Anwendung statistischer Verfahren zur hydrologischen ... · PDF filei,j Element in i-ter Zeile...
123
Friedrich - Schiller - Universit¨ at Fakult¨ at f¨ ur Mathematik und Informatik Anwendung statistischer Verfahren zur hydrologischen Modellierung in verschiedenen Th ¨ uringer Einzugsgebieten Diplomarbeit vorgelegt von Christian Fischer geboren am 12.09.1983 in Erfurt. Betreuer: Prof. Dr. Clemens Beckstein Dr. Sven Kralisch Jena, den 12. Januar 2008
Transcript of Anwendung statistischer Verfahren zur hydrologischen ... · PDF filei,j Element in i-ter Zeile...

Friedrich - Schiller - UniversitatFakultat fur Mathematik und Informatik
Anwendung statistischerVerfahren zur hydrologischenModellierung in verschiedenen
Thuringer Einzugsgebieten
Diplomarbeit
vorgelegt von Christian Fischergeboren am 12.09.1983 in Erfurt.
Betreuer: Prof. Dr. Clemens BecksteinDr. Sven Kralisch
Jena, den 12. Januar 2008

Danksagung
Danken mochte ich Dr. Sven Kralisch und Prof. Dr. Clemens Beckstein, diemir stets in allen Anliegen unterstutzend zur Seite standen. Mein Dank giltauch Prof. Dr. Flugel und den Mitarbeitern am Lehrstuhl fur Geoinformatik,Geohydrologie und Modellierung in Jena fur die Unterstutzung, hilfreichenRatschlage und fur die Bereitstellung der hydrologischen Daten. Bei FranzikaZander und Gunther Hildebrandt mochte ich mich fur das Korrekturlesender Arbeit und fur die hilfreichen Anmerkungen bedanken. Dank gebuhrtauch meinen Freunden und meiner lieben Freundin Anja Haußen, die michstets unterstutzt haben und mir tatkraftig zur Seite standen. Zu guter Letztmochte ich meinen Eltern und meiner Familie danken, die mir das Studiumder Informatik und damit auch diese Diplomarbeit erst ermoglicht haben.
1

2

Inhaltsverzeichnis
1 Einfuhrung 9
2 Problemstellung 132.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.1 Komponenten des Wasserkreislaufes . . . . . . . . . . . 142.1.1.1 Niederschlag . . . . . . . . . . . . . . . . . . 142.1.1.2 Verdunstung . . . . . . . . . . . . . . . . . . 142.1.1.3 Wasserspeicher . . . . . . . . . . . . . . . . . 152.1.1.4 Wasserabfluss . . . . . . . . . . . . . . . . . . 162.1.1.5 Zusammenfassung . . . . . . . . . . . . . . . 17
2.1.2 Modellklassen . . . . . . . . . . . . . . . . . . . . . . . 182.2 Problemformalisierung . . . . . . . . . . . . . . . . . . . . . . 212.3 Auswahl der Eingabedaten . . . . . . . . . . . . . . . . . . . . 24
3 Methoden 293.1 Gaußprozessregression . . . . . . . . . . . . . . . . . . . . . . 29
3.1.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . 293.1.2 Kovarianzfunktionen . . . . . . . . . . . . . . . . . . . 33
3.1.2.1 Quadratisch exponentielle Kovarianzfunktion 343.1.2.2 Kovarianzfunktionen der Matern Klasse . . . 343.1.2.3 Rational quadratische Kovarianzfunktion . . . 353.1.2.4 Neuronale Netzwerk Kovarianz Funktion . . . 363.1.2.5 Neue Kovarianzfunktionen generieren . . . . . 37
3.1.3 Charakteristische Langenskalierung . . . . . . . . . . . 373.1.4 Parameteroptimierung . . . . . . . . . . . . . . . . . . 38
3.1.4.1 Marginal likelihood (ML) . . . . . . . . . . . 393.1.4.2 Leave One Out - Kreuzvalidierung (LOO - CV) 403.1.4.3 Gradientenabstieg . . . . . . . . . . . . . . . 42
3.1.5 Modellierung der Erwartungswertfunktion . . . . . . . 433.2 Mehrschichtige Perzeptronennetze . . . . . . . . . . . . . . . . 44
3.2.1 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . 44
3

4 INHALTSVERZEICHNIS
3.2.2 Backpropagation Lernverfahren . . . . . . . . . . . . . 493.2.3 Mehrschichtige Perzeptronennetze als universelle Ap-
proximatoren . . . . . . . . . . . . . . . . . . . . . . . 503.2.4 Probleme . . . . . . . . . . . . . . . . . . . . . . . . . 513.2.5 Losungsmoglichkeiten . . . . . . . . . . . . . . . . . . . 543.2.6 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3.3 Validierungsverfahren . . . . . . . . . . . . . . . . . . . . . . . 573.3.1 Kreuzvalidierung . . . . . . . . . . . . . . . . . . . . . 573.3.2 Fehlermaße . . . . . . . . . . . . . . . . . . . . . . . . 57
4 Vorstellung der Untersuchungsgebiete 614.1 Wilde Gera . . . . . . . . . . . . . . . . . . . . . . . . . . . . 614.2 Wipper . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.3 Gera . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.4 Roda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5 Anwendung 675.1 Gaußprozessregression . . . . . . . . . . . . . . . . . . . . . . 67
5.1.1 Modellauswahl . . . . . . . . . . . . . . . . . . . . . . 685.1.2 Auswahl von Trainingsbeispielen . . . . . . . . . . . . 695.1.3 Modellevaluation . . . . . . . . . . . . . . . . . . . . . 765.1.4 Erweiterung des Vorhersagezeitraumes . . . . . . . . . 87
5.2 Mehrschichtige Perzeptronennetze . . . . . . . . . . . . . . . . 925.2.1 Modellauswahl . . . . . . . . . . . . . . . . . . . . . . 925.2.2 Modellevaluation . . . . . . . . . . . . . . . . . . . . . 965.2.3 Erweiterung des Vorhersagezeitraumes . . . . . . . . . 102
6 Zusammenfassung und Ausblick 105

Abbildungsverzeichnis
2.1 Wasserkreislauf . . . . . . . . . . . . . . . . . . . . . . . . . . 182.2 Ergebnisfunktionen in Abhanigkeit von a priori Annahmen . . 23
3.1 Quadratisch exponentielle Kovarianzfunktion . . . . . . . . . . 343.2 Matern Kovarianzfunktionen . . . . . . . . . . . . . . . . . . . 353.3 Rational quadratische Kovarianzfunktion . . . . . . . . . . . . 363.4 Vergleich charakteristischer Langen . . . . . . . . . . . . . . . 383.5 Logistische Funktion . . . . . . . . . . . . . . . . . . . . . . . 473.6 Tangens hyperbolicus . . . . . . . . . . . . . . . . . . . . . . . 473.7 Arcustangens . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.8 Backpropagationverfahren konvergiert gegen lokales Minimum 513.9 Backpropagationverfahren stoppt auf Plateau . . . . . . . . . 523.10 Backpropagationverfahren oszilliert . . . . . . . . . . . . . . . 523.11 Backpropagationverfahren verlasst gutes Minimum . . . . . . 533.12 Trainingsfehler und Generalsierungsfehler im Vergleich . . . . 543.13 Beispiel eines Perzeptronennetzes . . . . . . . . . . . . . . . . 563.14 Vorhersagen des Mittelwertmodelles . . . . . . . . . . . . . . . 60
4.1 Einzugsgebiet der Wilden Gera . . . . . . . . . . . . . . . . . 624.2 Einzugsgebiet der Wipper . . . . . . . . . . . . . . . . . . . . 634.3 Einzugsgebiet der Gera . . . . . . . . . . . . . . . . . . . . . . 654.4 Einzugsgebiet der Roda . . . . . . . . . . . . . . . . . . . . . 66
5.1 Vorhersagenfehler . . . . . . . . . . . . . . . . . . . . . . . . . 715.2 Schema der Datennutzung . . . . . . . . . . . . . . . . . . . . 755.3 Gaußprozesse - Ergebnisse Wilde Gera . . . . . . . . . . . . . 805.4 Gaußprozesse - Ergebnisse Gera . . . . . . . . . . . . . . . . . 825.5 Gaußprozesse - Ergebnisse Roda . . . . . . . . . . . . . . . . . 845.6 Gaußprozesse - Ergebnisse Wipper . . . . . . . . . . . . . . . 865.7 Gaußprozesse - Ergebnisse Wilde Gera . . . . . . . . . . . . . 895.8 Gaußprozesse - Ergebnisse Gera . . . . . . . . . . . . . . . . . 90
5

6 ABBILDUNGSVERZEICHNIS
5.9 Gaußprozesse - Ergebnisse Roda . . . . . . . . . . . . . . . . . 905.10 Gaußprozesse - Ergebnisse Wipper . . . . . . . . . . . . . . . 915.11 Auswahl der Topologie . . . . . . . . . . . . . . . . . . . . . . 945.12 Kunstliche neuronale Netze - Ergebnisse Wilde Gera . . . . . 985.13 Kunstliche neuronale Netze - Ergebnisse Gera . . . . . . . . . 995.14 Kunstliche neuronale Netze - Ergebnisse Roda . . . . . . . . . 1005.15 Kunstliche neuronale Netze - Ergebnisse Wipper . . . . . . . . 1015.16 Kunstliche neuronale Netze - Ergebnisse Wilde Gera . . . . . 1035.17 Kunstliche neuronale Netze - Ergebnisse Gera . . . . . . . . . 1035.18 Kunstliche neuronale Netze - Ergebnisse Roda . . . . . . . . . 1045.19 Kunstliche neuronale Netze - Ergebnisse Wipper . . . . . . . . 104

Symbolverzeichnis
Symbol Bedeutung∅ leere MengeN+ Menge der naturliche Zahlen exklusive 0N Menge der naturliche Zahlen inklusive 0R0 reele ZahlenRR Menge der Funktionen die von R nach R abbilden≡ identisch| · | Betrag|| · || euklidische Norm
arg minx
M{
x : x = minx
M}
δi,j Kronecker delta, δi,j = 1 gdw. i = j und 0 sonstAT transponierte MatrixA−1 inverse MatrixI Einheitsmatrix|K| Determinante von K[K]i i-te Zeile von K[K]i,j Element in i-ter Zeile und j-ter Spalte von K∂f∂x
partielle Ableitung von f nach xΓ (ν) Gammafunktionp (x) Wahrscheinlichkeit das x eintrittp (x|y) Bedingte Wahrscheinlichkeit fur x unter yE Erwartungswert∼ verteilt nach
multivariate Normalverteilung mit Erwartungswert µN (µ, Σ)und Kovarianzmatrix Σ
U (l, u) Gleichverteilung auf dem Intervall [l, u)L (x, y) Verlustfunktion
R (x) erwartetes Risiko fur x
7

8 ABBILDUNGSVERZEICHNIS
Symbol BedeutungGP Gaußprozessm (x) Erwartungswertfunktioncov (x, x′) KovarianzfunkzionK oder K (X, X) KovarianzmatrixMSE mittlerer quadratischer FehlerE2 Nash - Sutcliffe EffizienzRSE relativer quadratischer FehlerML marginal likelihood
logarithmierte WahrscheinlichkeitLLOO mit LOO - Kreuzvalidierung
mittlerer quadratischer FehlerLMSE mit LOO - KreuzvalidierungD Menge von Trainingsdatentrel Relevanzzeitraumtpred VorhersagezeitraumQ AbflussS Schneemengep NiederschlagET Verdunstung

Kapitel 1
Einfuhrung
Die zukunftige Entwicklung naturlicher Prozesse abzuschatzen, ist ein Pro-blem, dass die Menschheit bereits seit Jahrtausenden zu losen versucht.Kurzfristige Wetterprognosen, Vorhersagen von Tiden und Pegelstanden undfruhzeitige Katastrophenwarnungen sind nur einige Facetten dieses Proble-mes. Bereits die Babylonier versuchten 650 v. Chr. durch Beobachtung vonWolkenmustern und Planetenstanden das Wetter vorherzusagen (?). Die Agypternotierten sorgfaltig die Pegelstande des Nils, um festzustellen wann die nachsteFlut einsetzen wird und in Asien wurde das Verhalten von Tieren beobachtet,um ein bevorstehendes Erdbeben zu erkennen. Begrundet liegt das Interessean diesen Fragen aber nicht allein in der unstillbaren Neugier des Menschen,sondern vor allem darin, dass der Mensch nur begrenzt Einfluß auf dieseProzesse hat und somit unweigerlich mit den Folgen konfrontiert wird. Vorallem Hochwasserereignisse sind noch immer eine sehr ernst zu nehmendeGefahr. Jahrlich sind etwa 196 Millionen Menschen von Uberschwemmungenbetroffen. Davon kamen allein in den Jahren 1980 bis 2000 weltweit 170.000Menschen ums Leben (UNDP, 2004). Damit sind Uberschwemmungen furetwa die Halfte aller Naturkatastrophenopfer verantwortlich (?). Allein dasElbehochwasser verursachte in Mitteleuropa Schaden in Hohe von 18,5 Milli-arden Euro (?). Diese hatten teilweise durch bessere Warnsysteme vermiedenwerden konnen (?). Es ist daher von großer Bedeutung Hochwasserereignissefruhzeitig und zuverlassig zu prognostizieren. Moderne Methoden sind in derLage diese Aufgabe zu erfullen. Haufig werden hierfur konzeptionelle hydro-logische Modelle (z.B. J2000; ?, PRMS; ?) eingesetzt. Diese Modelle bildendie hydrologischen Prozesse des Einzugsgebietes moglichst exakt nach undermoglichen dadurch eine Prognose der Wassermenge die das Einzugsgebietin einem gewissen Zeitraum verlassen wird. Mit dieser Abflussvorhersage istes moglich direkt auf den zu erwartenden Pegelstand zu schließen und so-mit eine potentielle Hochwassergefahr zu erkennen (?). Trotzdem besteht
9

10 KAPITEL 1. EINFUHRUNG
im Bereich dieser Aufgabe Forschungsbedarf. Der Einsatz komplexer kon-zeptioneller Modelle ist mit aufwandigen und schwierigen Arbeitsschrittenverbunden. Nachteilig ist vor allem, die Notwendigkeit einer detaillierten Re-prasentation des Einzugsgebietes auf dessen Grundlage das konzeptionelleModell arbeiten kann. Fur die Erstellung dieser Reprasentation wird einegroße Menge von Daten benotigt, deren Beschaffung mit hohen Aufwand,Schwierigkeiten und hohen Kosten verbunden ist. Meist besitzen diese Mo-delle außerdem einige Parameter deren Messung direkt nicht moglich ist unda posteriori durch Modellkalibrierungen geschatzt werden mussen. Diese Ei-genschaften konzeptioneller Modelle limitieren ihren Einsatz im Bereich derHochwasservorhersage. Wunschenswert sind daher Verfahren die ahnlich si-chere Prognosen ermoglichen, aber wesentlich einfacher eingesetzt werdenkonnen. Eine mogliche Antwort auf diesen Bedarf liefern statistische Model-le. Diese Modelle versuchen nicht die hydrologischen Prozesse nachzubilden,sondern fassen das Problem der Abflussvorhersage als rein funktionalen Zu-sammenhang zwischen Eingabegroßen (z.B. Niederschlag, Temperatur) undder Ausgabegroße Abflussmenge auf. Ziel dieser Verfahren ist die Rekonstruk-tion dieses funktionalen Zusammenhanges mit statistischen Regressionsver-fahren allein mit Hilfe statistischer Eigenschaften von Beobachtungen. AufGrund dieser Vorgehensweise entfallt sowohl die komplizierte Modellierungdes Einzugsgebietes als auch die Beschaffung schwer bestimmbarer Daten.Es ist ausreichend, wenn der Zusammenhang zwischen klimatischen Bedin-gungen und Wasserabfluss haufig genug im Einzugsgebiet beobachtet wurde.Nicht zuletzt aus diesem Grund haben statistische Verfahren in der Hydrolo-gie eine lange Tradition. Erste Anwendungen gab es bereits von ?. Zu einemrasanten Anstieg der Forschungsaktivitat hat der Einsatz kunstlicher neuro-naler Netze seit etwa 1993 gefuhrt. Erstmals standen universell einsetzbarestatistische Modelle zur Verfugung, die in Bezug auf ihre Genauigkeit mitden traditionellen Ansatzen konkurrieren konnten (???????). Neuere Ver-fahren der Regressionsanalyse nutzen die Technik der
”Kernel Machines“,
deren bekanntester Vertreter wohl die Support Vektor Machschine ist (?).Ein weiteres sehr interessantes Verfahren aus dieser Verfahrensklasse ist dieGaußprozessregression. Diese stellt einen universellen und praktischen An-satz zum Lernen mit
”Kernel Maschinen“ dar. Durch ein solides statisti-
sches Fundament birgt das Lernen mit Gaußprozessen Vorteile bezuglich derInterpretation von Modellvorhersagen. Jedoch wurden diese Verfahren bis-her kaum im hydrologischen Kontext verwendet. Anliegen der vorliegendenArbeit ist deshalb der Vergleich der Gaußprozessregression mit kunstlichenneuronalen Netzen in der Anwendung der kurzfristigen Abflussvorhersage alsHochwasserwarnung.

Kapitel 2
Problemstellung
In dem einfuhrenden Kapitel wurde das Problem der hydrologischen Ab-flussmodellierung vorgestellt. Es wurde das Ziel gesetzt zwei statistische Ver-fahren auf diese Problemstellung anzuwenden und zu vergleichen. Inhalt die-ses Kapitels ist die Konktretisierung, Formalisierung und Analyse der Pro-blemstellung, sowie die Vorstellung von verschiedenen Losungsansatzen.
2.1 Grundlagen
Fur die weiteren Betrachtungen ist die Erarbeitung eines grundlegendenVerstandnisses uber den Wasserhaushalt eines Einzugsgebietes unerlaßlich.An dieser Stelle werden daher zunachst einige hydrologische Grundlagen dar-gestellt.
Definition 2.1.1 (Allgemeine Wasserhaushaltsgleichung)Der Wasserhaushalt in einem gegebenen abgeschlossenen Gebiet lasst sichnach ?, fur einen abgeschlossenen Zeitraum, durch die Allgemeine Wasser-haushaltsgleichung
P = E + Q + ∆S
beschreiben. Dabei ist:
• Niederschlag P
• Verdunstung E
• Wasservorratsanderung ∆S
• Abfluss Q
11

12 KAPITEL 2. PROBLEMSTELLUNG
2.1.1 Komponenten des Wasserkreislaufes
Im Folgenden werden die einzelnen Komponenten dieser Gleichung betrach-tet.
2.1.1.1 Niederschlag
Niederschlag ist nach DIN (1996) das Wasser der Atmosphare, das nach Kon-densation oder Sublimation von Wasserdampf in der Lufthulle ausgeschiedenwurde und sich infolge der Schwerkraft entweder zur Erdoberflache bewegt(fallender Niederschlag) oder auf die Erdoberflache gelangt ist (gefallenerNiederschlag). Niederschlag kann zum einen in flussiger Form auftreten, zumBeispiel als Regen, Tau oder Nebelniederschlag, und zum anderen in festerForm als Schnee, Reif oder Frostbeschlag. Welche Art von Niederschlag auf-tritt, hangt im Wesentlichen von der Temperatur und Vegetation ab. Fur diemeisten Regionen sind Niederschlagsformen wie Tau und Reif quantitativnicht relevant und konnen daher vernachlassigt werden. Im Gegensatz da-zu ist die Menge des gefallenden Niederschlags, wie Regen oder Schnee, diewichtigste Einflussgroße in der hydrologischen Modellierung. ? weisen nach,dass bereits eine zehnprozentige Abweichung in der Niederschlagsmenge ei-ne 35%ige Veranderung des Abflusses bewirken kann. Diese Beobachtung istvon besonderer Bedeutung, da in der Niederschlagsmessung maximale syste-matische Fehler von 9 - 30% festzustellen sind (?). Neben der Niederschlags-menge hat auch die Verteilung des Niederschlages wesentlich Einfluss auf denAbfluss (?). Daher ist ein ausreichend dichtes Netz an Niederschlagsmesssta-tionen wichtig. Eine raumlich hoch aufgeloste Messung des Niederschlagesermoglicht der Einsatz von Radarmessstationen (??).
2.1.1.2 Verdunstung
Die Verdunstung ist der Vorgang bei dem Wasser bei Temperaturen unterdem Siedepunkt vom flussigen oder festen Zustand in den gasformigen Zu-stand (Wasserdampf) uber geht. Es ist moglich zwei Arten der Verdunstungzu unterscheiden. Die direkte Verdunstung von Wasser uber freier Boden-oder Wasseroberflache, wird Evaporation genannt. Die Wasserverdunstungauf Pflanzenoberflachen wird als Transpiration bezeichnet. Oftmals wird Eva-poration und Transpiration unter dem Begriff der Evatranspiration zusam-mengefasst. Dabei lasst sich weiter untergliedern in aktuelle und potentiel-le Evatranspiration. Letzteres bezeichnet die maximal mogliche Gesamtver-dunstung unter der Voraussetzung, dass unbegrenzt viel Wasser vorhandenist. Direkte Messverfahren fur die aktuelle bzw. potentielle Evaporation und

2.1. GRUNDLAGEN 13
Transpiration sind sehr ungenau und lassen sich deshalb nur begrenzt ein-setzen (?). Deshalb wird die potentielle Verdunstung indirekt nahrungsweisebestimmt. Ubliche Verfahren hierfur sind unter anderem das Verfahren nachHaude (?), Verfahren nach Thornthwaite (?), Verfahren nach Renger & Wes-solek (?) sowie das komplexe Penman-Monteith-Modell (?), welches hier ver-wendet wird. Nach diesem Modell gilt fur die potentielle Verdunstung ETα:
ETα =1
L∗ ·s · (Rn −G) + ρ·cp
ra· (es (T )− e)
s + γ ·(1 + rs
ra
) (2.1)
Dabei ist:
L∗ spezifische Verdunstungswarme fur 1 mm Verdunstungshohes Steigung der Sattigungsdampfdruckkurve
Rn StrahlungsbilanzG Bodenwarmestromρ Luftdichtecp spezifische Warmekapazitat der Luftra aerodynamischer Widerstand
Sattigungsdefizit, abhangig von Lufttemperatur Tes (T )− e
und Dampfdruck eγ Psychrometerkonstanters Stomatawiderstand
Ei-
nige der fur die Berechung notwendigen Großen sind ebenfalls nicht oderschwer direkt messbar. Es ist aber moglich diese Großen indirekt aus Mess-werten der Temperatur, Sonneneinstrahlung, Windgeschwindigkeit und Luft-feuchte zu bestimmen.
2.1.1.3 Wasserspeicher
Der Wasservorrat eines Einzugsgebietes setzt sich zusammen aus:
• InterzeptionDamit wird das vorubergehende Speichern von gefallenem oder abge-setztem Niederschlag an Pflanzenoberflachen bezeichnet. Von dort ver-dunstet das Wasser teilweise sofort wieder oder es tropft bzw. lauftzum Erdboden ab. Zwischen vegetationsbedeckten und vegetationslo-sen Gebieten kann ein deutlicher Unterschied, bezuglich des den Bodenerreichenden Niederschlagsanteils, bestehen. Eine analytische mathe-matische Beschreibung ist kaum moglich (?).

