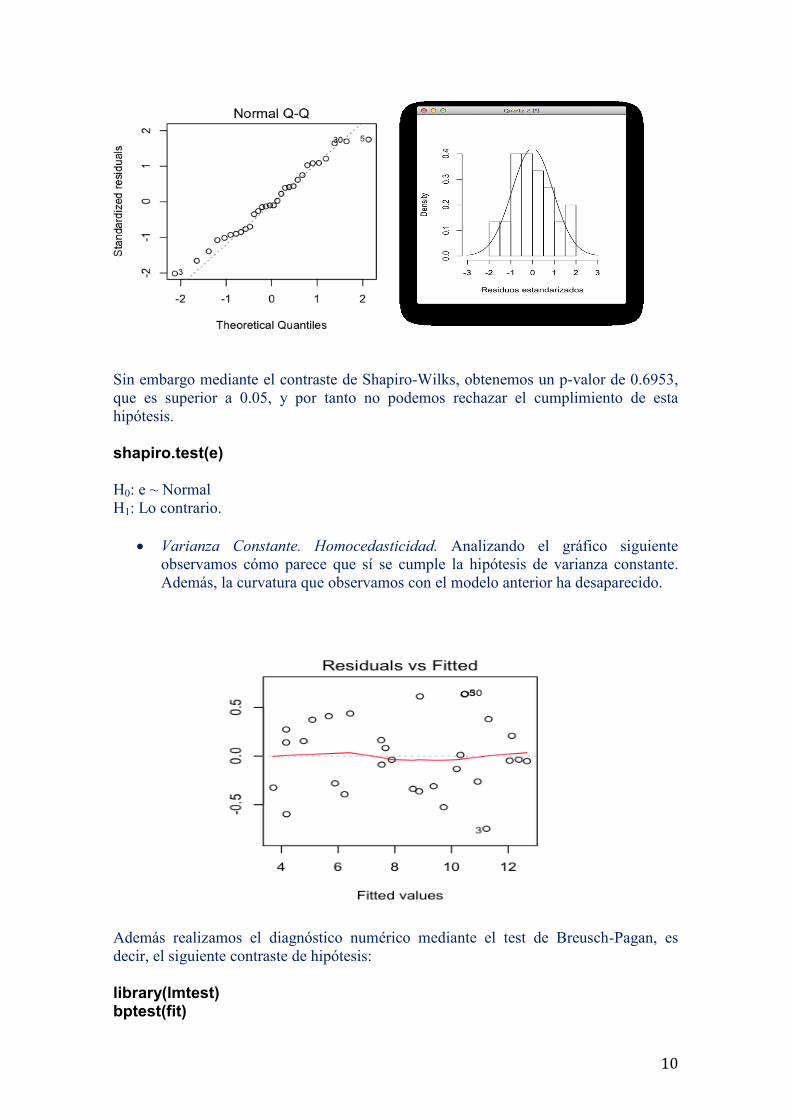
La hipótesis de normalidad. Según el gráfico qqplot, las colas que existen en
ambos lados denotan que no se distribuye mediante una distribución normal. El
histograma también presenta cierta desviación con respecto a la simetría que
cabría esperar.
par(mfrow=c(2,2)) plot(fit) e<-residuals(fit) d<-e/sfit$sigma hist(d,probability=T,xlab="Residuo standarizados",main="",xlim=c(-3,3)) d.seq<-seq(-3,3,length=50) lines(d.seq,dnorm(d.seq,mean(d),sd(d)))
10
Sin embargo mediante el contraste de Shapiro-Wilks, obtenemos un p-valor de 0.6953,
que es superior a 0.05, y por tanto no podemos rechazar el cumplimiento de esta
hipótesis.
shapiro.test(e)
H0: e ~ Normal
H1: Lo contrario.