14 KAPITEL 2. PROBLEMSTELLUNG
• Schnee und Eis
• Wasservorrat in stehenden Gewassern
• BodenwasserJeder Boden enthalt unter naturlichen Bedingungen Wasser. Ein Teildessen bewegt sich durch die Schwerkraft abwarts, das sogenannteSickerwasser. Dieser Bewegungsvorgang wird Perkolation genannt. Dasrestliche Wasser ist in den Bodenporen gebunden und wird mit Haft-wasser bzw. Bodenfeuchte bezeichnet. Die Form des Bodens hat großenEinfluß auf die maximale Menge des Haftwassers.
• GrundwasserDabei handelt es sich um unterirdisches Wasser, das die Hohlraumeder Lithosphare zusammenhangend ausfullt und dessen Bewegungs-moglichkeiten ausschließlich durch die Schwerkraft bestimmt werden.
2.1.1.4 Wasserabfluss
Der Wasserabfluss spielt in dieser Arbeit eine besonders große Rolle, da ge-rade uber diese Komponente Aussagen getroffen werden sollen. Dieser wirdvon ? wie folgt definiert:
”Unter dem Abfluss versteht man in der Hydrologie das Was-
servolumen, das pro Zeiteinheit einen definierten oberirdischenFließquerschnitt (Abflussquerschnitt) durchfließt.“
Abfluss entsteht auf verschiedene Arten. Trifft Niederschlag auf eine nichtversiegelte Oberflache, sickert er in den Boden ein. Die Geschwindigkeit diesersogenannten Infiltration ist von verschiedenen Bodenparametern abhangig.Ubersteigt die Niederschlagsmenge die Aufnahmefahigkeit des Bodens, sofließt das uberschussige Wasser an der Oberflache ab. Man spricht von Ober-flachenabfluss, welcher einen großen Anteil am Gesamtabfluss haben kann.Ein Teil des versickerten Wassers gelangt in das Grundwasser und tragt damitzur Grundwasserneubildung bei. Grundwasser kann an Quellen und durchkapillar aufsteigendes Wasser wieder an die Oberflache gelangen und einenBeitrag zum Abfluss leisten. Doch nicht die gesamte Menge des versicker-ten Wassers gelangt in das Grundwasser. Vor allem bei starken Regenfallenkommt es bei dem im Boden befindlichen Wasser zu hangparallelen Fließ-bewegungen. Dies wird Interflow genannt. Auf diese Weise kann versickertesWasser in den Vorfluter gelangen ohne Kontakt mit dem Grundwasser gehabtzu haben (?).

2.1. GRUNDLAGEN 15
Zur Messung des Abflusses existieren verschiedene Verfahren. So kann derAbfluss unter anderem durch Pegel-, Geschwindigkeits- und Ultraschallmes-sungen bestimmt werden (?). Die Darstellung der beobachteten Abflusse ent-sprechend ihres zeitlichen Auftretens wird Abflussganglinie genannt. Sie setztsich zusammen aus dem direkten Abfluss und dem Basisabfluss. Unter demdirekten Abfluss wird die Wassermenge verstanden, die mit geringer Zeit-verzogerung den Vorfluter erreicht und vornehmlich aus Oberflachenabflussund Interflow gebildet wird. Demgegenuber ist der Basisabfluss diejenigeWassermenge, die den Vorfluter mit erheblicher Zeitverzogerung erreicht.Er besteht im Wesentlichen aus dem abfließenden Wasser des Grundwas-serkorpers.
2.1.1.5 Zusammenfassung
In Abbildung ?? sind die Beziehungen zusammenfassend dargestellt. In Ta-belle ?? werden noch einmal alle Faktoren aufgelistet, die direkten Einflussauf den Abfluss haben (?) und dabei unterteilt nach Faktoren, die sich uberdie Zeit nicht oder selten andern und somit nur vom Einzugsgebiet abhangenund solche die zeitabhanig sind.
zeitlich konstantezeitlich veranderliche Großen
GroßenNiederschlagsmenge Bodenform
Anderung der gespeicherten Wassermengegefrorene WassermengeBodenwasser und BodenfeuchteWassermenge in stehenden GewassernGrundwassermenge
Bodenart
potentielle VerdunstungTemperaturStrahlungsintensitat und -dauerWindVegetation
Relief
Vegetation
Tabelle 2.1: Unterteilung der abflussrelevanten Faktoren nach zeitlicherVeranderung

16 KAPITEL 2. PROBLEMSTELLUNG
Abbildung 2.1: Wasserkreislauf,Quelle: http://www.waterprotection.ca
2.1.2 Modellklassen
Prinzipiell konnen Modelle zur Abflussvorhersage in eine von drei Klasseneingeteilt werden (?). Dies sind deterministische, konzeptionelle und statisti-sche Modelle. Im Folgenden soll ein Uberblick uber diese drei Klassen gegebenwerden.
Statistische Modelle Modelle dieser Klasse weisen keinen physikalischfundierten Zusammenhang zwischen Eingabegroßen und Ausgabegroßen auf,sondern arbeiten auf rein statistischer Grundlage. Statistische Modelle bietenkaum Einblick in das zugrunde liegende physikalische System des Einzugs-gebietes, da derartige Informationen in diesem Modell implizit verarbeitetwerden. Diese Modelle sind daher auch unter dem Begriff der Black - BoxModelle bekannt. Verfahren dieser Art haben im hydrologischen Einsatz ei-ne lange Tradition. Bereits Sherman hat 1932 mit der Einheitsganglinie einanalytisches Modell fur die Abflussvorhersage entworfen (?). Nash & Sutcliffeverallgemeinerten diesen Ansatz 1970 (?). Heute existieren zahlreiche Model-le, die kunstliche neuronale Netze fur hydrologische Vorhersagen einsetzen(???????). In den letzten Jahren hat sich dieses Modellkonzept wachsen-der Beliebtheit (?) erfreut. Ein Grund dafur ist, dass sich diese Modelle mitgeringem Aufwand prinzipiell in jedem Einzugsgebiet einsetzen lassen. Furdie Anwendung sind lediglich ausreichend viele Beobachtungen des funktio-

2.1. GRUNDLAGEN 17
nalen Zusammenhanges zwischen Ein- und Ausgabegroßen notwendig. Eineaufwandige und zeitraubende Modellierung sowie eine zusatzliche Modell-kalibrierung entfallt. Es sind jedoch die Bedingungen zu stellen, dass jederauftretbare Zustand des Einzugsgebietes durch Beobachtungen abgedeckt istund alle abflussrelevanten Faktoren beobachtet wurden. Beispiele, in denendiese Bedingungen verletzt sind, kommen in Extremsituationen vor. Dabeiwerden Vorhersagen weit außerhalb des Gebietes der bekannten Daten ge-troffen (Extrapolation). Somit beruhen Vorhersagen in diesem Bereich aus-schließlich auf mathematischer Technik und sind von zweifelhaften Wert. ?gehen genauer auf diese Problematik ein. Ein anderes Beispiel in dem dieseBedingung Probleme bereitet, ist der Bau einer Talsperre. Die Beobachtun-gen, die vor der Errichtung der Talsperre gemacht wurden, konnen nichtmehr verwendet werden, da sich der Zustand des Einzugsgebietes wesentlichverandert hat. Die Folge davon ist, dass ein statistisches Modell aus neu-en Beobachtungen erzeugt werden muss. Dies ist insofern problematisch, dastatistische Verfahren fur die Erstellung eines Modelles oftmals mehrere tau-send Datensatze benotigen (?). Werden Zeitreihen auf Tagesbasis betrach-tet, so sind Messdaten uber einen Zeitraum von 10 - 30 Jahren erforderlich.Da immer mehr Einzugsgebiete derartigen Veranderungen unterliegen, limi-tiert dies den Einsatz von statistischen Modellen. Sind aber ausreichend vieleBeobachtungen vorhanden, so haben fruhere Arbeiten gezeigt, dass statisti-sche Verfahren sehr prazise Vorhersagen mit einem Minimum an Aufwandermoglichen. Die vorliegende Arbeit beschaftigt sich mit kunstlichen neu-ronalen Netzen und der Gaußprozessregression. Kunstliche neuronale Netzewerden bereits seit einiger Zeit in diesem Bereich sehr erfolgreich eingesetzt,wahrend Gaußprozesse bisher wenig Beachtung in diesem Umfeld gefundenhaben.
Physikalische Modelle Physikalische Modelle beschreiben das naturlicheSystem mit Hilfe einer mathematischen Reprasentation der physikalischenVorgange. Charakteristisch fur diese Modellklasse ist, dass alle Modellkom-ponenten direkte physikalische Signifikanz haben. Insbesondere ist es prinzi-piell moglich alle Modellparameter durch Messungen zu bestimmen. Nach-teilig ist, dass es selbst bei vereinfachenden Annahmen notwendig ist großeDifferentialgleichungen zu losen. Die Losung dieser Gleichungen benotigt imAllgemeinen riesige Mengen Rechenzeit und Speicherplatz. Außerdem sindfur die Erstellung des Modells sehr große Mengen von Daten erforderlich,deren Beschaffung enorm schwierig und kostspielig ist. Daher sind physikali-sche Modelle in der praktischen Anwendung kaum von Bedeutung. Trotzdembietet der rein physikalische Ansatz tiefe Einblicke in das hydrologische Sy-

18 KAPITEL 2. PROBLEMSTELLUNG
stem und ermoglicht sehr genaue Aussagen. Aus diesem Grund werden dieseModelle manchmal als White - Box Modelle bezeichnet. Außerdem ist dieModellierung von Veranderungen des Einzugsgebiets moglich. Beispiele furphysikalisch-basierte Modelle sind SHE (?) und IHDM (?).
Konzeptionelle Modelle Konzeptionelle Modelle sind in einem nicht klarabgegrenzten Bereich zwischen statistischen und physikalischen Modelleneinzuordnen und werden deshalb auch als Grey - Box Modelle bezeichnet.Gewohnlich lassen sich diese Modelle als Vereinfachung des physikalischenSystems auffassen. Durch sie ist es moglich mit relativ geringem Rechen-aufwand Simulationen durchzufuhren und Aussagen uber die hydrologischenVorgange eines Einzugsgebietes zu treffen. In einem konzeptionellen Modellwerden physikalisch korrekte Strukturen und Gleichungen zusammen mitempirischen Komponenten verwendet, deren physikalische Bedeutung un-klar ist. Somit konnen nicht alle Modellparameter durch direkte Messunggewonnen werden und mussen statt dessen durch eine zusatzliche zum Teilaufwandige Parameterschatzung bestimmt werden. Dazu werden Eingabe-zeitreihen auf das Modell angewendet und die Modellparameter so lange an-gepasst, bis eine moglichst große Ahnlichkeit zwischen den Modellausgabenund den zugehorigen Ausgabezeitreihen erreicht wird. Dieser Prozess wirdModellkalibrierung genannt. Dies macht es erforderlich, dass neben raumlichaufgelosten Daten (z.B. Bodenform, Relief) auch eine gewisse Menge an hi-storischen Messwerten vorhanden ist. Tabelle ?? fasst die charakteristischenEigenschaften der vorgestellten Modellklassen zusammen. Es ist anzumer-ken, dass hydrologische Modelle auch nach anderen Gesichtspunkten klassi-fiziert werden konnen. Beispielsweise ist eine Unterscheidung nach determi-nistischen und stochastischen Modellen moglich. An dieser Stelle sind dieseKlassifikationsformen aber nicht relevant und sollen daher nicht beschriebenwerden.Das Ziel der vorliegenden Arbeit ist es statistische Modelle fur kurzfristi-ge Abflussvorhersagen einzusetzen. Dabei wird gefordert, dass diese Modellemoglichst universell fur jedes Einzugsgebiet eingesetzt werden konnen, dieVerwendung auch bei schlechter Datenlage moglich ist und der Aufwand furdie Modellerstellung gering ist.In der vorliegenden Arbeit werden mehrschichtige Perzeptronennetze und
Gaußprozessregression verwendet. Beide Ansatze sind potentiell in der Lagedie Forderungen zu erfullen. Im Verlauf dieser Arbeit werden die Verfahrenmiteinander verglichen und ihre Eigenschaften dargestellt.

2.2. PROBLEMFORMALISIERUNG 19
Statistisch Konzeptionell Physikalisch(Black Box) (Grey Box) (White Box)
Modell- empirischkonzept
rein empirischphysikalisch
physikalisch
viele historische raumlich verteilte hoher Bedarf anBeobachtungen Daten und einige raumlich
(>2.500) historische verteilten DatenDatenbedarf
BeobachtungenErstellungs- niedrig, nahezu hoch, manuelle hoch, manuelle
aufwand automatisiert Eingriffe notig Eingriffe notigAbleitbarkeit gering nur hoch, viele rauml. sehr hoch, nahezuvon Aussagen Ausgabegroße Aussagen transparent
Einheitsgangline J2000 SHEBeispiele
KNNs PRMS/MMS IDHM
Tabelle 2.2: Eigenschaften hydrologischer Modellklassen
2.2 Problemformalisierung
Es wird nun eine formale Beschreibung der Problemstellung angegeben:
Definition 2.2.1 (Regressionsproblem)Es sei B ⊂ Rd ein Bereich und f : B → R eine unbekannte Funktion, dieeinen Zusammenhang zwischen Messwerten x ∈ B und Beobachtungen y ∈ Rherstellt und zwar in dem Sinn, dass gilt:
y = f (x) + ε
Dabei ist ε eine zufallig auftretende Storung, die einer Wahrscheinlichkeits-dichte Θ folgt. Es sei außerdem eine Menge D bekannt, die Beispiele dieses(verfalschten) Zusammenhanges beinhaltet
D = {(xi, yi) : i = 1, 2 . . . , N}
Gesucht ist eine Funktion f (x), die f (x) moglichst gut approximiert.
Nun stellt sich unweigerlich die Frage, was als eine moglichst gute Appro-ximation definiert werden kann. Dazu existiert eine Vielzahl von moglichenZugangen. An dieser Stelle soll das erwartete Risiko R eingefuhrt werden,welches vor allem in der statistischen Entscheidungstheorie Verwendung fin-det.

20 KAPITEL 2. PROBLEMSTELLUNG
Definition 2.2.2 (Erwartetes Risiko)Als Risiko wird gewohnlich das Produkt aus der Wahrscheinlichkeit einesEreignisses und dem bei Auftreten des Ereignisses entstehenden Verlustesdefiniert. Definiert man fur einen Punkt x∗ den Schatzwert yguess := f (x∗)und sei yreal, mit einer gewissen Wahrscheinlichkeit, der echte Wert, so istdas Risiko fur yguess unter einer Verlustfunktion L definiert als:
L (yreal, yguess) · p (y|x∗, D)
Das erwartete Risiko R erhalt man nun durch Erwartungswertbildung uberyreal.
RL (yguess|x) =
∫L (yreal, yguess) · p (yreal|x, D) dyreal
Mit dieser Formalisierung ist die optimale Schatzung yopt, genau der Wert,der das erwartete Risiko minimiert:
yopt = infyguess
RL (yguess|x)
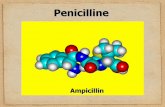
Sofern die Wahrscheinlichkeitsverteilung von p (y|x, D) bekannt ist, kann deroptimale Schatzwert yopt in den meisten Fallen ohne große Probleme be-stimmt werden. Die Schwierigkeit besteht darin, eine angemessene Vertei-lung p (y|x, D) anzugeben. Um diese Aufgabe anzugehen, ist es zwingendnotwendig, a priori Annahmen uber die unbekannte Funktion f zu treffen.Anderenfalls ist jede Funktion als Wahl von f gleich wahrscheinlich, solangesie nur mit den Beispieldatensatzen aus D konsistent ist. Um dies zu ver-deutlichen wird ein eindimensionales Regressionsproblem betrachtet, in demeine Beispielmenge D mit funf Punkten gegeben ist (Abbildung ??). Suchtman nach einer Approximationsfunktion ohne vorher Einschrankungen zutreffen, kommt beispielsweise die Funktion aus Abbildung ?? in Betracht.Es sollte somit zumindest Stetigkeit der Funktion f verlangt werden. EinBlick in Abbildung ?? zeigt deutlich, dass dies wohl noch nicht genug ist.In einem nachsten Versuch kann Stetigkeit der Ableitung gefordert werden (Abbildung ??) oder angenommen werden, dass es sich bei f um eine lineareFunktion handelt (Abbildung ??).
Allgemein gibt es zwei ubliche Ansatze fur derartige Beschrankungen. Dererste besteht darin die Klasse der Funktionen, die uberhaupt berucksichtigtwerden, einzuschranken. Beispielsweise konnte angenommen werden, dasszwischen Ein- und Ausgabe der Funktion f ein linearer Zusammenhangbesteht. Auf diese Weise entsteht ein einfaches lineares Regressionsmodell.Dieser Ansatz kann leicht auf polynomielle Basisfunktionen verallgemeinert
2.2. PROBLEMFORMALISIERUNG 21
0
1
2
3
4
5
6
0 1 2 3 4 5 6
(a)
0
1
2
3
4
5
6
0 1 2 3 4 5 6
(b)
0
1
2
3
4
5
6
0 1 2 3 4 5 6
(c)
0
1
2
3
4
5
6
0 1 2 3 4 5 6
(d)
0
1
2
3
4
5
6
0 1 2 3 4 5 6
(e)
Abbildung 2.2: Mogliche Ergebnisfunktionen des Regressionsproblemes inAbhanigkeit von a priori Annahmen
werden, womit man bereits ein etwas komplexeres lineares Regressionsmo-dell erhalt. Auch kunstliche neuronale Netze lassen sich in diese Kategorieeinordnen, ob gleich die erlaubten Funktionen eine deutlich kompliziertereGestalt aufweisen und sehr flexibel sind. Ein generelles Problem dieses An-satzes entsteht, wenn f mit den erlaubten Funktionen nicht hinreichend gutapproximiert werden kann. Man spricht in diesem Zusammenhang von under-fitting. Underfitting ist bei dem Einsatz von kunstlichen neuronalen Netzenausgeschlossen, falls sichergestellt ist, dass das Netz ausreichend viele innereEinheiten besitzt (Abschnitt ??). Auf der anderen Seite entsteht aber auchein Problem, wenn zuviele Basisfunktionen zur Verfugung stehen, so dassdie Freiheitsgrade der Basisfunktionen ausreichend sind um beispielsweiseauftretendes Rauschen nachzubilden. Auf diese Weise konnen Funktionen inBetracht kommen, die schlecht geeignet sind (Abbildung ??). Dies ist auchunter dem Begriff overfitting bekannt.Alternativ kann aber auch ein anderer Weg gewahlt werden. Man betrachtetden gesamten Raum aller moglichen Funktionen und fuhrt dort eine Wahr-scheinlichkeitsdichte ein, indem jeder Funktion a priori eine Wahrscheinlich-keit zugeordnet wird, wobei Funktionen, die man fur besser geeignet halt, einehohere Wahrscheinlichkeit erhalten. Dieser Ansatz erscheint auf den erstenBlick etwas naiv, da der Raum der moglichen Funktionen derartig groß ist,dass man eigentlich keine Chance sieht diese uberabzahlbar große Menge ir-gendwie in den Griff zu bekommen. Erstaunlicherweise liefert der Ansatz der

22 KAPITEL 2. PROBLEMSTELLUNG
Gaußprozessregression eine Antwort auf dieses Problem, solange nur nach Ei-genschaften der Funktion an endlich vielen Stellen gefragt wird. Nach dieserallgemeinen Betrachtung der Losungsmoglichkeiten eines Regressionsproble-mes, werden im nachsten Kapitel ganz konkret zwei Verfahren vorgestellt.
2.3 Auswahl der Eingabedaten
Im vorherigen Abschnitt wurde ein Uberblick uber die hydrologischen Grund-lagen der Problemstellung und Modellklassen zur Losung gegeben. Da in dervorliegenden Arbeit ausschließlich statistische Modelle zum Einsatz kommen,ist es notig zu entscheiden, welche Daten fur diese Modellklasse uberhauptvon Bedeutung sind. Charakteristisch fur statistische Verfahren ist, dass sieausschließlich aus Beobachtungen lernen. Daher ist festzustellen, dass charak-teristische Eigenschaften des Einzugsgebietes fur statistische Modelle nichtrelevant sind. Beispielsweise lassen sich aus der Gebietstopographie keinezusatzlichen Informationen gewinnen. Dies lasst sich dadurch begrunden,dass die Topographie im Untersuchungszeitraum meist konstant ist. Durcheinfache Beobachtungen ist der Einfluß der Topographie somit nicht nach-vollziehbar. Deshalb ist es nicht notig, diese Daten dem Verfahren explizitmitzuteilen. Weitere Großen des Einzugsgebietes, die als zeitlich konstant an-genommen werden, sind Bodenform, Bodenart, Relief und außerdem Quan-titat und Qualitat der Vegetation. Die letzten Annahmen sind diskutabel, davor allem Veranderungen in der landwirtschaftlichen Nutzung zu Vegetati-onsunterschieden fuhren. Der Verzicht auf Landnutzungs- und Vegetations-daten ist dadurch motiviert, dass es sich hierbei um raumlich ausgepragteGroßen handelt, die unter Umstanden nicht zur Verfugung stehen und derenErmittlung aufwandig ist. Dies wurde im Gegensatz zu der Forderung ste-hen, mit moglichst wenig Daten auszukommen. Desweiteren ist es schwierig,raumlich ausgepragte Daten statistisch zu verarbeiten. Durch die große Men-ge an Informationen wird die Dimension der Eingabedaten stark vergroßert.Da es dadurch schwerer wird statistische Zusammenhange festzustellen, mussmit Verfahren zur Dimensionsreduktion entgegen gewirkt werden (?). DieAnderung des Vegetationseinflußes im Jahresverlauf wird beachtet, indem inder Eingabe zumindest Informationen uber die Jahreszeit bereit gestellt wer-den.Außerdem werden alle anderen zeitabhangigen Faktoren aus Abschnitt ??dem Vorhersageverfahren zur Verfugung gestellt, sofern die Datenlage dieszulasst.Es lasst sich noch folgende Uberlegung anstellen: Im Prinzip ist es ver-gleichsweise irrelevant, wie groß die gefrorene Wassermenge im Einzugsge-

2.3. AUSWAHL DER EINGABEDATEN 23
biet ist. Viel wichtiger ist es, wie sich diese Menge verandert. Ist ein deutli-cher Schwund zu verzeichnen, wurde eine große Menge Wasser frei, die danneventuell abflusswirksam wurde. Eine Zunahme andererseits zeigt, dass Nie-derschlag im Einzugsgebiet in gefrorener Form gespeichert und daher nichtabflusswirksam wird. Als Eingabe sollte neben der absolute Schneehohe imGebiet auch die Differenz der aktuellen Schneehohe zu den letzten Vorta-gen bereitgestellt werden. Von Bedeutung ist, dass das Ziel der vorliegendenArbeit nur darin besteht, ein Vorhersagemodell fur kurzfristige Vorhersagenanzugeben, nicht aber die hydrologischen Vorgange uber einen langeren Zeit-raum zu simulieren. Somit ist zum Zeitpunkt der Berechnung der aktuelleAbfluss bekannt und kann ebenfalls als Eingabe genutzt werden. Daraus re-sultiert die Beobachtung, dass die Modelle gar nicht in der Lage sein mussen,die Gesamtmenge des Abflusses zu bestimmen. Es ist vollkommen ausrei-chend zu ermitteln, welche Veranderung sich zwischen dem aktuellen undzukunftigen Stand ergeben wird. Die zu bestimmende Große ist daher dieDifferenz zwischem dem aktuellen und dem zukunftigen Abfluss. Die nach-folgende Definition fasst zusammen, welche Großen ausgewahlt wurden, undlegt gleichzeitig deren Bezeichnung fest.
Definition 2.3.1 (Eingabegroßen)Sei t ∈ [tmin, tmax] ein Zeitpunkt aus einem definierten Zeitintervall und s einPunkt im Einzugsgebiet. Mit tpred ∈ N wird angegeben wie groß der Vorher-sagezeitraum [t, t + tpred] in Zeitschritten ist. Die Differenz des aktuellen zumzukunftigen Abfluss wird mit
∆Q (tpred, t)
bezeichnet. Die ausgewahlten Großen sind:
• Niederschlagsmenge ps,t
• Temperatur Ts,t
• Schneehohe Ss,t
• Veranderung der Schneehohe ∆Sds,t := Ss,t − Ss,t−d mit d = 1, 2, 3
• potentielle Verdunstung ETs,t
• aktueller Durchfluss Qt0 am Bezugspegel
Es ergeben sich nun noch einige Fragestellungen, die geklart werden mussen.
1. In welcher zeitlichen Auflosung sollten die entsprechenden Daten ver-wendet werden?

24 KAPITEL 2. PROBLEMSTELLUNG
2. Wie groß ist der Einfluss von vergangenen Ereignissen auf den zukunft-igen Abfluss und wieviele Zeitschritte trel sollten die Messwerte derEingabe in die Vergangenheit reichen. Der Wert trel wird als Relevanz-zeitraum bezeichnet.
3. Welche Messwerte sollten bei der raumlichen Auswahl berucksichtigtwerden?
4. Welcher Vorverarbeitung sollten die Daten unterzogen werden?
Die erste Frage lasst sich erst bei genauer Kenntnis der Anwendung be-antworten. Beispielsweise ermoglichen stundliche Daten außerst kurzfristi-ge Vorhersagen. Dem gegenuber konnen jahrliche Daten fur die langfristigeTrendmodellierung verwendet werden. Fur die vorliegende Arbeit stehen Da-ten in taglicher Auflosung zur Verfugung. Die zweite Frage lasst sich auchnicht allgemeingultig beantworten, sondern ist individuell fur jedes Einzugs-gebiet zu entscheiden. Es wird deshalb mit verschiedenen Werte von trel ge-arbeitet und dann individuell in jedem betrachteten Einzugsgebiet der besteWert ermittelt. Die nachste Frage entspricht der Problemstellung zu entschei-den, wie relevant die Zeitreihe einer Eingabekomponente fur den Abfluss ist.Kunstliche neuronale Netze nehmen implizit eine Gewichtung der einzelnenEingabekomponenten vor, die dieses Problem lost. Im Bereich der Gaußpro-zesse existieren Methoden, um explizit Relevanzaussagen zu treffen.Bezuglich der letzten Frage ist zu sagen, dass es unvermeidlich ist die Dateneinigen Vorverarbeitungsschritten zu unterziehen, um ein funktionierendesstatistisches Modell zu erhalten. In vielen Bereichen des maschinellen Ler-nens besteht die Datenvorverarbeitung aus einer Vielzahl von teils hochkom-plexen Operationen. Dies erscheint, im Bereich dieser Problemstellung, nichtunbedingt notwendig zu sein. Es ist zu erwarten, dass die Eingabedimension,das heißt die Anzahl der Eingabekomponenten, im Bereich von 10 - 100 liegenwird und daher vergleichsweise klein ist. Diese Erwartung resultiert daraus,dass fur jedes Einzugsgebiet etwa 7-15 Niederschlagszeitreihen, 1-3 Tempe-raturzeitreihen und einzelne Zeitreihen zu Verdunstung, Schneemenge undAbfluss existieren. Fur jeden Zeitschritt liegen damit 14 - 25 Messwerte vor.Auf Grund von anderen Arbeiten ist anzunehmen, dass fur den Wert trel ≤ 4gelten wird und somit eine Eingabedimension von 100 nicht uberschrittenwird.Der erste Schritt in der Vorverarbeitung der Daten besteht darin diese mit-telwertfrei zu machen. Ein Mittelwert von null wird fur eine Folge von Datenx erreicht, indem der eigentliche Mittelwert x von jedem Datum x abgezogenwird.
x′ := x− x

2.3. AUSWAHL DER EINGABEDATEN 25
Im nachsten Schritt werden die Daten x linear skaliert, so dass alle Messwertex′ einer Zeitreihe (x1, x2, . . . , xN) in einem definierten Intervall [Lmin, Lmax]liegen. Ublich ist die Skalierung auf [−1, 1] und eine Skalierung der Art, dasssich eine Standardabweichung σx von eins ergibt (?). In der vorliegendenArbeit wird das Intervall Lmin = −1 und Lmax = +1 verwendet. Fur dieSkalierung ergibt sich folgende Formel
x′ :=(x− xmin) (Lmax − Lmin)
xmax − xmin
+ Lmin
mitxmin = min
i=1,2...,nxi
xmax = maxi=1,2...,n
xi

26 KAPITEL 2. PROBLEMSTELLUNG

Kapitel 3
Methoden
3.1 Gaußprozessregression
Im letzten Jahrzehnt ist in der Anzahl der Arbeiten auf dem Feld der”Ker-
nel Maschinen“ ein enormer Anstieg zu verzeichnen gewesen. Sehr verbreitetsind die Arbeiten zu Support Vektor Maschinen (SVM). Allerdings wurdewahrend dieser Zeit auch viel Aktivitat darauf verwendet, Gaußprozessmo-delle auf Problemstellungen aus dem Bereich des maschinellen Lernens an-zuwenden. Gaußprozesse stellen einen universellen und praktischen Ansatzzum Lernen mit
”Kernel Maschinen“ dar. Durch ein solides statistische Fun-
dament birgt das Lernen mit Gaußprozessen Vorteile bezuglich der Inter-pretierbarkeit von Modellvorhersagen und bietet ein fundiertes Frameworkfur Modellauswahl und die anschließende Modellerstellung. Theoretische undpraktische Entwicklungen haben in den letzten Jahren dazu gefuhrt, dassGaußprozesse eine ernst zu nehmende Methode im Bereich von Anwendun-gen des uberwachten Lernens geworden sind.
3.1.1 Grundlagen
Die folgenden Ausfuhrungen sind angelehnt an ?.
Definition 3.1.1 (Gaußprozess)Ein Gaußprozess GP ist eine Folge von Zufallsvariablen (Xi)
∞i=1. Dabei gilt
fur jede endliche Teilmenge dieser Folge, dass sie eine gemeinsame Normal-verteilung besitzt.
Mit dieser Bedingung ist ein Gaußprozess durch seine Erwartungswertfunk-tion m (x) und Kovarianzfunktion k (x, x′) vollstandig spezifiziert. Wobei:
27

28 KAPITEL 3. METHODEN
m (x) = E (f (x))
k (x, x′) = E [(f (x)−m (x)) (f (x′)−m (x′))] .
Der zugehorigen Prozess f (x) wird mit
f (x) ∼ GP (m (x) , k (x, x′))
bezeichnet. In diesem Kontext sollen die Zufallsvariablen Xi des Gaußprozes-ses den Funktionswerten f (x) an der Stelle x entsprechen. Insbesondere wirdfolgende Notation verwendet. Es sei D = {(xi, yi) : i = 1..N} die Menge derbeobachteten Daten, die auch als Trainingsdaten bezeichnet werden, undes bestehe zwischen xi und yi der Zusammenhang, f (xi) + ε = yi fur eineunbekannte Funktion f . Außerdem wird vorausgesetzt, dass
m (x) ≡ 0
gilt. Der Fall m 6= 0 wird spater gesondert behandelt. Diese Einschrankungist nicht zwingend erforderlich, erleichtert aber die Darstellung.Gaußprozesse besitzen nach ihrer Definition eine interessante Eigenschaft, diesehr hilfreich sein wird. Seien (y1, y2) zwei normalverteilte Zufallsvariablenmit Erwartungswert µ und Varianz Σ, also:
(y1, y2) ∼ N (µ, Σ) .
Dann muss y1 unabhanig von y2 ebenfalls normalverteilt sein und zwar mit
y1 ∼ N (µ1, Σ11)
wobei Σ11 eine Untermatrix von Σ ist. Ist die Verteilung von y1, y2 genauergegeben durch [
y1
y2
]∼ N
([µy1
µy2
],
[A CCT B
],
).
Dann kann gezeigt werden, dass die Randverteilung von y1 durch (?)
y1 ∼ N (µy1 , A)
bestimmt ist und die bedingte Verteilung von y1|y2 mit
y1|y2 ∼ N(µy1 + CB−1 (y2 − µy2) , A− CB−1CT
)(3.1)

3.1. GAUSSPROZESSREGRESSION 29
gegeben ist. Dies beschreibt einen sehr naturlichen Sachverhalt. Informellbedeutet dies, dass die Betrachtung einer großeren Menge von Zufallsvaria-blen nicht die Verteilung der Variablen einer Teilmenge verandert.Wird angenommen, dass die gesuchte Funktion f storungsfrei beobachtetwerden kann, das heißt ε ≡ 0 gilt und
X := (x1, x2, .., xn)
fi := f (xi) = yi
f = (f1, f2, ..., fn)
ist. Außerdem sei x∗ ein weiterer Punkt, sowie f∗ = f (x∗). Dann lasst sichfolgende gemeinsame Verteilung angeben:[
ff∗
]∼ N
(0,
[K (X, X) K (X, x∗)K (x∗, X) K (x∗, x∗)
]).
Dabei enthalt die Matrix K (x, x) ∈ Rn×n die Kovarianzen aller Trainings-paare, das heißt:
Ki,j (X, X) := k (xi, xj) .
Analog istK1,i (X, x∗) := k (xi, x∗) =: Ki,1 (x∗, X) .
definiert. Wird hierauf nun Formel ?? angewendet, so erhalt man die Wahr-scheinlichkeitsverteilung fur f∗ = f (x∗).
p (f∗|x∗, X, f) ∼ N(K (x∗, X) ·K−1 (X, X) f ,
K (x∗, x∗)−K (x∗, X) ·K−1 (X, X) K (X, x∗)).
(3.2)
Dieser Prozess ist so vorstellbar, dass Funktionen gemaß der a priori Vertei-lung generiert werden und nur die Teilmenge der Funktionen weiter betrach-tet wird, die mit den Trainingsdaten konsistent ist. Durch die Methodender Wahrscheinlichkeitstheorie wird dieser Schritt jedoch sehr viel effizienterdurchgefuhrt.Damit wurde nun die a posteriori Verteilung fur f∗ gefunden. Doch fur wel-chen Wert soll sich nun gemaß der Verteilung entscheiden werden? Ad hocwurde man vermutlich den Erwartungswert der Wahrscheinlichkeitsvertei-lung als Schatzwert yguess verwenden. Tatsachlich minimiert der Erwartungs-wert das erwartete Risiko, wie es bereits in Abschnitt ?? gefordert wurde.Dieses wurde unter einer Verlustfunktion L angegeben mit:
RL (yguess|x∗) =
∫L (y∗, yguess) · p (y∗|x∗, D) dy∗. (3.3)

30 KAPITEL 3. METHODEN
In den meisten Fallen wird der absolute Fehler
|yguess − y∗|
oder die quadratische Verlustfunktion
(yguess − y∗)2
als Verlustfunktionen gewahlt. Als beste Schatzung wurde diejenige verstan-den, die das erwartete Risiko in Gleichung ?? minimiert.
yoptimal|x∗ := arg minyguess
RL (yguess|x∗) (3.4)
Falls als Verlustfunktion der absolute Fehler gewahlt wird, ergibt sich fur diemeisten Verteilungen der Median der Wahrscheinlichkeitsdichte als optimalerWert yoptimal. Wird stattdessen die quadratische Verlustfunktion gewahlt, soist yoptimal gewohnlich durch den Erwartungswert der Verteilung bestimmt.Fur Normalverteilungen ist es letztendlich unerheblich, welche der beidenVerlustfunktionen verwendet wird, da in diesem Fall Median und Erwar-tungswert zusammenfallen. Der Wert fur yoptimal ist also:
yoptimal = K (x∗, X) ·K−1 (X, X) f (3.5)
Als nachstes konnen zusatzlich Storeffekte betrachtet werden. Sehr einfachist es hierfur anzunehmen, dass Storungen unabhangig und identisch normal-verteilt in den Beobachtungen auftreten. Formal heißt dies:
ε ∼ N(0, σ2
).
Damit erhalt man fur die Kovarianzen
cov (f (xp) , f (xq)) = k (xp, xq) + σ2 · δpq bzw.
cov (f) = K (X, X) + σ2I.
Die gemeinsame Verteilung hat folgende Gestalt[ff∗
]∼ N
(0,
[K (X, X) + σ2I K (X, x∗)
K (x∗, X) K (x∗, x∗)
]). (3.6)
Wird auf Ausdruck ?? die Formel ?? angewendet, so erhalt man
p (f∗|X, f, x∗) ∼ N(f∗, cov (f∗)
)mit
f∗ = E [f∗|X, f, x∗] = K (x∗, X) ·[K (X,X) + σ2I
]−1f und (3.7)
cov (f∗) = K (x∗, x∗)−K (x∗, X) ·[K (X, X) + σ2I
]−1K (X, x∗) (3.8)
Dies ist die gesuchte Wahrscheinlichkeitsverteilung fur f∗, unter Annahmevon normalverteilten Storungen in den Beobachtungen.

3.1. GAUSSPROZESSREGRESSION 31
3.1.2 Kovarianzfunktionen
In den bisherigen Betrachtungen hat die Kovarianzfunktion des Gaußprozes-ses wenig Beachtung gefunden. Es ist nun an der Zeit, dies nachzuholen, dadie Kovarianzfunktion eine entscheidende Zutat des Regressionsmodelles dar-stellt. Im Wesentlichen wird durch die Kovarianzfunktion festgelegt, wie großdie Ahnlichkeit zwischen zwei Datenpunkten x und x∗ ist. Diese Ahnlichkeitist von großer Bedeutung, da normalerweise davon ausgegangen wird, dassahnliche Eingaben auch ahnliche Ausgaben erzeugen. Das heißt unter den ge-machten Voraussetzungen, falls k (x, x∗) sehr klein ist, so gilt f (x) ≈ f (x∗).Durch die Kovarianzfunktion werden somit a priori Annahmen uber die ge-suchte Funktion getroffen. Zunachst soll erklart werden, welche Funktionenuberhaupt als Kovarianzfunktionen in Betracht kommen.
Definition 3.1.2 (Kovarianzfunktion)Die Kovarianzfunktion C (xi, xj) eines stochastischen Prozesses Z ist definiertals
C (xi, xj) := cov (Z (xi) , Z (xj)) .
Es kann gezeigt werden, dass jede positiv definite Funktion eine Kovarianz-funktion eines stochastischen Prozesses ist (?, S.16). Somit ist jede FunktionC (xi, xj), die fur alle n ∈ N, alle a ∈ Rn und alle {x1, x2, . . . , xn} die Bedin-gung
n∑i=1
n∑j=1
aiajC (xi, xj) > 0
erfullt eine Kovarianzfunktion.
Definition 3.1.3 (stationare Kovarianzfunktion)Eine Kovarianzfunktion k (x, x′) heißt stationar genau dann, wenn sie nurvon x− x′ abhangt, das heißt eine Darstellung der Form k (x− x′) besitzt.
Stationare Kovarianzfunktionen sind unter Verschiebung invariant. Das heißt,es ist prinzipiell egal, in welchem Bereich die Datenpunkte xi liegen. Wichtigist nur ihre Position relativ zu anderen Datenpunkten xj.
Definition 3.1.4 (isotropische Kovarianzfunktion)Eine Kovarianzfunktion k (x, x′) heißt isotrop genau dann, wenn sie nur von|x− x′| abhangt, das heißt eine Darstellung der Form k |x− x′| besitzt.
Isotrope Kovarianzfunktionen sind invariant unter allen langenerhaltendenBewegungen (Verschiebung, Drehung, Spiegelung).
32 KAPITEL 3. METHODEN
3.1.2.1 Quadratisch exponentielle Kovarianzfunktion (SE)
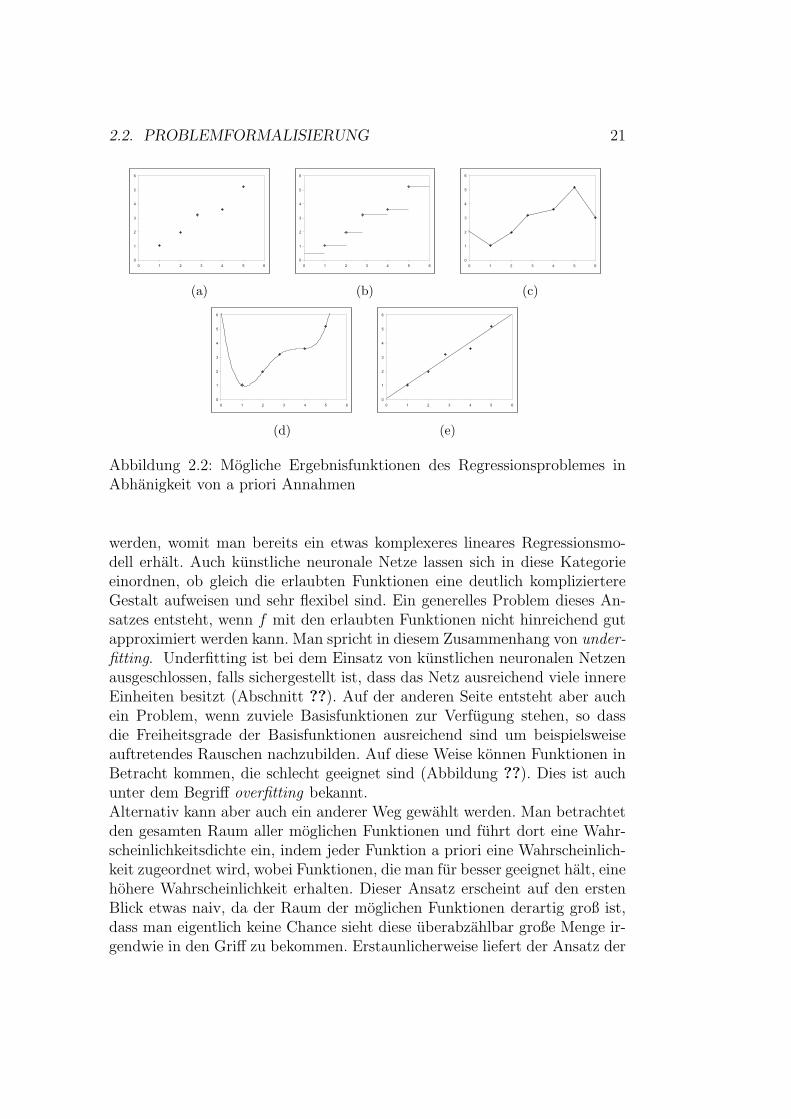
Definition 3.1.5 (quadratisch exponentielle Kovarianzfunktion)
Sei r = ‖x− x′‖2 . Die Funktion kSE (r) = exp(− r2
2l2
)heißt quadratische
exponentielle Kovarianzfunktion mit charakteristischer Langenskalierung l ∈R+.
Die quadratisch exponentielle Kovarianzfunktion ist eine der am haufigstengenutzte Kovarianzfunktionen. Sie ist isotrop und damit auch stationar. Ei-ne Eigenschaft dieser Funktion ist, dass sie beliebig oft differenzierbar ist.Daher ist der Kurvenverlauf der Funktion sehr glatt, was fur eine Reihe vonAnwendungen von Vorteil sein kann. Außerdem sind alle Ableitungen wiederKovarianzfunktionen. Der Verlauf der Funktion ist in Abbildung ??(a) furverschiedene Paramter l zu sehen. In Abbildung ??(b) sind Regressionsergeb-nisse zu sehen, die mit Hilfe von Gaußprozessen mit SE - Kovarianzfunktionentstanden sind. Die Datengrundlage bildeten 20 zufallig generierte Punkte.
0 1 2 3 40
0.2
0.4
0.6
0.8
1
Distanz r
Kov
aria
nz
l = 1l = 1/2l = 3
(a)
−6 −4 −2 0 2 4 6−2
−1.5
−1
−0.5
0
0.5
1
Eingabe x
Aus
gabe
f(x)
l = 1l = 1/2l = 3
(b)
Abbildung 3.1: Quadratisch exponentielle Kovarianzfunktion: (a) zeigt denVerlauf der Kovarianzfunktion fur verschiedene Parameter l (b) zufallig er-zeugte Funktionen aus Gaußprozessen mit SE Kovarianzfunktion und ver-schiedenen Parametern l.
3.1.2.2 Kovarianzfunktionen der Matern Klasse
Definition 3.1.6 (Kovarianzfunktionen der Matern Klasse)Sei r = ‖x− x′‖2 . Funktionen der Form
kMatern (r) =21−ν
Γ (ν)
(√2νr
l
)ν
Kν
(√2νr
l
)

3.1. GAUSSPROZESSREGRESSION 33
sind Kovarianzfunktionen der Matern Klasse. Dabei sind ν und l positveParameter und Kν eine modifizierte Besselfunktion. Γ bezeichnet die Gam-mafunktion (?).
Die Funktionen sind k mal differenzierbar genau dann, wenn k > ν gilt. Diekomplizierte Gestalt der Formel ist fur praktische Anwendungen nachteilig.Allerdings vereinfacht sich fur ν = p + 1
2, p ∈ N die Formel wesentlich. Die
interessantesten Falle ergeben sich fur ν = 32, ν = 5
2und ν = ∞, da der
Prozess fur ν = 12
sehr rauh wird und sich die Funktionen ab ν = 72
kaumnoch unterscheiden. Der Fall ν = ∞ ist interessant, weil dies genau der SEKovarianzfunktion entspricht. Die geschlossene Darstellung der Funktionenfur ν = 3
2und ν = 5
2ist gegeben durch:
kν=3/2 (r) =
(1 +
√3r
l
)exp−
√3r
l
und
kν=5/2 (r) =
(1 +
√5r
l+
5r2
3l2
)exp−
√5r
l
Die Funktionsverlaufe sind in Abbildung ?? dargestellt.
0 0.5 1 1.5 2 2.5 30
0.2
0.4
0.6
0.8
1
Distanz r
Kov
aria
nz
v = 1/2v = 3/2v = 5/2
(a)
−5 0 5−2
−1
0
1
2
3
Eingabe x
Aus
gabe
f(x)
v = 1/2v = 3/2v = 5/2
(b)
Abbildung 3.2: Matern Kovarianzfunktionen: (a) zeigt den Verlauf der Kova-rianzfunktion fur verschiedene Parameter ν, (b) zufallig erzeugte Funktionenaus Gaußprozessen mit Matern Kovarianzfunktionen und verschiedenen Pa-rametern ν. Der Parameter l wurde stets mit 1 belegt.
3.1.2.3 Rational quadratische Kovarianzfunktion (RQ)
Definition 3.1.7 (Rational quadratische Kovarianzfunktion)Die rational quadratische Kovarianzfunktion (RQ) ist gegeben durch:
kRQ (r) =
(1 +
r2
2αl2
)−α

34 KAPITEL 3. METHODEN
wobei r = ‖x− x′‖2 und α, l ∈ R+
Fur α → ∞ entsteht die SE - Kovarianzfunktion. Abbildung ?? zeigt dasVerhalten der Funktionen.
0 1 2 3 4 50
0.2
0.4
0.6
0.8
1alpha = 1alpha = 1/2alpha = 3
(a)
−5 0 5−2
−1
0
1
2
3
Eingabe x
Aus
gabe
f(x)
alpha = 1alpha = 1/2alpha = 3
(b)
Abbildung 3.3: Rational quadratische Kovarianzfunktionen: (a) zeigt denVerlauf der Kovarianzfunktion fur verschiedene Parameter α (b) zufallig er-zeugte Funktionen aus Gaußprozessen mit rational quadratischen Kovarianz-funktionen und verschiedenen Parametern α. Der Parameter l wurde stetsmir 1 belegt.
3.1.2.4 Neuronale Netzwerk Kovarianz Funktion (NN)
Definition 3.1.8 (Neuronale Netzwerk Kovarianzfunktion)Die neuronale Netzwerk Kovarianzfunktion (NN) ist definiert durch:
kNN (x, x′) =2
πsin−1
(2xT Σx′√
(1 + 2xT Σx) (1 + 2x′T Σx′)
)
wobei x aus x durch x := (1, x1, x2, . . . , xd) entsteht und Σ ∈ Rd+1×d+1 eineMatrix ist. Mit d wird die Dimension des Eingabevektors bezeichnet (Einga-bedimension). Neuronale Netzwerk Kovarianzfunktionen sind nicht stationar.Sie sind damit besser fur Extrapolationsaufgaben geeignet als stationare Ko-varianzfunktionen. Desweiteren besteht ein enger Zusammenhang der neu-ronalen Netzwerk Kovarianzfunktion zu kunstlichen neuronalen Netzen miteiner verdeckten Schicht und tanh (x) als Aktivierungsfunktion. Die Gewichtedes neuronalen Netzes sind in der Gewichtsmatrix Σ kodiert. Die zusatzlicheKomponente in x, welche auf 1 gesetzt wird, kodiert den Bias der Einheiten.? liefert eine genauere Untersuchung des Zusammenhangs zwischen Gaus-sprozessregression und neuronalen Netzen.