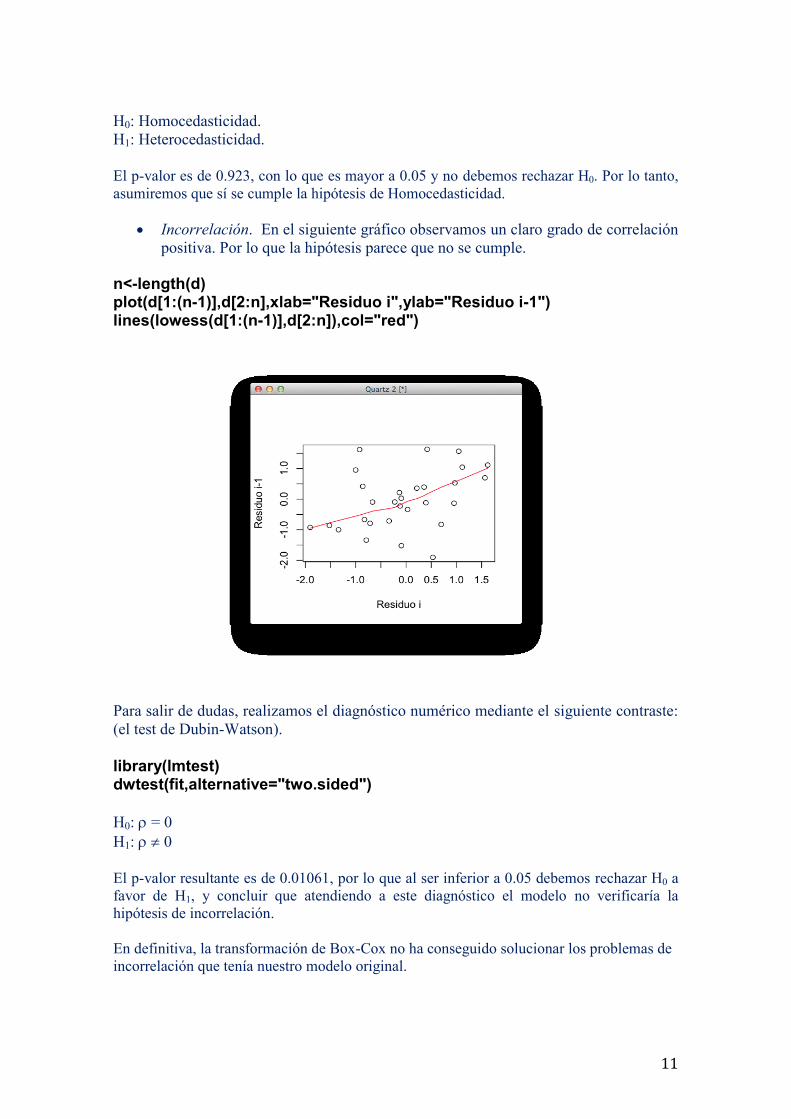
Varianza Constante. Homocedasticidad. Analizando el gráfico siguiente
observamos cómo parece que sí se cumple la hipótesis de varianza constante.
Además, la curvatura que observamos con el modelo anterior ha desaparecido.
Además realizamos el diagnóstico numérico mediante el test de Breusch-Pagan, es
decir, el siguiente contraste de hipótesis:
library(lmtest) bptest(fit)
11
H0: Homocedasticidad.
H1: Heterocedasticidad.
El p-valor es de 0.923, con lo que es mayor a 0.05 y no debemos rechazar H0. Por lo tanto,
asumiremos que sí se cumple la hipótesis de Homocedasticidad.
Incorrelación. En el siguiente gráfico observamos un claro grado de correlación
positiva. Por lo que la hipótesis parece que no se cumple.
n<-length(d) plot(d[1:(n-1)],d[2:n],xlab="Residuo i",ylab="Residuo i-1") lines(lowess(d[1:(n-1)],d[2:n]),col="red")
Para salir de dudas, realizamos el diagnóstico numérico mediante el siguiente contraste:
(el test de Dubin-Watson).
library(lmtest) dwtest(fit,alternative="two.sided")
H0: = 0
H1: 0
El p-valor resultante es de 0.01061, por lo que al ser inferior a 0.05 debemos rechazar H0 a
favor de H1, y concluir que atendiendo a este diagnóstico el modelo no verificaría la
hipótesis de incorrelación.
En definitiva, la transformación de Box-Cox no ha conseguido solucionar los problemas de
incorrelación que tenía nuestro modelo original.

12
Pregunta 5. Utiliza el procedimiento secuencial paso a paso (ligado al criterio AIC) para determinar
el mejor modelo posible a partir del MODELO FINAL.
Step(fit)
Obtenemos un valor AIC de inicio de -52.373.
Dado que todos los valores AIC para el caso de eliminar cualquiera de las tres
covariables son superiores al AIC de referencia, concluimos que todas las variables
explicativas son importantes para explicar el modelo, sin eliminar por tanto ninguna de
ellas.
Pregunta 6. La empresa decide utilizar el MODELO FINAL para estimar el precio de venta de un
piso de nueva construcción. Las características de dicha vivienda y del contexto
económico del momento son las siguientes: m2=89, euribor= 3.64%, precio medio del
barrio = 155. Obtén dicha estimación de forma puntual y por intervalo de confianza al
95%.
m2.0=89 euribor.0=3.64 pmbarrio.0=155 pv.0=predict(fit,data.frame(m2=m2.0,euribor=euribor.0,pmb arrio=pmbarrio.0),interval="prediction");pv.0
La estimación puntual del precio de un piso de nueva construcción con las
características citadas anteriormente es de 8.3672 unidades.
Por otra parte, el precio de venta de esa nueva vivienda estará entre 7.5466 y 9.1878
unidades, a un nivel de confianza del 95%.
Pregunta 7. Determina intervalos de confianza al 95% para los parámetros del MODELO FINAL
(Si lo hiciste en la pregunta 4, entonces simplemente escribe de nuevo los intervalos de
confianza e interprétalos).
confint(fit) IC 95% 0 ……… (-1.23643, 1.69464) IC 95% m2 ……… (0.00826, 0.02687)
IC 95% euribor …. (-0.55273, -0.02006)
IC 95% pmbarrio .. (0.04678, 0.052079)
Los distintos intervalos de confianza nos indican los valores entre los que pueden estar comprendidos los distintos parámetros con un 95% de confianza. Por

13
ejemplo, el valor del coeficiente asociado a m2, beta 1, se encuentra entre 0.00826 y
0.02687, a un nivel de confianza del 95%.


