3.1. GAUSSPROZESSREGRESSION 35
3.1.2.5 Neue Kovarianzfunktionen generieren
Satz 3.1.1Sind k1 (x, x′) , k2 (x, x′) Kovarianzfunktionen, dann sind auch
• kA (x, x′) := k1 (x, x′) + k2 (x, x′)
• kB (x, x′) := k1 (x, x′) · k2 (x, x′)
• kC (x, x′) :=∫
h (x, z) k (z, z′) h (x′, z′) dzdz′ fur eine beliebige Kernel-funktion h (x, z)
Kovarianzfunktionen.
3.1.3 Charakteristische Langenskalierung
Eine besondere Rolle steht dem Parameter l zu. Informell ist l ein Maßdaruber, wie weit man sich im Eingaberaum x bewegen muss, damit es zu si-gnifikanten Anderungen in der Ausgabe kommen kann. Um ein Gefuhl dafurzu bekommen, welchen Einfluß der Parameter l auf die Regression hat, kannfolgendes Experiment durchgefuhrt werden. Sei eine modifizierte quadratischexponentielle Kovarianzfunktion k mit folgender Gestalt:
k (xp, xq) = σ2f exp
(− r2
2l2
)+ σ2
nδp,q
gegeben. Dabei ist σ2f ein Maß fur die Signalvariation und σ2
n ein Maß fur dasSignalrauschen. Im Prinzip wurde diese Funktion bereits fur die Modellierungmit Storeffekten in Gleichung ?? verwendet. Man kann nun zufallige Daten-punkte (xi, yi) (i = 1, . . . , n) generieren und darauf die Gaussprozessregressi-on anwenden. Dieses Experiment wird mit Parametern l1 = 0, 5, l2 = 1, 0 undl3 = 3, 0 durchgefuhrt. Die verbleibenden beiden Parameter werden moglichstoptimal gewahlt. Wie optimale Parameter gefunden werden konnen, wirdim nachsten Abschnitt erklart. Abbildung ?? zeigt die entstandenen Funk-tionen. Der grau unterlegte Bereich visualisiert die Unsicherheit, die dasModell selbst in den Vorhersagen sieht. Als Maß wurde die doppelte Va-rianz der a posteriori Wahrscheinlichkeitsverteilung verwendet. Diese kannnach Gleichung ?? bestimmt werden. In Abbildung ??(a) sind relativ schma-le graue Bereiche zu sehen. Das Modell selbst sieht die berechneten Werteals sehr sicher an. Außerdem ist zu erkennen, dass die Unsicherheit in derNahe der Datenpunkte sehr gering ist und großer wird, je weiter sich vondiesen entfernt wird. Die fur diese Funktion verwendeten Parameter sindl = 1, 0, σf = 1, 17 und σn = 0, 3. Die Werte konnen so interpretiert wer-den, dass das Modell mit dieser Langenskalierung die Daten durch relativ
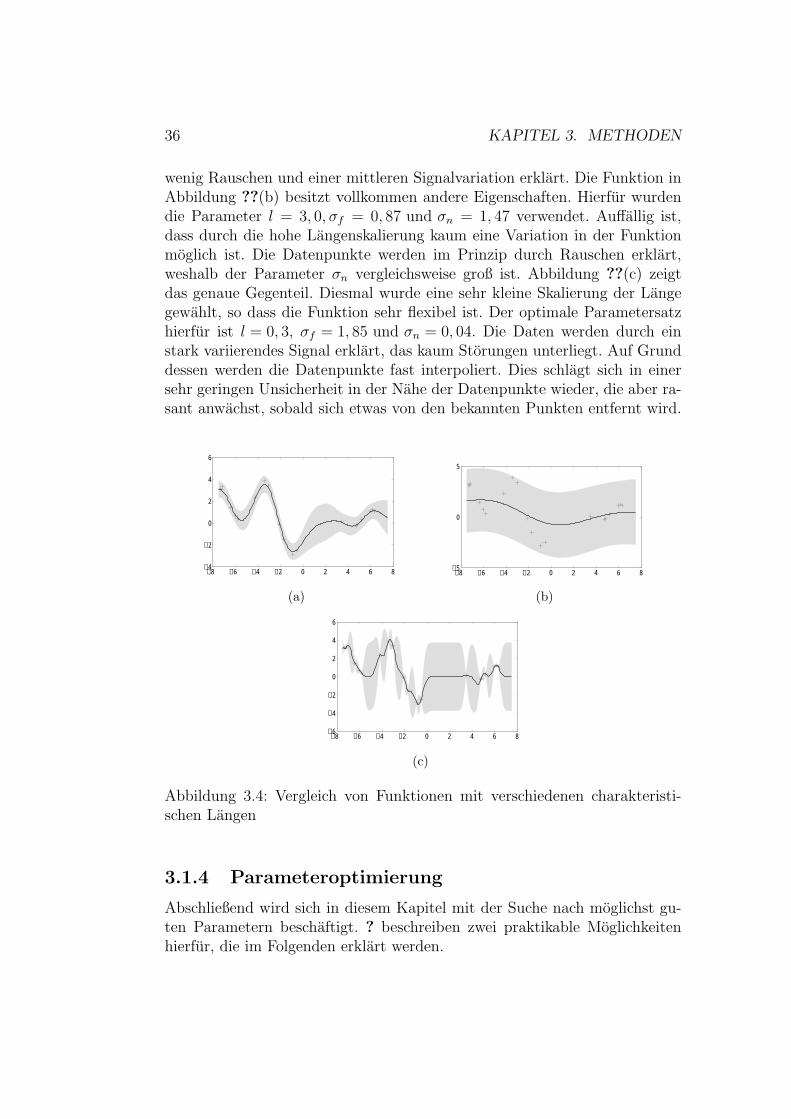
36 KAPITEL 3. METHODEN
wenig Rauschen und einer mittleren Signalvariation erklart. Die Funktion inAbbildung ??(b) besitzt vollkommen andere Eigenschaften. Hierfur wurdendie Parameter l = 3, 0, σf = 0, 87 und σn = 1, 47 verwendet. Auffallig ist,dass durch die hohe Langenskalierung kaum eine Variation in der Funktionmoglich ist. Die Datenpunkte werden im Prinzip durch Rauschen erklart,weshalb der Parameter σn vergleichsweise groß ist. Abbildung ??(c) zeigtdas genaue Gegenteil. Diesmal wurde eine sehr kleine Skalierung der Langegewahlt, so dass die Funktion sehr flexibel ist. Der optimale Parametersatzhierfur ist l = 0, 3, σf = 1, 85 und σn = 0, 04. Die Daten werden durch einstark variierendes Signal erklart, das kaum Storungen unterliegt. Auf Grunddessen werden die Datenpunkte fast interpoliert. Dies schlagt sich in einersehr geringen Unsicherheit in der Nahe der Datenpunkte wieder, die aber ra-sant anwachst, sobald sich etwas von den bekannten Punkten entfernt wird.
−8 −6 −4 −2 0 2 4 6 8−4
−2
0
2
4
6
(a)
−8 −6 −4 −2 0 2 4 6 8−5
0
5
(b)
−8 −6 −4 −2 0 2 4 6 8−6
−4
−2
0
2
4
6
(c)
Abbildung 3.4: Vergleich von Funktionen mit verschiedenen charakteristi-schen Langen
3.1.4 Parameteroptimierung
Abschließend wird sich in diesem Kapitel mit der Suche nach moglichst gu-ten Parametern beschaftigt. ? beschreiben zwei praktikable Moglichkeitenhierfur, die im Folgenden erklart werden.

3.1. GAUSSPROZESSREGRESSION 37
3.1.4.1 Marginal likelihood (ML)
Die logarithmierte marginal likelihood ist ein Maß dafur, wie wahrscheinlichdie gemachten Beobachtungen sind, wenn das durch die KovarianzmatrixKy := K (X, X) und den Parametern θ beschriebene Modell zu Grunde ge-legt wird. Dies liefert eine Information daruber, wie gut die Daten auf dasgegebene Modell passen.
Definition 3.1.9 (logarithmierte marginale likelihood)Die logarithmierte marginale Likelihood ist definiert durch:
log p (y|X, θ) = −1
2yT K−1
y y − 1
2log |Ky| −
n
2log 2π (3.9)
Dabei sind X die n Stellen, an denen die Beobachtungen y gemacht wurden,θ die Parameter, von denen die Kovarianzfunktion abhangt und Ky die Ko-varianzmatrix. Gleichung ?? ist durch Integration uber die Funktionswertevon f zu erhalten.
Ein großer Wert der marginal likelihood gibt an, dass das Modell in der La-ge ist, die Daten gut zu erklaren. Deshalb ist es sinnvoll, die Paramter θ sozu wahlen, dass die marginal likelihood maximiert wird. Hierfur ist es hilf-reich, die partiellen Ableitungen der marginal likelihood nach den einzelnenParametern zu berechnen. Diese konnen nach ? berechnet werden durch:
∂
∂θj
log p (y|X, θ) =1
2tr
((ααT −K−1
y
) ∂Ky
∂θj
)wobei α = K−1
y y (3.10)
mit (∂Ky
∂θj
)k,l
=∂ (Ky)k,l
∂θj
Der zeitliche Aufwand fur diese Berechnung ist dominiert durch die Bestim-mung der inversen Matrix K−1
y . Trotz der Moglichkeit, die inverse Matrixnicht direkt zu bestimmen, sondern entsprechende Gleichungssysteme unterZuhilfenahme einer Cholesky - Zerlegung zu losen, ist die Zeitkomplexitatder Berechung mit O (n3) gegeben. Jedoch wird die Zerlegung der MatrixKy bereits fur die Auswertung der Gleichung ?? benotigt. Ist die Zerlegungder Matrix Ky einmal bekannt, so kann Formel ?? in O (n2) Zeit pro Para-meter θj ausgewertet werden, da die Matrizenmultiplikation nicht vollstandigausgefuhrt werden muss. Es genugt die Werte der Hauptdiagonalen zu be-rechnen. Damit ist aber klar, dass der Berechnungsaufwand der partiellenAbleitungen kaum ins Gewicht fallt. Es erscheint also vorteilhaft diese zubenutzen und die Optimierung mit Hilfe eines gradientenbasierten Optimie-rungsverfahrens durchzufuhren, wie es in Abschnitt ?? beschrieben ist.

38 KAPITEL 3. METHODEN
3.1.4.2 Leave One Out - Kreuzvalidierung (LOO - CV)
In Abschnitt ?? wird die Strategie der k - faltigen Kreuzvalidierung vor-gestellt um eine Abschatzung des Generalisierungsfehlers eines Vorhersage-modells zu erhalten. Der Vorteil der Kreuzvalidierung besteht darin, dassein sehr großer Teil der Daten fur den Prozess der Modellerstellung genutztwerden kann und zusatzlich jeder Testfall in der Validierung berucksichtigtwird. Der Spezialfall der n - faltigen Kreuzvalidierung, bei dem immer ge-nau ein Datensatz ausgelassen wird, ist unter dem Namen Leave One Out- Crossvalidation (LOO - CV) bekannt. Normalerweise ist dieser Spezial-fall fur praktische Anwendungen zu aufwandig, da das Modell n mal erstelltund durchlaufen werden muss. Fur Gaußprozessregression existiert allerdingseine Moglichkeit, die die Durchfuhrung von LOO - CV praktikabel macht.Dieses Verfahren wird nun skizziert und anschließend gezeigt, wie das LOO- CV Ergebnis in den Parametern θ optimiert werden kann, um auf die-sem Wege zu einem optimalen Parametersatz zu gelangen. Der Hauptauf-wand in der Durchfuhrung der Gaußprozessregression liegt darin, die Ma-trix Ky zu invertieren. Eine schnelle LOO-CV Durchfuhrung wird durch dieSchlusselbeobachtung ermoglicht, dass bei jeder Vorhersage nach Gleichung?? und Gleichung ?? fast dieselbe Berechnung durchgefuhrt wird. In derKovarianzmatrix ist genau eine Zeile und Spalte ausgetauscht. Fur diese so-genannte Rang 1 Modifikation existieren Verfahren, die eine inkrementelleBestimmung der inversen Matrix (?) erlauben. Mit diesen ist bei Auslassenvon Trainingsfall i der Vorhersagewert gegeben durch:
µi = yi −[K−1y
]i/[K−1
]ii
und σ2i = 1/
[K−1
]ii
. (3.11)
Nachdem in O (n3) Zeit die inverse Matrix K−1y uber der gesamten Trainings-
menge berechnet wurde, bedarf es fur die Durchfuhrung der gesamten LOO -CV Prozedur nur noch O (n2) Zeit. Im Vergleich zur Invertierung der Matrixist dies vernachlassigbar wenig. Wird als Fehlermaß die erwartete logarith-mierte Wahrscheinlichkeit gewahlt
log (yi|X, y−i, θ) = −1
2log σ2
i −(yi − µi)
2
2σ2i
− 1
2log 2π, (3.12)
so ist der Gesamtfehler der LOO - CV Prozedur gegeben durch:
LLOO (X, y, θ) =n∑
i=1
log p (yi|X, y−i, θ), (3.13)

3.1. GAUSSPROZESSREGRESSION 39
wobei y−i die Menge der Beobachtungen ist, bei der die i-te Beobachtungausgelassen wurde. Mit Hilfe der partiellen Ableitungen
∂µi
∂θj
=[Zjα]i[K−1]ii
−αi [ZjK
−1]ii[K−1]2ii
(3.14)
und∂σ2
i
∂θj
=[ZjK
−1]ii[K−1]2ii
mit Zj = K−1∂K
∂θj
(3.15)
nach den Parametern θj und der Kettenregel erhalt man die partiellen Ab-leitungen
∂LLOO
∂θj
=n∑
i=1
(αi [Zjα]i −
1
2
(1 +
α2i
[K−1]ii
)[ZjK
−1]ii
)/[K−1
]ii
(3.16)
nach den Parametern θj. Dabei ist α = K−1y und Zj = K−1 ∂K∂θj
. Mit Hilfe
dieser wird der effiziente Einsatz eines gradientenbasierten Optimierungsver-fahrens ermoglicht. Hierbei ist der Aufwand allerdings etwas großer, da es un-vermeidlich ist die Multiplikation Zj = K−1 ∂K
∂θjvollstandig auszufuhren. Die
Zeitkomplexitat fur die Berechnung der partiellen Ableitungen ist beschranktdurch O (n3). Zusatzlich zur erwarteten logarithmierten Wahrscheinlichkeitwird hier noch der mittlere quadratische Fehler (MSE) als Fehlermaß be-trachtet. Dieser ist definiert als:
LMSE =1
n
n∑i=1
(yi − µi)2 . (3.17)
Die partiellen Ableitungen werden mit Hilfe von Gleichung ?? und ?? zu
∂LMSE
∂θj
=1
n
n∑i=1
2 (yi − µi)∂ (yi − µi)
∂θj
=1
n
n∑i=1
2 (yi − µi)
[αj [ZjK
−1]ii[K−1]2ii
−[Zjα]i[K−1]ii
].
berechnet. Im Gegensatz zur marginal likelihood geben die LOO - CV Er-gebnisse einen Anhaltspunkt dafur, ob die Annahmen des Modells erfulltsind. Aus diesem Grund wurde von ?, Kapitel 4.8 argumentiert, dass Kreuz-validierungstechniken robuster gegen falsch gewahlte Modelle sein sollten.Im spateren Teil der vorliegenden Arbeit werden alle drei hier behandeltenVarianten der Parameteroptimierung eingesetzt und die erzielten Resultatemiteinander vergleichen.

40 KAPITEL 3. METHODEN
3.1.4.3 Gradientenabstieg
In den letzten beiden Abschnitten wurden Maße fur die Gute eines Modellsangegeben. Es ist nun die Aufgabe, diese freien Parameter der Kovarianz-funktionen so zu wahlen, dass die Modellgute optimiert wird. Hierfur bietetsich eine breite Auswahl an Optimierungsverfahren (?). In der vorliegendenArbeit wird ein Gradientenabstiegsverfahren fur die Optimierung verwendet.Dabei wird, ausgehend von einem Anfangspunkt x0, mit Hilfe der partiel-len Ableitungen, die Richtung des steilsten Abstiegs auf einer Fehlerfunktionbestimmt. Der aktuelle Punkt wird nun in diese Richtung verschoben, sodass eine Verbesserung in der Zielfunktion zu erwarten ist. Dies wird solangewiederholt bis in den Parametern oder dem Funktionswert keine wesentlicheAnderung mehr stattfindet. Gradientenabstiegsverfahren sind lokale Opti-mierungsverfahren, das heißt das Verfahren findet im Allgemeinen lediglichein lokales Optimum. Trotzdem wird hier ein Gradientenabstiegsverfahrenverwendet, da die partiellen Ableitungen der Fehlerfunktion relativ schnellberechnet werden konnen und sich daher ein Geschwindigkeitsvorteil ge-genuber anderen Verfahren, insbesondere gegenuber globalen Optimierungs-verfahren, ergibt. ? argumentieren, dass die Fehlerflache der vorgestelltenGutemaße selten viele lokale Optima aufweist und daher Gradientenabstiegs-verfahren prinzipiell geeignet sind. Es wird empfohlen, die Optimierung mitverschiedenen Startpunkten zu beginnen, um nach Moglichkeit das globaleOptimum zu finden. Das verwendete Verfahren ist in Algorithmus ?? skiz-ziert.

3.1. GAUSSPROZESSREGRESSION 41
Algorithmus 3.1.1 : Gradientenabstiegsverfahren
Input : Kriterium f , Startschrittweite α, Startpunkt x0, Stopkriterienε1, ε2
Output : Optimum x∗, Funktionswert y∗ := f (x∗)step := α1
x∗ := x02
y∗ := f (x0)3
δ := 04
repeat5
ν := ∇f (x∗)6
step := 4 · step7
repeat8
step := step/29
x := x∗ + step · ν10
until f (x) > y∗ OR step < ε211
delta := f (x)− y∗12
x∗ := x13
y∗ := f (x∗)14
until δ < ε115
3.1.5 Modellierung der Erwartungswertfunktion
In Abschnitt ?? wurden Gausprozessmodelle unter der ublichen Vorausset-zung behandelt, dass die Erwartungswertfunktion der zugrunde liegendenProzesse gleich null ist. Es ist zu bemerken, dass dies keine drastische Ein-schrankung darstellt, da der Erwartungswert des a posteriori Prozesses nichtzwingend null ist. Es kann sinnvoll sein, diese Einschrankung aufzuheben.Angenommen ein Modell mit quadratisch exponentieller Kovarianzfunktionsei gegeben. Außerdem sei xex ein Eingabevektor, der sehr weit von allenbekannten Beobachtungen entfernt ist (zum Beispiel ein extremes Nieder-schlagsereignis). Dann ist es leicht nach zu rechnen, dass die Antwort desModells fur dieses Extrapolationsproblem nahezu null sein wird, obwohl eseinsichtig ist, dass ein starker Anstieg des Abflusses zu erwarten ist. Um dieErwartungswertfunktion zu modellieren, wird zunachst eine Klasse von Funk-tionen festlegt, die dafur in Frage kommt. Im Allgemeinen kann hierfur jedebeliebige Funktion angesetzt werden. Dann werden die Eingabedaten y derarttransformiert, dass ihre Erwartungswertfunktion wieder null ist. Im Ergeb-nis wird y durch y′ := y −m (x) ersetzt. Die eigentlichen Ergebnisse mussendann so transformiert werden, dass f ′
∗ := f∗ + m (x∗) gilt und f ′∗ die Vor-
hersage ist. Es ist normalerweise nicht einfach m (x∗) zu spezifizieren. Selbst

42 KAPITEL 3. METHODEN
nachdem eine entsprechende Funktionsklasse gewahlt ist, hangt m (x) mei-stens von Parametern θm ab, die ebenfalls bestimmt werden mussen. Es sindverschiedene Ansatze bekannt, diese Parameterbestimmung durchzufuhren(siehe dazu ?). Die in dieser Arbeit eingesetzte Methode behandelt θm so, alsob es sich um Paramter der Kovarianzfunktion handeln wurde. Somit werden,wahrend des Modellauswahlprozesses, nicht nur die Parameter der Kovari-anzfunktion bestimmt, sondern auch die der Erwartungswertfunktion. In dervorliegenden Arbeit wird sich auf polynomielle Erwartungswertfunktionenbeschrankt, also
m (x) =
p∑j1,j2,...,jm
aj1 · aj2 · . . . · ajm · xj11 xj2
2 · . . . · xjmm .
Fur diese Klasse ist ein weiteres interessantes Vorgehen praktikabel. Dabeiwerden im Vorfeld die unbekannten Parameter des Polynoms mit Hilfe ei-ner linearen Regression bestimmt. Die verbleibenden Residuen werden danndurch Gaußprozessregression modelliert (?).
3.2 Mehrschichtige Perzeptronennetze
Kunstliche neuronale Netze werden bereits seit 1943 verwendet. Erste Ar-beiten stammen von ?. Sie beschaftigten sich damals vor allem mit der Fra-ge, ob das menschliche Gehirn tatsachlich die turingberechenbaren Funktio-nen berechnen kann. Heute liegt die Starke kunstlicher neuronaler Netze inAnwendungsgebieten, in denen wenig Wissen uber das zu losende Problemvorliegt. Insbesondere trifft dies auf Probleme zu, fur die keine mathemati-sche Theorie zur Losung bekannt ist, deren Eingabedaten stark verrauschtoder unvollstandig sind, das Losungssystem besonders robust gegen Ausfallevon zentralen Komponenten sein soll oder das Losungsystem sehr stark ei-genstandig generalisieren muss. Dies betrifft vor allem Anwendungen aus denBereichen der Mustererkennung und -klassifikation, der Reglungstechnik undder kombinatorischen Optimierung. Es soll sich nun speziell mit mehrschich-tigen Perzeptronennetzen befasst werden.
3.2.1 Grundlagen
Definition 3.2.1 (statische Struktur)Ein mehrschichtiges Perzeptronennetz (MLP) ist nach ? ein 6 - Tupel (U,W,A, O, NET, ex)wobei:

3.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 43
1. U = U1 ∪ U2 ∪ ... ∪ Un eine Menge von Verarbeitungseinheiten ist mitn ≥ 3 und Ui 6= ∅ fur i ∈ {1, ..., n} und Ui ∩ Uj = ∅ fur i 6= j.U1 wird Eingabeschicht, Ui mit i ∈ {2, .., n− 1} innere Schichten undUn Ausgabeschicht genannt.
2. W : U × U → R ist eine Abbildung, durch die die Netzwerkstrukturbeschrieben wird. In diesem Modell sollen nur Verbindungen direktaufeinander folgender Schichten erlaubt sein, so dass gefordert wird:
W (u, v) 6= 0 ⇒ u ∈ Ui, v ∈ Ui+1 mit i ∈ {1, ..., n− 1}
3. Durch die Funktion A : U → RR wird jeder Einheit u ∈ U eine Aktivie-rungsfunktion Au : R → R zugeordnet. Mit dieser wird die Aktivierungau wie folgt berechnet:
au :=
{Au (ex (u)) = ex (u) fur alle u ∈ U1
Au (netu (u)) fur alle u ∈ Ui mit i ∈ {2, ..., n}
Haufig wird Au : R → [0, 1] gewahlt. Außerdem sollten diese Funk-tionen nichtlinear sein. Anderenfalls erhalt man prinzipiell ein linearesneuronales Netz. Von diesem kann gezeigt werden, dass es nur linearseperable Lernaufgaben bewaltigen kann und außerdem, dass mehrereinnere Schichten keine qualitative Verbesserung des Netzes bewirken.
4. O ordnet jeder Einheit u ∈ U die Identitat als Ausgabefunktion zu.Somit ist die Aktivierung der Einheiten zugleich ihre Ausgabe ou.
ou := Ou (au) = au
5. NET ordnet jeder Einheit v ∈ Ui mit 2 ≤ i ≤ n eine Netzeingabefunkti-on (Propagierungsfunktion) NETv : (R× R)|Ui−1| → R zur Berechnungder Netzeingabe netv zu, mit
netv =∑
u∈Ui−1
W (u, v) ou + θv
Dabei ist θv ∈ R der Bias der Einheit v. Der Bias kann als zusatzlicheVerbindung (mit Gewicht θv) zu einer Einheit aufgefasst werden, wel-che konstant 1 liefert. Zur Vereinfachung der Notation wird dies imFolgenden stets verwendet, so dass ohne Beschrankung der Allgemein-heit stets θv = 0 gilt.

44 KAPITEL 3. METHODEN
6. ex : U1 → R ist eine Abbildung die jeder Eingabeeinheit der Eingabe-schicht ihre externe Eingabe
exu = ex (u)
zuordnet.
Definition 3.2.2 (Verhalten von mehrschichtigen Perzeptronennetzen)Ausgehend von einer externen Eingabe ex berechnet das mehrschichtige Per-zeptronennetz an der Ausgabeschicht einen Ergebnisvektor out. Die Ausgabeder Einheiten u ∈ Ui wird wie folgt berechnet:
ou :=
{Au (ex (u)) fur i = 1Au (net (u)) fur i > 1
Die Reihenfolge der Neuberechnung erfolgt schichtenweise. In jedem Zykluswird zunachst die Aktivierung der Einheiten in U1 berechnet, dann diejenigenin U2 bis hin zu den Einheiten in Un. Es lasst sich zeigen, dass es fur dieAusgabe irrelevant ist, in welcher Reihenfolge die Neuberechnung innerhalbder Schichten erfolgt. Die Ausgabe des Netzes ist gleich der Aktivierung derEinheiten in der Ausgabeschicht.
out := (u1, u2, ..., ur) mit ui ∈ Un
Damit ist das Verhalten des mehrschichtigen Perzeptronennetzes beschrie-ben. Es stellt sich aber die Frage wie die Aktivierungsfunktion zu wahlen ist.Haufig werden die in Abbildungen ?? - ?? dargestellten Aktivierungsfunk-tionen benutzt.
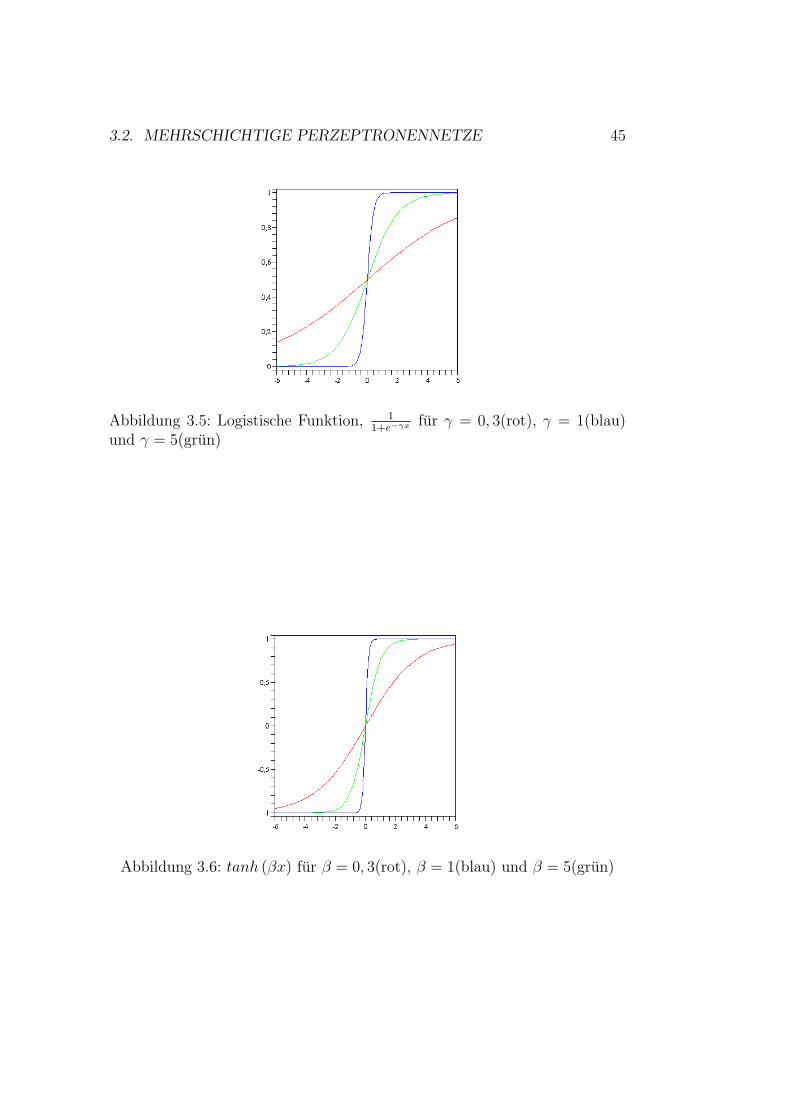
3.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 45
Abbildung 3.5: Logistische Funktion, 11+e−γx fur γ = 0, 3(rot), γ = 1(blau)
und γ = 5(grun)
Abbildung 3.6: tanh (βx) fur β = 0, 3(rot), β = 1(blau) und β = 5(grun)
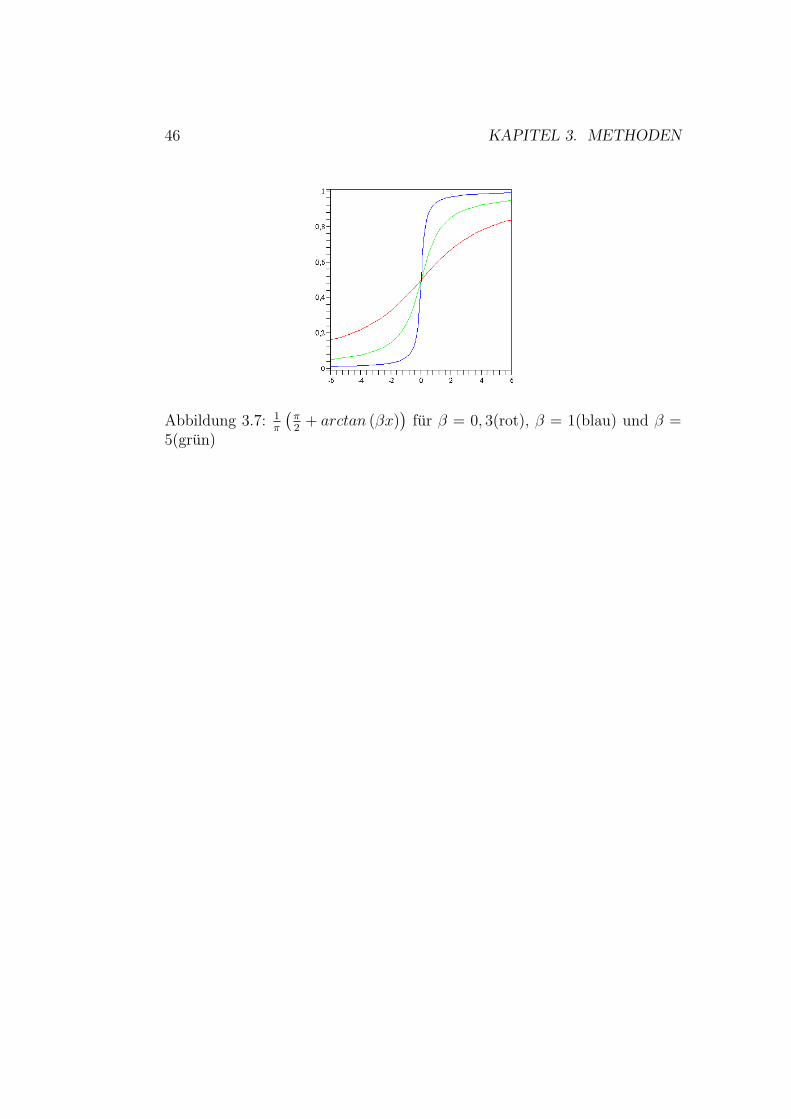
46 KAPITEL 3. METHODEN
Abbildung 3.7: 1π
(π2
+ arctan (βx))
fur β = 0, 3(rot), β = 1(blau) und β =5(grun)

3.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 47
Diese stellen Approximationen von linearen Schwellenwertfunktionen dar, diesich gut zur Modellierung von vielen Problemen eignen. Allerdings ist fur dasLernverfahren zumindest sicherzustellen, dass die verwendeten Aktivierungs-funktionen differenzierbar sind.
3.2.2 Backpropagation Lernverfahren
Fur viele Typen von neuronalen Netzen existieren Lernverfahren, mit derenHilfe die Gewichte im Netz gezielt angepasst werden konnen. Ziel der Ge-wichtsanpassung ist es, das Netz so zu trainieren, dass es Trainingsmustererlernt, das heißt auf Trainingseingabe die korrekten Ausgaben liefert. Mitder Hoffnung, dass sich das Netz auch bei Eingabe von unbekannten Da-ten angemessen verhalt. Das mehrschichtige Perzeptronennetz ist eines derbeliebtesten Netzwerkmodelle. Ein wesentlicher Grund besteht darin, dassfur dieses Modell ein einfaches und effizientes Lernverfahren existiert - dasBackpropagation Verfahren. Ein Einsatzgebiet dieses Verfahrens ist die Funk-tionsregression mit Hilfe mehrschichtiger Perzeptronennetze. Dazu werdendem Verfahren in der Eingabe Trainingsmuster bereitgestellt. Ein Trainings-muster ist ein Paar aus einem Eingabevektor xi ∈ Rd und der dazu gehorigenBeobachtung yi = f (xi) + ε. Das Ergebnis ist im Idealfall ein Netz, dessenGewichte so angepasst sind, dass es nicht nur auf die Trainingsbeispiele rich-tige Ausgaben liefert, sondern auch fur unbekannte Eingaben moglichst guteAusgaben produziert.Ansatz des Verfahrens ist es, jede Trainingseingabe durch das Netz zu pro-pagieren und anschließend den Fehler δ zwischen gewunschter und erhaltenerAusgabe zu berechnen. Dieser Fehler wird anschließend ruckwarts durch dasNetz propagiert. Jede Einheit kann an Hand des erhaltenen Fehlersignalesfeststellen, welchen eigenen Beitrag sie am Gesamtfehler leistet und diesendurch Gewichtsanpassung entsprechend kompensieren. Fur die formale Be-schreibung wird die Menge der Trainingsbeispiele wie gewohnt mit
D = {(xi, yi) : i = 1, 2, . . . , n}
bezeichnet. Jedes Trainingsbeispiel p ∈ D ist ein Paar der Form(x(p), y(p)
),
wobei x(p) als Eingabe des Perzeptronennetzes dient und y(p) die gewunschteAusgabe beschreibt. Der Backpropagation - Algorithmus lasst sich somit wiefolgt formulieren:

48 KAPITEL 3. METHODEN
Algorithmus 3.2.1 : Backpropagation Lernverfahren
Input : Trainingsmenge D, Schrittweite αt := 01
repeat2
forall p =(x(p), y(p)
)∈ D do3
Propagiere x(p) durch das Netz und berechne dabei fur alle4
v ∈ U : A′u (netv) und av
δ(p)v := A′
v
(net
(p)v
)·(y
(p)v − a
(p)v
)fur v ∈ Un5
for i = n− 1 to 1 do6
δ(p)v := A′
v
(net
(p)v
)·∑
w∈Ui+1
δ(p)w · w(t) (v, w)
7
end8
Passe die Gewichte nach der Vorschrift:9
w(t+1) (u, v) := w(t)(u, v) + αδ(p)v a
(p)u an
end10
t := t + 111
until Abbruchbedingung erfullt12
Es lasst sich zeigen, dass der hier formulierte Algorithmus das Fehlermaß
E (D) :=∑p∈D
∑v∈Un
(y(p)
v − a(p)v
)2minimiert. Das Backpropagation Verfahren passt die Gewichte des Perzeptro-nennetzes mit Hilfe eines approximierten Gradientenabstieges und der Lern-rate α an. Ein formaler Beweis dieser Aussage wird von ? gegeben.
3.2.3 Mehrschichtige Perzeptronennetze als universel-le Approximatoren
Der folgende Satz besagt, dass mit Hilfe mehrschichtiger Perzeptronennetzeim Prinzip jede beliebige stetige Funktion approximiert werden kann!
Satz 3.2.1 (Approximationstheorem)Es sei f : [0, 1]d → [0, 1] eine stetige Funktion. Dann existiert ein mehrschich-tiges Perzeptronennetz mit d Eingabeeinheiten und einem Ausgabeneuron,das f beliebig gut approximiert. Das heißt, fur alle ε > 0 existiert ein mehr-schichtiges Perzeptronennetz, welches die Funktion fε realisiert, wobei∫
[0,1]d
|f (x)− fε (x)| dx < ε
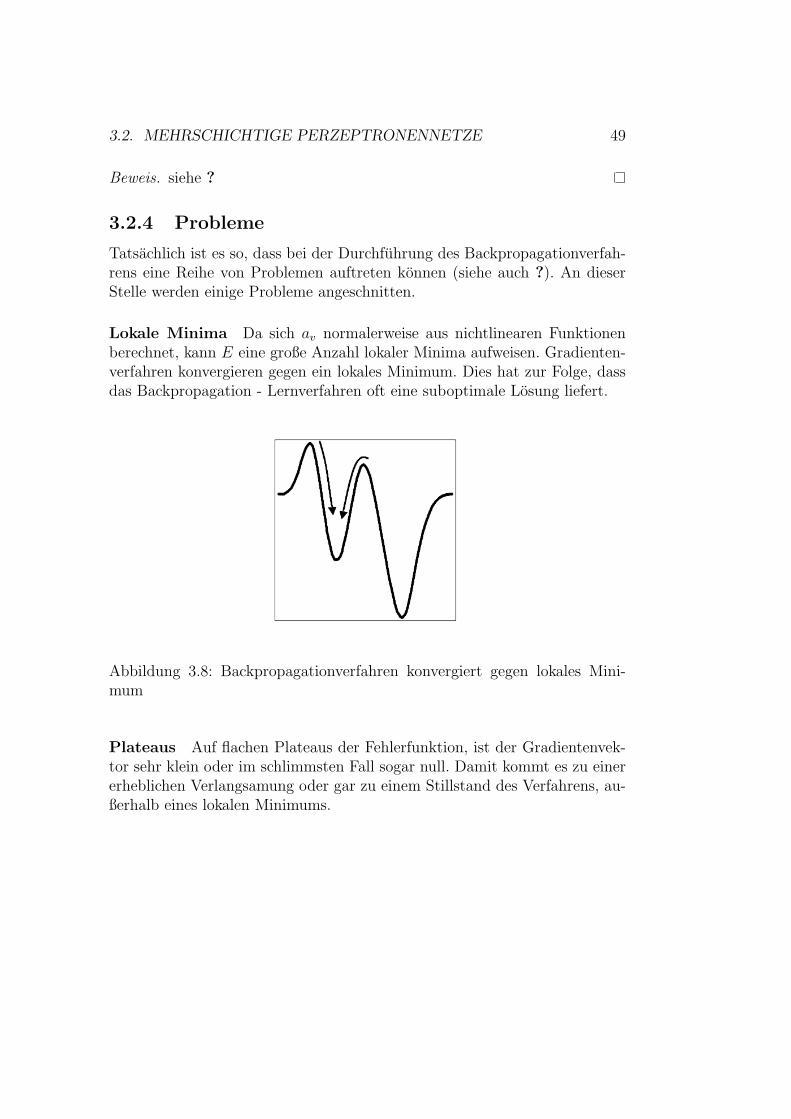
3.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 49
Beweis. siehe ?
3.2.4 Probleme
Tatsachlich ist es so, dass bei der Durchfuhrung des Backpropagationverfah-rens eine Reihe von Problemen auftreten konnen (siehe auch ?). An dieserStelle werden einige Probleme angeschnitten.
Lokale Minima Da sich av normalerweise aus nichtlinearen Funktionenberechnet, kann E eine große Anzahl lokaler Minima aufweisen. Gradienten-verfahren konvergieren gegen ein lokales Minimum. Dies hat zur Folge, dassdas Backpropagation - Lernverfahren oft eine suboptimale Losung liefert.
Abbildung 3.8: Backpropagationverfahren konvergiert gegen lokales Mini-mum
Plateaus Auf flachen Plateaus der Fehlerfunktion, ist der Gradientenvek-tor sehr klein oder im schlimmsten Fall sogar null. Damit kommt es zu einererheblichen Verlangsamung oder gar zu einem Stillstand des Verfahrens, au-ßerhalb eines lokalen Minimums.
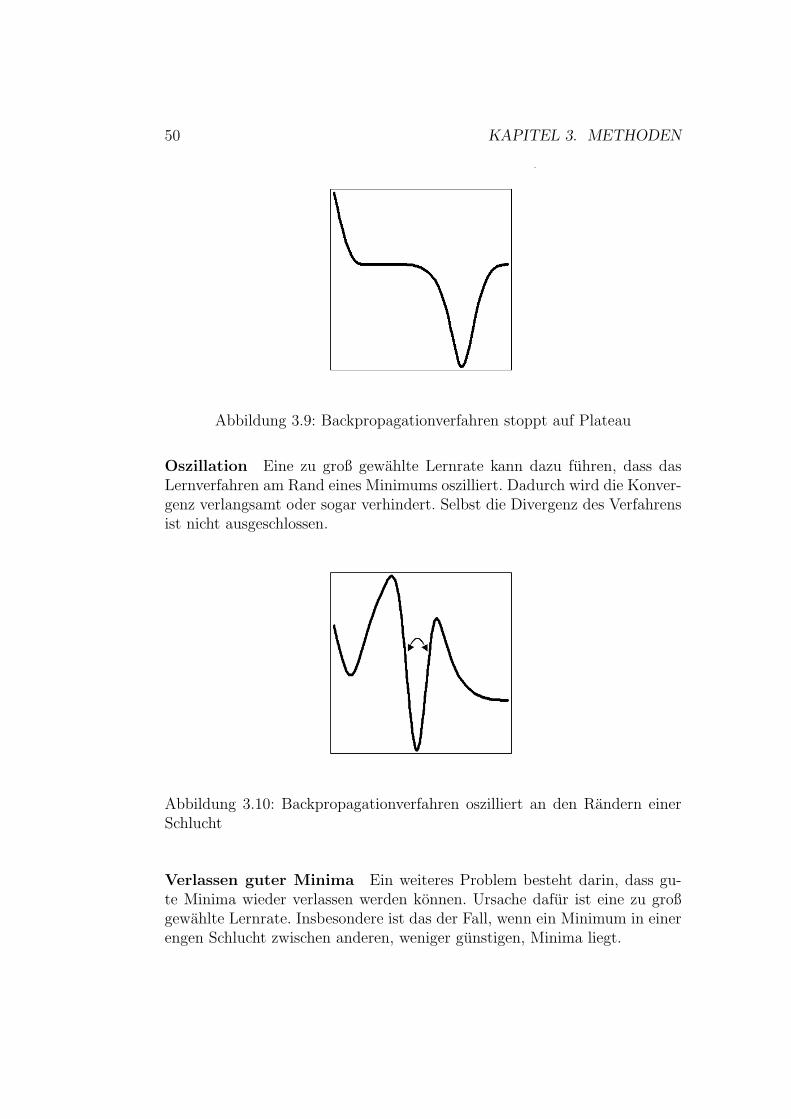
50 KAPITEL 3. METHODEN
Abbildung 3.9: Backpropagationverfahren stoppt auf Plateau
Oszillation Eine zu groß gewahlte Lernrate kann dazu fuhren, dass dasLernverfahren am Rand eines Minimums oszilliert. Dadurch wird die Konver-genz verlangsamt oder sogar verhindert. Selbst die Divergenz des Verfahrensist nicht ausgeschlossen.
Abbildung 3.10: Backpropagationverfahren oszilliert an den Randern einerSchlucht
Verlassen guter Minima Ein weiteres Problem besteht darin, dass gu-te Minima wieder verlassen werden konnen. Ursache dafur ist eine zu großgewahlte Lernrate. Insbesondere ist das der Fall, wenn ein Minimum in einerengen Schlucht zwischen anderen, weniger gunstigen, Minima liegt.
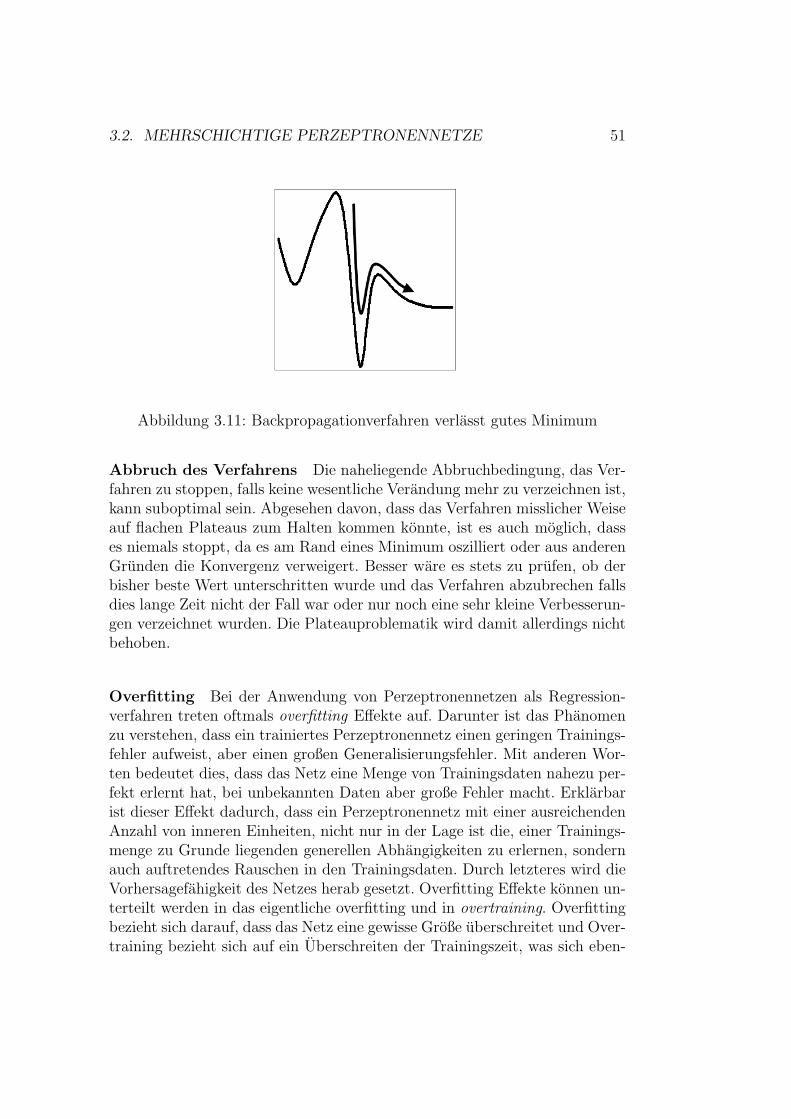
3.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 51
Abbildung 3.11: Backpropagationverfahren verlasst gutes Minimum
Abbruch des Verfahrens Die naheliegende Abbruchbedingung, das Ver-fahren zu stoppen, falls keine wesentliche Verandung mehr zu verzeichnen ist,kann suboptimal sein. Abgesehen davon, dass das Verfahren misslicher Weiseauf flachen Plateaus zum Halten kommen konnte, ist es auch moglich, dasses niemals stoppt, da es am Rand eines Minimum oszilliert oder aus anderenGrunden die Konvergenz verweigert. Besser ware es stets zu prufen, ob derbisher beste Wert unterschritten wurde und das Verfahren abzubrechen fallsdies lange Zeit nicht der Fall war oder nur noch eine sehr kleine Verbesserun-gen verzeichnet wurden. Die Plateauproblematik wird damit allerdings nichtbehoben.
Overfitting Bei der Anwendung von Perzeptronennetzen als Regression-verfahren treten oftmals overfitting Effekte auf. Darunter ist das Phanomenzu verstehen, dass ein trainiertes Perzeptronennetz einen geringen Trainings-fehler aufweist, aber einen großen Generalisierungsfehler. Mit anderen Wor-ten bedeutet dies, dass das Netz eine Menge von Trainingsdaten nahezu per-fekt erlernt hat, bei unbekannten Daten aber große Fehler macht. Erklarbarist dieser Effekt dadurch, dass ein Perzeptronennetz mit einer ausreichendenAnzahl von inneren Einheiten, nicht nur in der Lage ist die, einer Trainings-menge zu Grunde liegenden generellen Abhangigkeiten zu erlernen, sondernauch auftretendes Rauschen in den Trainingsdaten. Durch letzteres wird dieVorhersagefahigkeit des Netzes herab gesetzt. Overfitting Effekte konnen un-terteilt werden in das eigentliche overfitting und in overtraining. Overfittingbezieht sich darauf, dass das Netz eine gewisse Große uberschreitet und Over-training bezieht sich auf ein Uberschreiten der Trainingszeit, was sich eben-

52 KAPITEL 3. METHODEN
falls in schlechten Vorhersagen niederschlagt (?). ? gibt an, dass sich overfit-ting durch eine ausreichende Anzahl von Trainingsdaten vermeiden lasst. AlsWert hierfur wird A2n angegeben, wobei A die Maximalgroße der Gewichteist und n die Anzahl der Schichten im Netz bezeichnet. Der als Overtrainingbekannte Effekt ist in Abbilding ?? dargestellt. Wird wahrend der Lernphasedes Netzes nicht nur der Trainingsfehler betrachtet, sondern auch der Genera-lisierungsfehler, also den Fehler, den das Netz bei unbekannten Daten macht,so ist festzustellen, dass der Generalisierungsfehler ab einem gewissen Punktim Trainingsverlauf nicht weiter vermindert wird. Demgegenuber sinkt derTrainingsfehler noch weiter ab.
Anzahl der
Trainingsepochen
Fehler
Trainingsfehler
Generalisierungsfehler
Abbildung 3.12: Trainingsfehler und Generalsierungsfehler im Vergleich
3.2.5 Losungsmoglichkeiten
Wahl der Schrittweite Wie festgestellt wurde, ist die Wahl der Schritt-weite ein wesentlicher Faktor fur den Erfolg des Verfahrens. Wird sie zu kleingewahlt, fuhrt dies zu einer unnotigen Verlangsamung des Verfahrens, bei ei-ner zu großen Wahl, oszilliert das Verfahren oder verlasst bereits gefundeneMinima wieder. Eine mogliche Strategie besteht darin mit einer großerenSchrittweite zu starten und diese dann langsam zu vermindern (?).In der vorliegenden Arbeit wird in jeder Anwendung von kunstlichen neuro-nalen Netzen eine moglichst optimale Schrittweite α durch ein gradientenba-siertes Optimierungsverfahren ermittelt. Die dadurch erhaltenen Schrittwei-ten bewegen sich im Bereich von 0,05 bis 0,1.
Trage Backpropagation Um starkes Oszillieren oder Stagnation auf fla-chen Plateaus zu vermeiden, gibt es eine einfache und haufig benutzte Metho-de, die auf einer tragen Gewichtsanderung beruht. Dazu wird in die Berech-nung der Gewichtsanderung einen zusatzlichen Term eingefuhrt, durch den

3.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 53
die letzte Gewichtsanpassung, gewichtet mit einem Faktor β, berucksichtigtwird.
w(t+1) := w(t) + αδ(p,t)v a(p,t)
u + βαδ(p,t−1)v a(p,t−1)
u
Wird uber mehrere Schritte die Richtung der Gewichtsanderung beibehalten,so fuhrt dies zu einer Beschleunigung ansonsten zu einem Abbremsen derGewichtsanderung. Ergebnis dieser Modifikation ist zum einen, dass sich dieGeschwindigkeit auf Plateaus erhoht und selbst vollkommen flache Gebieteuberwunden werden konnen und zum anderen, dass ein Oszillieren an engenSchluchten auf Grund der haufigen Richtungsanderung unterdruckt wird.Leider erhoht dies auch die Gefahr, dass Minima ubersehen werden, weil derBremsweg praktisch zu lang ist. Da die Vorteile aber uberwiegen, wird dieseModifikation des Backpropagation Verfahrens genutzt. Der Tragheitsfaktorβ wird analog zur Schrittweite α durch eine lokale Optimierung bestimmt.Die erhaltenen Momente liegen im Bereich von 0,0 bis 0,2.
Fruhes Stoppen Um Overtraining zu vermeiden, kann die Methode desfruhen Stoppens angewendet werden. Dazu wird nach jeder k-ten (k ∈ N+)Epoche des Trainingsprozess eine Validierungsphase durchgefuhrt und gete-stet, wie groß der Fehler ist, den das Netz auf einer Menge von unbekanntenDaten macht. Ist zu beobachten, dass der so approximierte Generalisierungs-fehler anwachst, so wird das Training gestoppt. Praktisch lasst sich dieseMethode gut mit dem Kreuzvalidierungsverfahren kombinieren. Algorithmus?? fasst das Vorgehen zusammen.
Algorithmus 3.2.2 : Fruhes Stoppen
Input : Trainingsmenge Dtrain,Valdierungsmenge Dval
εnew = ∞1
εold = ∞2
repeat3
εold := εnew4
TrainkEpochs (Dtrain)5
εnew := V alidate (Dval)6
until εold − εnew < 07
3.2.6 Beispiel
Zum Abschluß des Kapitels wird eine einfache kunstliche eindimensionale Re-gressionsaufgabe betrachtet. Auf dem Intervall [0, 1] seien elf Funktionswerte
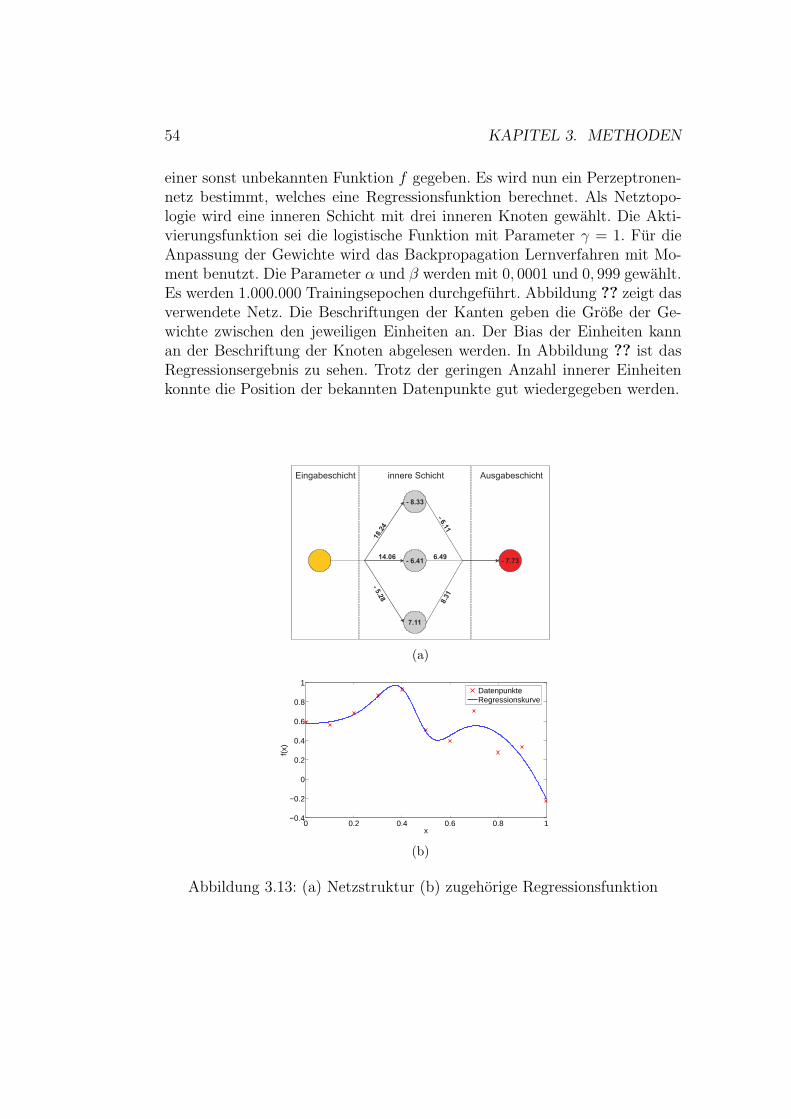
54 KAPITEL 3. METHODEN
einer sonst unbekannten Funktion f gegeben. Es wird nun ein Perzeptronen-netz bestimmt, welches eine Regressionsfunktion berechnet. Als Netztopo-logie wird eine inneren Schicht mit drei inneren Knoten gewahlt. Die Akti-vierungsfunktion sei die logistische Funktion mit Parameter γ = 1. Fur dieAnpassung der Gewichte wird das Backpropagation Lernverfahren mit Mo-ment benutzt. Die Parameter α und β werden mit 0, 0001 und 0, 999 gewahlt.Es werden 1.000.000 Trainingsepochen durchgefuhrt. Abbildung ?? zeigt dasverwendete Netz. Die Beschriftungen der Kanten geben die Große der Ge-wichte zwischen den jeweiligen Einheiten an. Der Bias der Einheiten kannan der Beschriftung der Knoten abgelesen werden. In Abbildung ?? ist dasRegressionsergebnis zu sehen. Trotz der geringen Anzahl innerer Einheitenkonnte die Position der bekannten Datenpunkte gut wiedergegeben werden.
- 8.33
- 6.41
7.11
- 7.73
Eingabeschicht innere Schicht Ausgabeschicht
-6.1
1
6.49
8.3
1
18.2
4
14.06
-5.2
8
(a)
0 0.2 0.4 0.6 0.8 1−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
f(x)
DatenpunkteRegressionskurve
(b)
Abbildung 3.13: (a) Netzstruktur (b) zugehorige Regressionsfunktion

3.3. VALIDIERUNGSVERFAHREN 55
3.3 Validierungsverfahren
3.3.1 Kreuzvalidierung
Es wurden zwei Vorhersageverfahren vorgestellt, deren Leistungsfahigkeitempirisch an einigen Testeinzugsgebieten ermittelt werden soll. Es wird da-her ein Verfahren zur Abschatzung des Generalisierungsfehlers statistischerModelle benotigt. Eine haufig benutzte Methode ist die Kreuzvalidierungnach ?. Die Grundidee der Kreuzvalidierung ist es, die verfugbare Datenmen-ge in zwei disjunkte Mengen aufzuteilen. Eine der beiden Mengen wird alsTrainingsmenge benutzt. Der verbleibende Teil, genannt Validierungsmenge,wird zum Testen des Verfahrens eingesetzt. Die Leistung, die das Verfah-ren uber dieser Menge erzielt, kann als Annahrung an den Fehler aufgefasstwerden, den das Verfahren bei unbekannten Daten macht. Diese Grundideekann verfeinert werden, indem die Trainingsmenge in k gleich große Mengenaufgeteilt wird. Die Validierung erfolgt auf genau einer der k Teilmengen.Fur das Training konnen die restlichen k− 1 Teilmengen verwendet werden.Diese Prozedur wird k mal wiederholt, so dass jede der k Teilmenge ein-mal Validierungsmenge ist. Man spricht von k - faltiger Kreuzvalidierung.Der Vorteil der Kreuzvalidierung besteht darin, dass ein sehr großer Teil derTrainingsdaten fur den Lernprozess benutzt werden kann und zusatzlich jederTestfall in der Validierung berucksichtigt wird. Nachteilig an dieser Strategieist der hohe Rechenaufwand, der mit ihr verbunden ist. Fur die kompletteDurchfuhrung der k - faltigen Kreuzvalidierung mussen genau k Lernphasenausgefuhrt werden. Fur große k ist diese Vorgehensweise damit meist nichtpraktikabel.
3.3.2 Fehlermaße
Um zu bestimmen, wie gut oder schlecht sich ein Vorhersagemodell verhalt,wird ein Maß fur die Modellgute benotigt. In diesem Abschnitt werden vierverschiedene Maße angeben und Vor- und Nachteile angerissen. Eine Unter-suchung dieser Problematik wird von ? gegeben. Seien yi Schatzungen fur
yi (i = 1, 2, . . . , n) mit Mittelwert Y := 1n
n∑i=1
yi. Dann lassen sich folgende
Fehlermaße definieren:
Definition 3.3.1 (Mittlerer quadratischer Fehler (MSE))Der mittlere quadratische Fehler (MSE) der Schatzungen ist definiert durch
MSE =1
n
n∑i=1
(yi − yi)2

56 KAPITEL 3. METHODEN
Er ist wohl eines der am haufigsten verwendeten Fehlermaße. Dabei wird ein-fach der Mittelwert der quadrierten Differenzen bestimmt. Die Quadratur derFehler ist nachteilig, da große Werte in der Zeitreihe, die zwangslaufig auchzu großeren Fehlern fuhren, dadurch stark uberbewertet werden, wahrend eszu einer Vernachlassigung der kleinen Werte kommt. Durch die fehlende Nor-malisierung konnen außerdem mittlere quadratische Fehler fur verschiedeneAnwendungen nicht verglichen werden.
Definition 3.3.2 (Relativer quadratischer Fehler (RSE))Der relative quadratische Fehler (RSE) der Schatzungen ist definiert durch
RSE =n∑
i=1
(yi − yi)2
(yi − Y )2
Dies stellt eine einfache Modifikation des mittleren quadratischen Fehlers dar,die der Normierung und somit auch der Vergleichbarkeit des Maßes dient.
Definition 3.3.3 (Nash-Sutcliffe Effizienz (E2))Die Nash-Sutcliffe Effizienz E2 ist definiert als
1−RSE.
Sie wurde 1970 von Nash und Sutcliffe vorgeschlagen. Der Wertebereich vonE2 liegt im Intervall [−∞, 1]. Ein Wert von eins heißt, dass die Schatzungenperfekt mit den Beobachtungen ubereinstimmen. Eine Effizienz von wenigerals null weißt darauf hin, dass der Erwartungswert der Zeitreihe ein bessererSchatzer gewesen ware. Im Gegensatz zum MSE liefert E2 vergleichbare Wer-te. Die Uberbewertung von großen Werten (zum Beispiel Hochwasserspitzen)bleibt aber bestehen.
Definition 3.3.4 (Modifizierte Nash-Sutcliffe Effizienz (E1))Die modifizierte Nash-Sutcliffe Effizienz E1 ist definiert als
E1 = 1−n∑
i=1
|yi − yi||yi − Y |
Durch die Modifikation wird die Uberbewertung großer Werte deutlich redu-ziert. Desweiteren gilt immer E1 < E2 (?).
Definition 3.3.5 (empirischer Korrelationskoeffizient r2)Der empirische Korrelationskoeffizient r2 zwischen zwei Zeitreihen ist defi-niert als:
r2 =
1n
n∑i=1
(xi − x) (yi − y)√1n
n∑i=1
(xi − x)2
√1n
n∑i=1
(yi − y)2

3.3. VALIDIERUNGSVERFAHREN 57
Der Korrelationskoeffizient ist ein Maß fur den Grad des linearen Zusammen-hangs zwischen zwei Zeitreihen. Er kann Werte zwischen -1 und 1 annehmen.Ein Wert von +1 (bzw. -1) gibt an, dass ein linearer Zusammenhang zwi-schen den betrachteten Zeitreihen besteht. Wenn der Korrelationskoeffizientden Wert 0 aufweist, hangen die beiden Zeitreihen uberhaupt nicht linearvoneinander ab. Allerdings konnen diese ungeachtet dessen in nicht-linearerWeise voneinander abhangen.
In der vorliegenden Arbeit wird selten direkt der Fehler zwischen gemesse-nen Abfluß Qi+1 und berechneten Abfluß fi+1 bestimmt. Stattdessen wirdzunachst der aktuelle Abfluss subtrahiert und dann der Fehler zwischenQi+1−Qi und fi+1−Qi bestimmt. Auf absolute Fehlermaße, wie den mittle-ren quadratischen Fehler, hat dies keine Auswirkung. Fur relative Fehlermaßeist die Modifikation wichtig um die tatsachliche Gute des statistischen Vor-hersagemodells zu bestimmen, wie folgende Uberlegung zeigt: Angenommendas Vorhersageverfahren gibt als zukunftigen Abflusswert einfach den aktu-ellen Abfluss an, das heißt fi+1 := Qi. Diese simple Vorgehensweise fuhrtbereits zu E2 Modellguten von 0,6 - 0,8 und verschleiert somit, dass es sicheigentlich nur um das Mittelwertmodell handelt. Wird aber erst der aktuelleAbfluss subtrahiert und dann die Gute bestimmt, erhalt der Mittelwert alsVorhersagemodell tatsachlich nur einen E2 Wert von etwa null. Abbildung?? verdeutlicht diese Problematik.
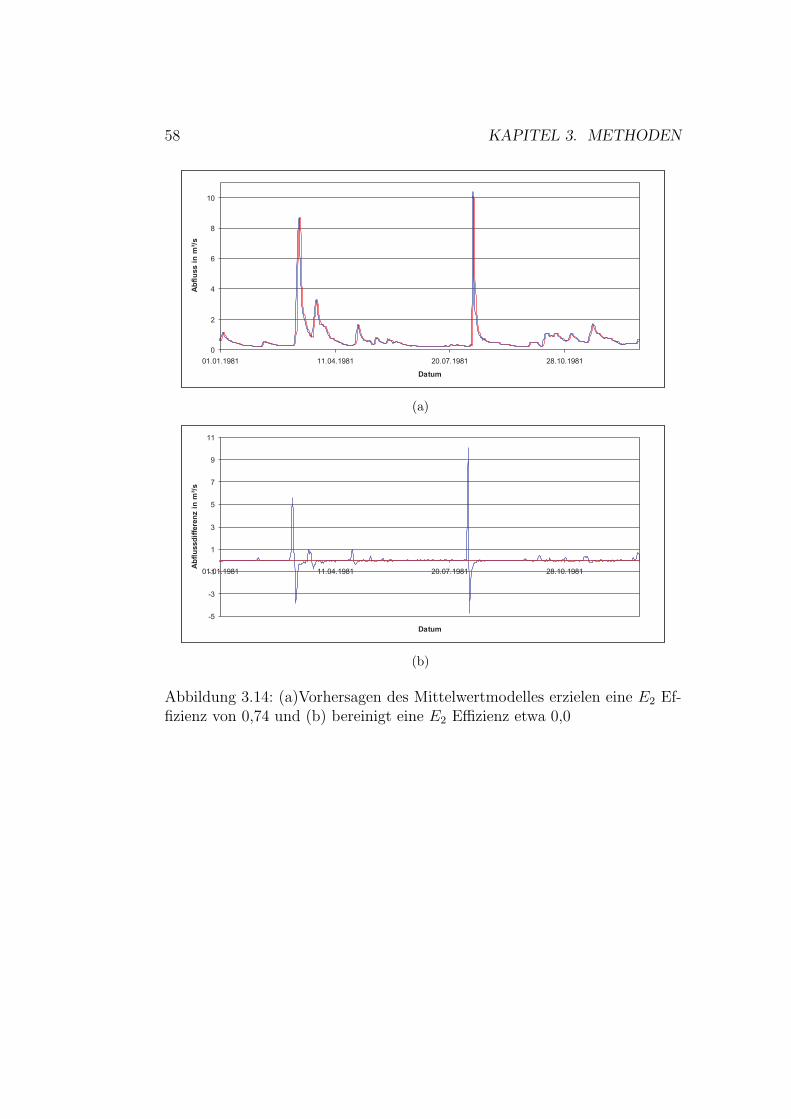
58 KAPITEL 3. METHODEN
0
2
4
6
8
10
01.01.1981 11.04.1981 20.07.1981 28.10.1981
Datum
Ab
flu
ss
inm
³/s
(a)
-5
-3
-1
1
3
5
7
9
11
01.01.1981 11.04.1981 20.07.1981 28.10.1981
Datum
Ab
flu
ssd
iffe
ren
zin
m³/
s
(b)
Abbildung 3.14: (a)Vorhersagen des Mittelwertmodelles erzielen eine E2 Ef-fizienz von 0,74 und (b) bereinigt eine E2 Effizienz etwa 0,0

Kapitel 4
Vorstellung derUntersuchungsgebiete
In diesem Kapitel wird ein kurzer Uberblick uber die vier Einzugsgebietegegeben, an denen die vorgestellten Methoden untersucht werden.
4.1 Wilde Gera
Das erste gewahlte Einzugsgebiet ist das der Wilden Gera. Dieses befindetsich am Nordrand des Thuringer Waldes in einem typischen Mittelgebirgs-becken. Die Große des Gebietes betragt etwa 13 km2. Die Wilde Gera stellt einTeileinzugsgebiet der Gera dar, welche nach Durchquerung der thuringischenLandeshauptstadt Erfurt nordlich von Gebesee in die Unstrut mundet. Trotzder geringen Große des Einzugsgebietes tritt eine Hohendifferenz von ca.420m auf. Der hochste Punkt liegt am Großen Beerberg mit 980m NN undder tiefste auf einer Hohe von 560m NN am Einzugsgebietsauslass mit demBezugspegel Gehlberg. Die im Einzugsgebiet dominierende Landnutzung istNadelwald mit einem Anteil von 94% an der Gesamtflache. Lediglich amGebietsauslass ist etwas Laubwald (4%) und Landwirtschaft (2%) zu fin-den. Die Geologie ist duch kristallinen Schiefer gepragt, welcher von lehmig,sandigen Boden uberlagert wird (?). Den dominierenden Bodentyp bildetdie Braunerde mit teilweise ausgepragten Parabraunerden. Klimatisch istdas Gebiet den gemaßigten Breiten mit einem mittleren jahrlichen Nieder-schlag von 1436mm fur den Zeitraum von 1990 bis 1999 zuzuordnen. AufGrund der fur Deutschland vergleichsweisen geringen mittleren Jahrestem-peratur von ca. 6,1 ◦C im Gebietsmittel fallt die Verdunstung geringer aus.Die niedrigen Temperaturen sorgen fur einen signifikanten Schneeschmelzein-fluss im Fruhling. Neben der Schneeschmelze haben auf Grund des starken
59

60 KAPITEL 4. VORSTELLUNG DER UNTERSUCHUNGSGEBIETE
Reliefs auch laterale Stromungen großen Einfluss auf die Abflussbildung.Die betrachtete Durchflussmessstationen ist Gehlberg (siehe Abbildung ??).An Niederschlagsdaten wurden die aufgezeichnten Zeitreihen der Messstatio-nen Schmucke, Ilmenau, Luisenthal, Crawinkel, Oberschonenau, Tambach-Dietharz, Dosdorf, Herrenhof, Muhlberg, Herrenhof, Bosleben, Monchenholzhausen,Jena, Erfurt und Gosswitz benutzt. Schneehohen wurden nur an der Schmuckegemessen. Klimadaten uber Temperatur, Luftfeuchte, Windgeschwindigkeitund Sonneneinstrahlung lieferten die Stationen in Erfurt, Schmucke und Ar-tern. Die Daten stehen auf Tagesbasis uber dem Zeitraum von 1979 - 2000 zurVerfugung, so dass fur dieses Einzugsgebiet insgesamt etwa 7.500 Datensatzeverfugbar sind.
Abbildung 4.1: Relief des Einzugsgebietes der Wilden Gera mit dem Bezugs-pegel Gehlberg
4.2 Wipper
Als zweites Flusseinzugsgebiet wurde das Einzugsgebiet der Wipper bis PegelHachelbich gewahlt. Das Einzugsgebiet befindet sich im Norden Thuringens.Die Wipper entspringt im Landkreis Eichsfeld im Ohmgebirge und mundetbei Wipperdorf in die Unstrut. Die Flusslange betragt etwa 95 km. Die Quelleliegt auf einer Hohe von 333m NN. Somit bewaltigt die Wipper bis Hachel-bich einen Hohenunterschied von 161m. Das Einzugsgebiet ist etwa 568 km2
groß. Der mittlere Niederschlag im Einzugsgebiet betragt ungefahr 700mm

4.2. WIPPER 61
fur den Zeitraum 1969 - 1990. Die mittleren Temperaturen im Einzugsge-biet liegen bei etwa 7,0 ◦C in den Berglagen und 8,8 ◦C in den Niederungen.Somit ist auch hier ein deutlicher Einfluß der Schneeschmelze zu beobach-ten. Fast die Halfte des betrachteten Gebietes wird als Ackerland verwendet(46%). Der Rest wird als Grunland genutzt (14%) oder ist von Laub- undNadelwaldern (24% bzw. 8%) bedeckt. An Boden finden sich hauptsachlichBergsandlehme (33%), Schuttlehme (18%), Auenlehme (10%) und Bergleh-me (9%), sowie Braunerden (13%). Abbildung ?? zeigt das von der Wipperdurchflossene Gebiet. Die betrachtete Durchflussmessstation ist Hachelbich.Die Niederschlagsmessstationen sind Bleicherode, Friedrichsthal, Kaltenohm-feld, Neustadt, Rehungen, Steinrode und Worbis und die Schneemessstatio-nen sind Kaltohmfeld und Niedergebra. Die drei betrachteten Klimastatio-nen Erfurt, Artern und Gernroda, die Daten uber Temperatur, Luftfeuchte,Windgeschwindigkeit und Sonneneinstrahlung liefern, befinden sich weitervom Einzugsgebiet entfernt. Die Daten stehen auf Tagesbasis uber dem Zeit-raum von 1969 - 2000 zur Verfugung, so dass fur dieses Einzugsgebiet insge-samt etwa 11.000 Datensatze verfugbar sind.
Abbildung 4.2: Einzugsgebiet der Wipper

62 KAPITEL 4. VORSTELLUNG DER UNTERSUCHUNGSGEBIETE
4.3 Gera
Das Einzugsgebiet der Gera mit dem Pegel in Arnstadt soll das dritte be-trachtete Gebiet sein. Das Gebiet erstreckt sich vom Nordrand des ThuringerWaldes uber die Reinsberge bis in das Thuringer Becken. Die Große des Ge-bietes betragt 173 km2. Die Gera entsteht in Plaue durch den Zusammenflussvon Wilder und Zahmer Gera. Das Einzugsgebiet der Gera stellt also eineErweiterung des Einzugsgebietes der Wilden Gera dar. Die Gera fließt dannin nordlicher Richtung von Plaue uber Dosdorf und Siegelbach nach Arn-stadt. Von dort fließt sie weiter Richtung Erfurt und mundet nordlich vonGebesee in die Unstrut. Zwischen Quelle und dem Bezugspegel in Arnstadtliegt eine Hohendifferenz von 687m. Die Quelle liegt am Großen Beerbergin einer Hohe von 980m NN und der Bezugspegel Arnstadt befindet sichauf einer Hohe von 293m NN. Das Gebiet ist gepragt durch Nadelwalder(58%) und Grunlandschaften (17%). Im Norden befinden sich außerdem eini-ge Acker- und Siedlungsflachen (12% bzw. 5%). An Boden sind hauptsachlichBergsandlehme (48%), Schuttlehme (32%) und Auenlehme (5%) vertre-ten. Klimatisch befindet sich auch dieses Gebiet in den gemaßigten Breitenmit einem mittleren jahrlichen Niederschlag von 961mm fur den Zeitraumvon 1969 bis 1990. Die mittlere Jahrestemperatur liegt in den Hohenlagenbei etwa 6,1 ◦C und in den Tieflagen bei etwa 8,1 ◦C. Durch die niedrigenTemperaturen in den Hohenlagen hat die Schneeschmelze im Fruhling einenspurbaren Einfluss auf die Abflussbildung. Der betrachtete Pegel ist Arn-stadt (siehe Abbildung ??). Als Niederschlagsdaten wurden die aufgezeich-neten Zeitreihen der Messstationen Schmucke, Ilmenau, Luisenthal, Crawin-kel, Oberschonenau, Tambach-Dietharz, Dosdorf, Herrenhof, Muhlberg, Her-renhof, Bosleben, Monchenholzhausen, Jena, Erfurt und Gosswitz benutzt.Schneehohen wurden nur an der Schmucke gemessen. Klimadaten uber Tem-peratur, Luftfeuchte, Windgeschwindigkeit und Sonneneinstrahlung liefertendie Stationen in Erfurt, Schmucke und Artern. Die Daten stehen auf Tages-basis uber dem Zeitraum von 1979 - 2000 zur Verfugung, so dass fur diesesEinzugsgebiet insgesamt etwa 7.500 Datensatze verfugbar sind.
4.4 Roda
Als letztes Einzugsgebiet in Thuringen wird das der Roda betrachtet. DieRoda entspingt in Ostthuringen in Rodaborn nahe Triptis auf einer Hohevon 403m NN, fließt uber die so genannten Talerdorfer (u. a. Renthen-dorf) nach Stadtroda und mundet sudlich von Jena nach insgesamt 243mHohendifferenz in die Saale. Die Roda hat einige Zuflusse wie der Schwarz-

4.4. RODA 63
Abbildung 4.3: Relief des Einzugsgebietes der Gera mit dem BezugspegelArnstadt
bach, Weißbach, Rothehofbach und Zeitzbach, so dass das Einzugsgebiet ins-gesamt etwa 253 km2 umfasst. Davon sind 50% mit Nadelwald bewachsen,25% werden als Ackerland genutzt und weitere 17% sind als Grunland aus-gewiesen. Ahnlich wie in den anderen vorgestellten Gebieten betragt dermittlere Niederschlag auch hier etwa 600mm im Jahr und es treten mittlereJahrestemperaturen zwischen 7 ◦C und 8 ◦C auf. 90% der auftretenden Bo-denarten sind Bergsandlehme. Vereinzelt treten Auenlehmsande (4%) undSchuttlehme (2%) auf. Als Bezugspegel wird der Pegel Zollnitz betrachet.Niederschlagsdaten liefern die Stationen Gohren, Großbockedra, Jena, Kah-la, Mittelpollnitz, Munchenbernsdorf, Ottendorf, Quirla und Stadtroda. Da-ten uber Schneehohen liegen in Gohren und Mittelpollnitz vor. Desweiterenwerden Klimadaten von Erfurt und Artern genutzt. Die Daten sind ubereinen Zeitraum von 1969 bis 2000 auf Tagesbasis verfugbar. Damit liegenetwa 11.500 Datensatze vor.In Tabelle ?? sind die wichtigsten Informationen uber die Einzugsgebiete imUberblick zu sehen.
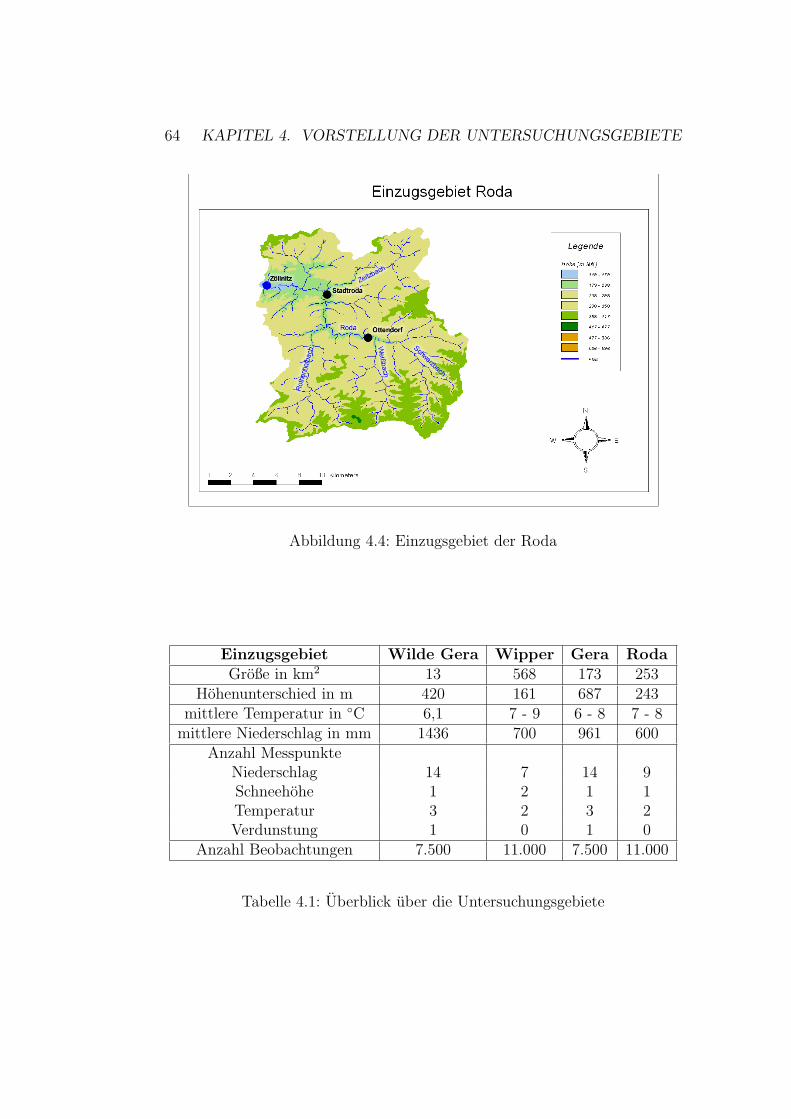
64 KAPITEL 4. VORSTELLUNG DER UNTERSUCHUNGSGEBIETE
Abbildung 4.4: Einzugsgebiet der Roda
Einzugsgebiet Wilde Gera Wipper Gera RodaGroße in km2 13 568 173 253
Hohenunterschied in m 420 161 687 243mittlere Temperatur in ◦C 6,1 7 - 9 6 - 8 7 - 8
mittlere Niederschlag in mm 1436 700 961 600Anzahl Messpunkte
Niederschlag 14 7 14 9Schneehohe 1 2 1 1Temperatur 3 2 3 2Verdunstung 1 0 1 0
Anzahl Beobachtungen 7.500 11.000 7.500 11.000
Tabelle 4.1: Uberblick uber die Untersuchungsgebiete

Kapitel 5
Anwendung
In Kapitel 2 wurde eine allgemeine Beschreibung der Problemstellung gege-ben, fur die Losungsmethoden in Kapitel 3 vorgestellt wurden. Inhalt die-ses Kapitels soll es sein die vorgestellten Methoden auf die Problemstellunganzuwenden. Da es nicht moglich ist, hinreichend prazise Aussagen fur dieallgemeine Problemstellung zu geben, werden die vorgestellten Methoden anden in Kapitel 4 aufgefuhrten Einzugsgebieten untersucht.
5.1 Gaußprozessregression
Begonnen wird mit der Methode der Gaußprozessregression, die in Abschnitt?? beschrieben ist. Es wird zunachst erklart, wie entsprechende Gaußpro-zessmodelle gewahlt werden und dabei auf eine technisch notwendige Verein-fachung eingegangen. Im zweiten Teil des Abschnittes erfolgt die Auswertungund Diskussion des Einsatzes der ausgewahlten Modelle auf den einzelnenEinzugsgebieten.
5.1.1 Modellauswahl
Die Gaußprozesssregression erlaubt, es a priori Wissen in das Modell einflie-ßen zu lassen. Dies geschieht im Wesentlichen durch Auswahl der Kovari-anzfunktionen und deren Parameter. ? messen dem Modellselektionsprozessgroße Bedeutung zu. In dem vorliegenden Fall ist a priori nicht klar, wel-ches Modell zu wahlen ist. Leider ist kein universelles Verfahren bekannt,um eine optimale Auswahl zu treffen. Das Vorgehen wird sich deshalb sogestalten, dass fur jeden freien Modell- beziehungsweise Verfahrensparame-ter eine Menge von moglichen Optionen angegeben wird und anschließendbestimmt wird, welche Optionskombination zu den besten Ergebnisse fuhrt.
65

66 KAPITEL 5. ANWENDUNG
Dazu mussen folgende Parameter festgelegt werden:
• Kovarianzfunktion
• Maß der Modellgute
• Erwartungswertfunktion
• Relevanzzeitraum trel
Fur die Untersuchungen werden folgende Kovarianzfunktionen betrachtet:
• Quadratisch exponentielle Kovarianzfunktion unter Berucksichtigungvon Rauschen
kSE (xi, xj) = exp
(−
n∑l=1
(xl
i − xlj
)2σ2
l
)+ δi,j · σ2
• Rational quadratische Kovarianzfunktion unter Berucksichtigung vonRauschen
kRQ (xi, xj) =
1 +
n∑l=1
(xli−xl
j)2
σ2l
2α
−α
+ δi,j · σ2
• Neural Network Kovarianzfunktion unter Berucksichtigung von Rau-schen
kNN (xi, xj) =2
πsin−1
2xTi Σxj√
(1 + 2xTi Σxi)
(1 + 2xT
j Σxj
)+ δi,j · σ2
mit
Σi,j =
(δi,j
σ2i
)Fur die Parameteroptimierung werden alle drei vorgestellten Kriterien ver-wendet. Das sind im Einzelnen die marginal likelihood (ML), die erwarte-te logarithmierte Wahrscheinlichkeit uber der
”Leave One Out - Kreuzval-
dierung“ (LLOO) und der mittlere quadratische Fehler uber der Leave OneOut - Kreuzvaldierung (LMSE). Desweiteren wird die mogliche Auswahl umzwei verschiedene Funktionen zur Modellierung der Erwartungswertfunktion

5.1. GAUSSPROZESSREGRESSION 67
m (x) (siehe Abschnitt ?? ) erweitert. Zum einen wird fur m (x) eine Kon-stante c gewahlt, mit der Intention, dass kein klarer Trend in den Datenzu erkennen ist und zum anderen wird eine lineare Funktion m (x) = wT xverwendet, wodurch ein linearer Trend modelliert werden kann. Als letztenSelektionsparameter wird der Relevanzzeitraum trel betrachtet. Insbesondereist es von Interesse, ob eine Verbesserung zu erwarten ist, falls die Eingabe-daten mehrere Tage umfassen.Um ein Maß dafur zu erhalten, wie gut sich diese Kovarianzfunktionen eig-nen, wird eine Kreuzvalidierung durchgefuhrt. Dieses Verfahren ist in ??beschrieben. Bei dieser Methode wird ausschließlich die Trainingsmengedazu genutzt, das Modell zu erzeugen und die unbekannten Parameter dereinzelnen Kovarianzfunktionen zu bestimmen (wie in ?? beschrieben).Bei der Suche nach geeigneten Modellen wurde festgestellt, dass das Gra-dientenabstiegsverfahren vergleichsweise schnell ist, das heißt selten mehrals 100 Iterationen benotigt, um in den Konvergenzbereich zu gelangen. DieDurchfuhrung eines einzelnen Schrittes ist aber trotzdem mit einer Zeitkom-plexitat von O (n3) verbunden. In Anbetracht der Große der Trainingsmenge,die im Bereich von etwa 10.000 Datensatzen liegt, stellt dies einen kaum zubewaltigenden Rechenaufwand dar.
5.1.2 Auswahl von Trainingsbeispielen
Deshalb ist es gunstig auf einen Teil der n Trainingsdaten zu verzichten undnur m ≤ n Datenpunkte in die tatsachliche Trainingsmenge aufzunehmen.Wie aber wird entschieden, welche Daten gewahlt werden sollen? Zunachstwird ein Maß benotigt, welches angibt wie gut oder schlecht eine Menge vonausgewahlten Daten fur den Lernprozess ist. Hierfur wird die Standardabwei-chung gewahlt, da es sinnvoll erscheint moglichst vielfaltige Beobachtungenbereit zustellen. Eine Alternative ware den mittlere Informationsgehalt dergewahlten Daten als Kriterium zu benutzen. Das Ziel besteht also darin, eineMenge D ⊂ D mit |D| = m anzugeben, die die der Eigenschaft besitzt, dass
σ(D)
maximal ist. Auf Grund der kombinatorischen Komplexitat ist anzu-
nehmen, dass exakte Algorithmen fur die Berechnung dieser Menge ein zuschlechtes Laufzeitverhalten aufweisen. Deshalb wird hier nach einer GreedyStrategie verfahren. Diese approximiert iterativ die gesuchte Menge. Ausge-hend von einer aktuellen Trainingsmenge Ti wird eine neue TrainingsmengeTi+1 berechnet, indem ein noch nicht gewahlter Datenpunkt x hinzu genom-men wird. Die Auswahlregel fur x ist so beschaffen, dass sie zu einer lokalenMaximierung der Standardabweichung fuhrt. In Algorithmus ?? ist das Ver-fahren dargestellt. Die hier vorgestellte Variante benotigt O (n2m) Rechen-schritte. Durch inkrementelle Berechnung der Standardabweichung lasst sich

68 KAPITEL 5. ANWENDUNG
dies auf O (nm) verbessern.
Algorithmus 5.1.1 : Verfahren zur Auswahl von Trainingsdaten
Input : Trainingsmenge D, Große der neuen Menge mOutput : Approximationsmenge DT0 := ∅1
for i = 1 to m do2
σ∗ := 03
foreach x ∈ D\Ti−1 do4
σx := CalcStandardDeviation (Ti−1 ∪ {x})5
if σx ≥ σ∗ then6
σ∗ := σx7
x∗ := x8
end9
end10
Ti := Ti−1 ∪ {x∗}11
end12
D := Tm13
Es wird nun untersucht, welche Auswirkungen die Datenreduktion nach die-ser Greedy Strategie hat. Dazu wird ein einfaches Gaußprozessregressionsmo-dell erstellt. Als Kovarianzfunktion wird die quadratisch exponentielle Ko-varianzfunktion mit zusatzlichem Rauschterm gewahlt. Damit sind lediglichdie Parameter l2 und σ2 per Gradientabstiegsverfahren zu optimieren. DieEingabe umfasst genau einen Tag der Vergangenheit (trel = 1). Es wird nunbetrachtet, wie sich die Genauigkeit der Vorhersagen in Abhangigkeit zu derAnzahl der gewahlten Trainingsdaten verhalt. Insgesamt stehen jeweils 4.500Trainingsdaten (|D) | = 4.500) zur Verfugung von denen 50, 100, 250, 500,1000, 1.500, 2.000 und 2.500 Datensatze ausgewahlt wurden. Der Fehler derVorhersagen wird mit dem mittleren quadratischen Fehler angegeben. DieErgebnisse sind in Abbildung ?? dargestellt.Zunachst ist zu bemerken, dass alle Kurven monoton fallend sind, das heißtin allen Einzugsgebieten hat die Hinzunahme von Trainingsdaten zu einerVerbesserung des resultierenden Modells gefuhrt. Modelle, die auf Basis vonwenigen Daten erstellt wurden, produzieren vergleichsweise großen Fehler.Allerdings ist auch zu sehen, dass dieser Fehler im ersten Teil der Kurveschnell abnimmt, dann aber bereits ab 1.000 - 1.500 selektierten Trainings-beispielen stagniert. Somit reicht bereits ein Anteil von 20 - 35% der Gesamt-datenmenge fur die Durchfuhrung des Trainingsprozesses aus. Dies heißt aber

5.1. GAUSSPROZESSREGRESSION 69
Wilde Gera
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0 500 1000 1500 2000 2500
Anzahl ausgewählter Daten
MS
E
(a)
Wipper
0
0.5
1
1.5
2
2.5
3
0 500 1000 1500 2000 2500
Anzahl ausgewählter Daten
MS
E
(b)
Arnstadt
0
0.2
0.4
0.6
0.8
1
0 500 1000 1500 2000 2500
Anzahl ausgewählter Daten
MS
E
(c)
Roda
0
0.2
0.4
0.6
0.8
1
0 500 1000 1500 2000 2500
Anzahl ausgewählter Daten
MS
E
(d)
Abbildung 5.1: Vorhersagenfehler, in Abhangigkeit von der Anzahl der aus-gewahlten Trainingsdaten
nicht, dass ein Anwachsen der Gesamtdatenmenge zu keinen weiteren Verbes-serungen fuhrt, sondern zeigt lediglich, dass der großte Teil der Daten keineneuen Informationen liefert, die verwertet werden konnten. Eine moglicheErklarung hierfur ist, dass nur etwa 40% der betrachteten Datensatze Nie-derschlage uber 0,5 mm aufweisen.
”Trockene“ Tage liefern vergleichsweise
wenige Informationen. Auf jeden Fall zeigt diese Beobachtung, dass es voll-kommen ausreichend ist, lediglich 40% aller Datensatze zu verwenden, wenndiese mit der angegebenen Greedy Strategie gewahlt werden.Man kann nun mit der Problematik der Parameteroptimierung fortfahren.Als ersten soll untersucht werden, ob die Methode zur automatischen Be-stimmung der Relevanz (Abschnitt ??) sinnvolle Ergebnisse bei der Anwen-dung auf der Problemstellung liefern kann. Dazu wird jeder Datensatz umeinen zufalligen Wert erweitert, welcher nach einer Gleichverteilung auf demIntervall [0, 1] generiert wird. Im Anschluß wird die Optimierung der Mo-dellparameter auf einer ausgewahlten Menge von 500 Eingabedatensatzendurchgefuhrt. Die Ergebnisse sind in Tabelle ?? zusammengefasst.
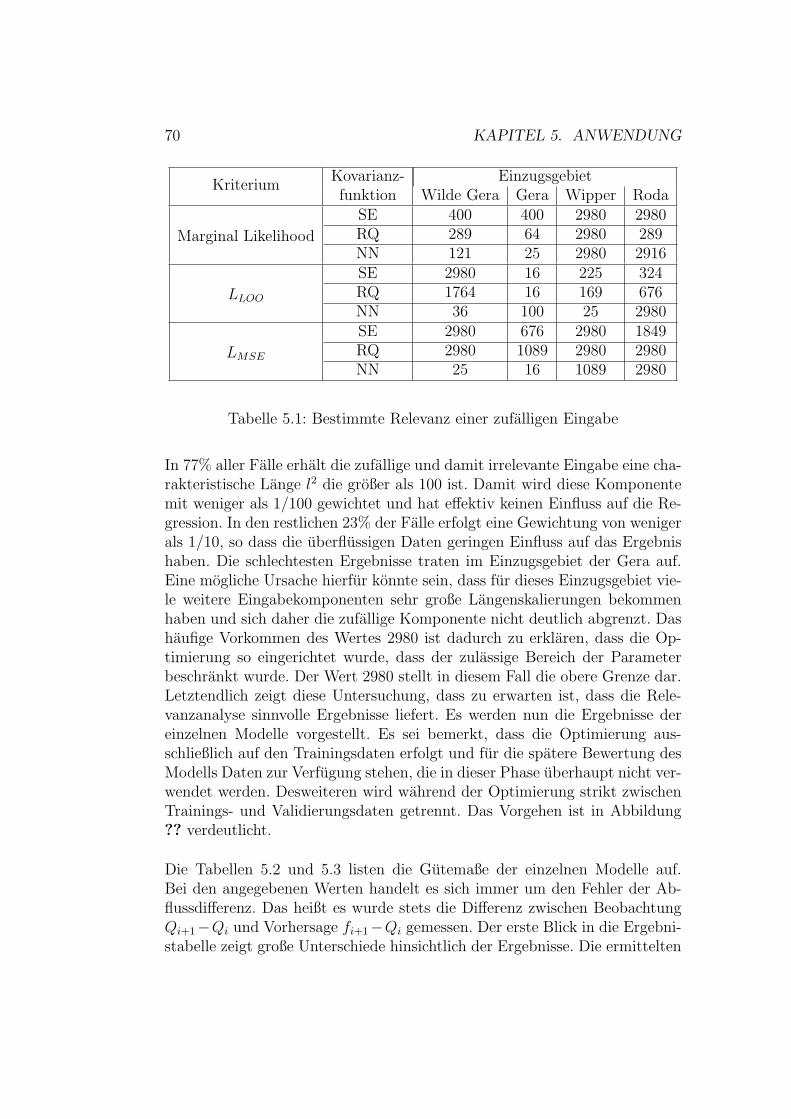
70 KAPITEL 5. ANWENDUNG
Kovarianz- EinzugsgebietKriterium
funktion Wilde Gera Gera Wipper RodaSE 400 400 2980 2980RQ 289 64 2980 289Marginal LikelihoodNN 121 25 2980 2916SE 2980 16 225 324RQ 1764 16 169 676LLOO
NN 36 100 25 2980SE 2980 676 2980 1849RQ 2980 1089 2980 2980LMSE
NN 25 16 1089 2980
Tabelle 5.1: Bestimmte Relevanz einer zufalligen Eingabe
In 77% aller Falle erhalt die zufallige und damit irrelevante Eingabe eine cha-rakteristische Lange l2 die großer als 100 ist. Damit wird diese Komponentemit weniger als 1/100 gewichtet und hat effektiv keinen Einfluss auf die Re-gression. In den restlichen 23% der Falle erfolgt eine Gewichtung von wenigerals 1/10, so dass die uberflussigen Daten geringen Einfluss auf das Ergebnishaben. Die schlechtesten Ergebnisse traten im Einzugsgebiet der Gera auf.Eine mogliche Ursache hierfur konnte sein, dass fur dieses Einzugsgebiet vie-le weitere Eingabekomponenten sehr große Langenskalierungen bekommenhaben und sich daher die zufallige Komponente nicht deutlich abgrenzt. Dashaufige Vorkommen des Wertes 2980 ist dadurch zu erklaren, dass die Op-timierung so eingerichtet wurde, dass der zulassige Bereich der Parameterbeschrankt wurde. Der Wert 2980 stellt in diesem Fall die obere Grenze dar.Letztendlich zeigt diese Untersuchung, dass zu erwarten ist, dass die Rele-vanzanalyse sinnvolle Ergebnisse liefert. Es werden nun die Ergebnisse dereinzelnen Modelle vorgestellt. Es sei bemerkt, dass die Optimierung aus-schließlich auf den Trainingsdaten erfolgt und fur die spatere Bewertung desModells Daten zur Verfugung stehen, die in dieser Phase uberhaupt nicht ver-wendet werden. Desweiteren wird wahrend der Optimierung strikt zwischenTrainings- und Validierungsdaten getrennt. Das Vorgehen ist in Abbildung?? verdeutlicht.
Die Tabellen 5.2 und 5.3 listen die Gutemaße der einzelnen Modelle auf.Bei den angegebenen Werten handelt es sich immer um den Fehler der Ab-flussdifferenz. Das heißt es wurde stets die Differenz zwischen BeobachtungQi+1−Qi und Vorhersage fi+1−Qi gemessen. Der erste Blick in die Ergebni-stabelle zeigt große Unterschiede hinsichtlich der Ergebnisse. Die ermittelten
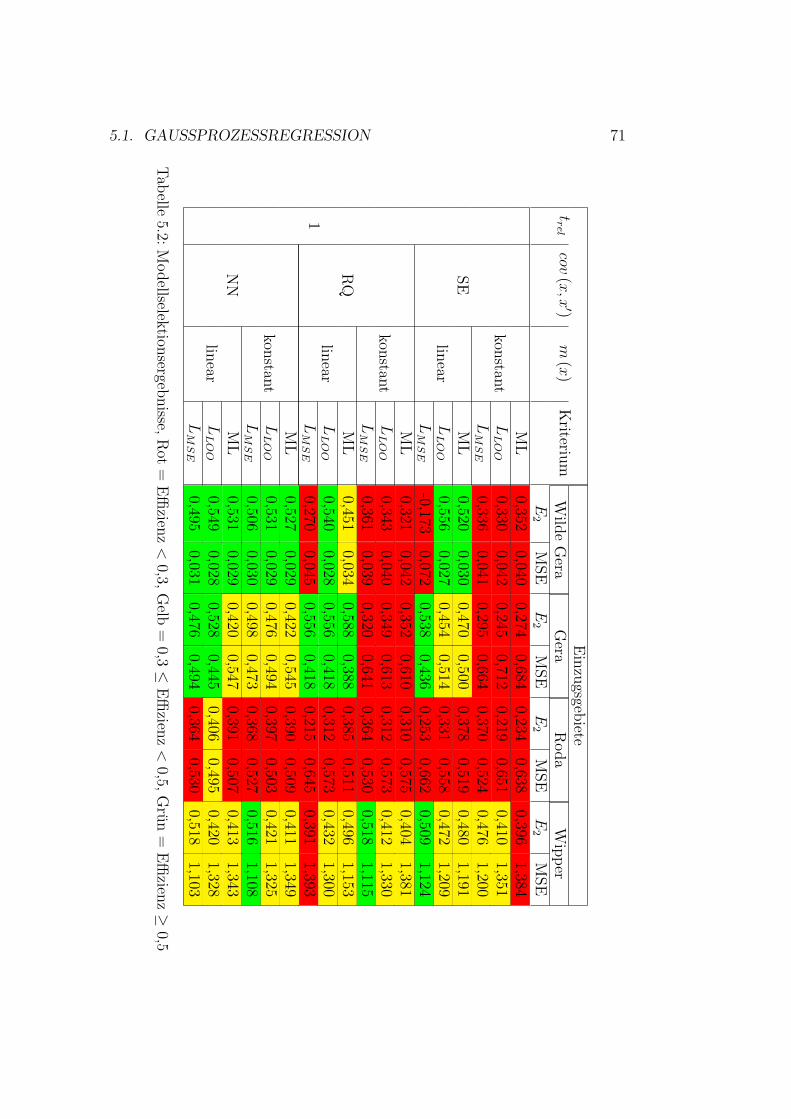
5.1. GAUSSPROZESSREGRESSION 71
Ein
zugsgeb
ieteW
ilde
Gera
Gera
Roda
Wip
per
trel
cov(x
,x′)
m(x
)K
riterium
E2
MSE
E2
MSE
E2
MSE
E2
MSE
ML
0,3520,040
0,2740,684
0,2340,638
0,3961,384
LL
OO
0,3300,042
0,2450,712
0,2190,651
0,4101,351
konstan
tL
MS
E0,336
0,0410,295
0,6640,370
0,5240,476
1,200M
L0,520
0,0300,470
0,5000,378
0,5190,480
1,191L
LO
O0,556
0,0270,454
0,5140,331
0,5580,472
1,209SE
linear
LM
SE
-0,1730,072
0,5380,436
0,2530,662
0,5091,124
ML
0,3210,042
0,3520,610
0,3100,575
0,4041,381
LL
OO
0,3430,040
0,3490,613
0,3120,573
0,4121,330
konstan
tL
MS
E0,361
0,0390,320
0,6410,364
0,5300,518
1,115M
L0,451
0,0340,588
0,3880,385
0,5110,496
1,153L
LO
O0,540
0,0280,556
0,4180,312
0,5730,432
1,300R
Q
linear
LM
SE
0,2700,045
0,5560,418
0,2150,645
0,3911,393
ML
0,5270,029
0,4220,545
0,3900,509
0,4111,349
LL
OO
0,5310,029
0,4760,494
0,3970,503
0,4211,325
konstan
tL
MS
E0,506
0,0300,498
0,4730,368
0,5270,516
1,108M
L0,531
0,0290,420
0,5470,391
0,5070,413
1,343L
LO
O0,549
0,0280,528
0,4450,406
0,4950,420
1,328
1
NN
linear
LM
SE
0,4950,031
0,4760,494
0,3640,530
0,5181,103
Tab
elle5.2:
Modellselek
tionsergeb
nisse,
Rot
=E
ffizien
z<
0,3,G
elb=
0,3≤
Effi
zienz
<0,5,
Gru
n=
Effi
zienz≥
0,5
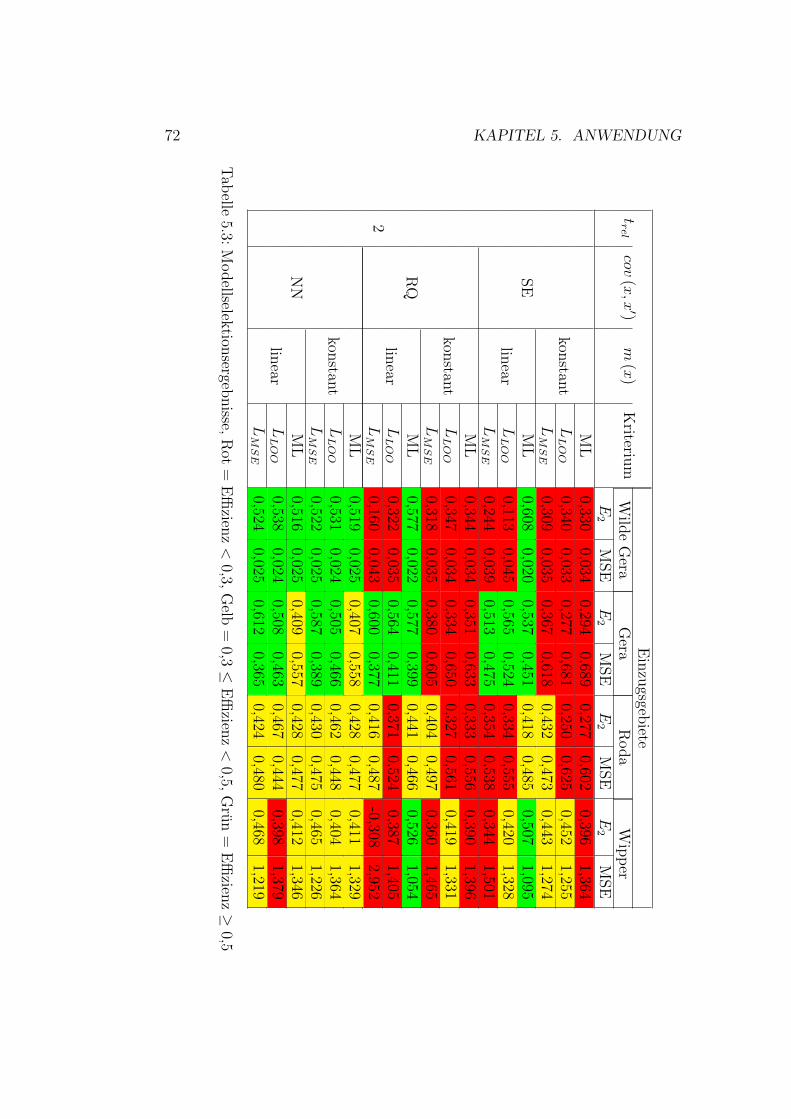
72 KAPITEL 5. ANWENDUNGE
inzu
gsgebiete
Wild
eG
eraG
eraR
oda
Wip
per
trel
cov(x
,x′)
m(x
)K
riterium
E2
MSE
E2
MSE
E2
MSE
E2
MSE
ML
0,3300,034
0,2940,689
0,2770,602
0,3961,364
LL
OO
0,3400,033
0,2770,681
0,2500,625
0,4521,255
konstan
tL
MS
E0,309
0,0350,367
0,6180,432
0,4730,443
1,274M
L0,608
0,0200,537
0,4510,418
0,4850,507
1,095L
LO
O0,113
0,0450,565
0,5240,334
0,5550,420
1,328SE
linear
LM
SE
0,2440,039
0,5130,475
0,3540,538
0,3441,501
ML
0,3440,034
0,3510,633
0,3330,556
0,3901,396
LL
OO
0,3470,034
0,3340,650
0,3270,561
0,4191,331
konstan
tL
MS
E0,318
0,0350,380
0,6050,404
0,4970,360
1,465M
L0,577
0,0220,577
0,3990,441
0,4660,526
1,054L
LO
O0,322
0,0350,564
0,4110,371
0,5240,387
1,405R
Q
linear
LM
SE
0,1600,043
0,6000,377
0,4160,487
-0,3082,952
ML
0,5190,025
0,4070,558
0,4280,477
0,4111,329
LL
OO
0,5310,024
0,5050,466
0,4620,448
0,4041,364
konstan
tL
MS
E0,522
0,0250,587
0,3890,430
0,4750,465
1,226M
L0,516
0,0250,409
0,5570,428
0,4770,412
1,346L
LO
O0,538
0,0240,508
0,4630,467
0,4440,398
1,379
2
NN
linear
LM
SE
0,5240,025
0,6120,365
0,4240,480
0,4681,219
Tab
elle5.3:
Modellselek
tionsergeb
nisse,
Rot
=E
ffizien
z<
0,3,G
elb=
0,3≤
Effi
zienz
<0,5,
Gru
n=
Effi
zienz≥
0,5

5.1. GAUSSPROZESSREGRESSION 73
Verfügbare Daten
TrainingsdatenValdierungsdaten
Vorbehalten für
spätere
Modellevaluation
Vorbehalten für
spätere
Modellevaluation
Kreuzvalidierung
Abbildung 5.2: Verwaltung der Datenmenge
E2 Werte schwanken zwischen -0,308 und 0,621. Das schlechteste Ergebniswurde mit einer rational quadratischen Kovarianzfunktion, linearem Trendund dem LMSE Kriterium beobachtet. Insgesamt fallt auf, dass sich die qua-dratisch exponentielle Kovarianzfunktion oft deutlich schlechter verhalt alsdie rational quadratische Kovarianzfunktion. Diese wiederum ist oft schlech-ter geeignet als die neuronale Netzwerk Kovarianzfunktion. Die Unterschiedesind in diesem Fall aber viel geringer ausgepragt und lassen sich einfach er-klaren. Ein weiterer Blick zeigt, dass eine linearen Erwartungswertfunktionin etwa 2/3 aller Falle das Ergebnis verbessert hat. Vor allem bei quadra-tisch exponentiellen und rational quadratischen Kovarianzfunktionen sindsehr deutliche Verbesserungen zu erkennen, wahrend diese bei neuronalenNetzwerk Kovarianzfunktionen eher moderat ausfallen. Als Grund hierfur istzu sehen, dass neuronale Netzwerk Kovarianzfunktionenen nicht stationarsind. Damit wird durch die Anpassung der Funktionsparameter implizit einTrend modelliert. Somit ist zu erwarten, dass die zusatzliche explizite Auswei-sung eines linearen Trendes weniger Gewinn bringt, als dies bei stationarenFunktionen der Fall ist. Die fehlende Moglichkeit, einen Trend in den Da-ten zu berucksichtigen, ist sicher auch dafur verantwortlich, dass rationalquadratische Kovarianzfunktionen oft schlechter abschneiden als neuronaleNetzwerk Kovarianzfunktionen. Recht interessant ist auch die Tatsache, dasseine Erweiterung des Relevanzzeitraumes (trel = 2) in den Einzugsgebietender Wilden Gera, Gera und der Roda zu signifikanten Verbesserungen fuhrt,wahrend dies fur die Modelle der Wipper kaum Einfluss hat. Bezuglich derverwendeten Optimierungskriterien lasst sich kein klarer Trend erkennen. Im

74 KAPITEL 5. ANWENDUNG
direkten Vergleich lieferte das marginal likelihood Kriterium in 17% allerFalle das beste Ergebnis, LLOO in 39% aller Falle und LMSE in 44% derFalle. Es lasst sich feststellen, dass einige Modelle, die auf Grundlage desLMSE Kriteriums entstanden sind sehr schlechte Ergebnisse lieferten. In denweiteren Betrachtungen werden nur die besten gefundenen Modelle weiterverwendet, im Einzelnen sind dies:
• Wilde Gera:Quadratisch exponentielle Kovarianzfunktion mit linearen Trend, mar-ginal likelihood als Optimierungskriterium und zwei Tage umfassendeEingabe
• Gera:Neuronale Netzwerk Kovarianzfunktion mit linearen Trend, LMSE alsOptimierungskriterium und zwei Tage umfassende Eingabe
• Roda:Neuronale Netzwerk Kovarianzfunktion mit linearen Trend, LLOO alsOptimierungskriterium und zwei Tage umfassende Eingabe
• Wipper:Rational quadratische Kovarianzfunktion mit linearen Trend und mar-ginal likelihood als Optimierungskriterium und zwei Tage umfassendeEingabe
5.1.3 Modellevaluation
Inhalt dieses Abschnittes ist es, die ausgewahlten Modelle zu bewerten. Eswerden Aussagen uber die Vorhersagegenauigkeit getroffen, die zu erwarten-den Unsicherheiten bestimmt und Aussagen aus den gewonnenen Parameternabgeleitet. Die Evaluation der Modelle wurde in diesem Abschnitt mit einereinfachen Validierung durchgefuhrt. Dabei wurden jeweils die letzten 1.000Datensatze als Validierungsdatensatze verwendet. Diese Datensatze wurdenbisher nicht verwendet. Die restlichen Datensatze werden fur den Model-lerstellungsprozess benutzt. Fur jedes Einzugsgebiet, werden zuerst die Ab-flussdiagramme betrachtet und anschließend Aussagen mit Hilfe der gewon-nenen Parametern getroffen.Insgesamt lasst sich sagen, dass die ausgewahlten Modelle gute Ergebnisseliefern. Dies wird bereits in den Abflussdiagrammen sichtbar (Abbildungen5.3 - 5.6). Die E2 Werte und der mittlere quadratische Fehler der absolutenund relativen Abflusse sind in Tabelle 5.4 zusammengefasst.

5.1. GAUSSPROZESSREGRESSION 75
E2 absolut E2 relativ MSEWilde Gera 0,90 0,65 0,02
Gera 0,95 0,60 0,25Roda 0,54 0,59 0,26
Wipper 0,95 0,59 0,46
Tabelle 5.4: Vorhersagegenauigkeit
Die absoluten Effizienzen liegen großtenteils uber 0,9, die relativen Effizien-zen alle bei etwa 0,6. Lediglich die berechneten Abflusse der Roda weichenteilweise stark von den Beobachtungen ab, was sich in einem niedrigen E2
Wert von 0, 54 niederschlagt. Trotzdem haben alle Modelle, die wahrendder Modellselektionsphase erzielte Genauigkeit ubertroffen. Die großten Feh-ler, treten bei allen Modellen in denselben Situationen auf. Die Problemsi-tuationen sind Schneeschmelzen im Fruhling und extrem niederschlagsreicheZeitraume. Die Problematik besteht darin, dass dies relativ seltene Ereignissesind und daher wenige Beobachtungen Informationen uber das entsprechendeAbflussverhalten liefern. Das Regressionsproblem wird dann zu einen Extra-polationsproblem. Es wird zwar in fast allen Fallen eine ausgepragte Ab-flussspitze berechnet, deren Amplitude aber oft stark von den beobachtetenWerten abweicht. Bei Schneeschmelzen kommt die schlechte Datenlage hinzu.Fur die meisten Einzugsgebiete steht nur eine Messung der Schneehohe zurVerfugung. Dies ist kaum ausreichend um ein Schatzung fur die geschmolzeneSchneemenge zu erhalten.Es werden nun die optimalen Parameter diskutiert. Die meisten Parame-ter sind charakteristische Langenskalierungen der einzelnen Eingabekompo-nenten. Einzugsgebietubergreifend lassen sich dabei einige Gemeinsamkei-ten, aber auch große Unterschiede bemerken. Zunachst lasst sich feststellen,dass in allen Einzugsgebieten etwa die Halfte der Eingabekomponenten eineLangenskalierung erhalten hat, deren Wert 100 uberschreitet. Diese Kompo-nenten haben damit effektiv keinen Einfluss auf die Berechnung und konntenkomplett entfernt werden. Lediglich im Einzugsgebiet der Wipper wurdennur 30% aller Komponenten als nicht relevant eingestuft. Bei der weiterenBetrachtung ist es ersichtlich, dass die Messwerte des letzten Tages (t − 1)meistens relevanter sind als die Messwerte des vorletzten Tages (t−2). DieseBeobachtung war zu erwarten, da der Oberflachenabfluss ausmacht, der denVorfluter sehr schnell erreicht, einen enormen Einfluss hat. Ausnahme hier istdas Einzugsgebiet der Gera. Werden die einzelnen Komponenten betrachet,so ist die Relevanz des akuellen Abflusses außerst hoch. Abgesehen vom po-tentiellen Verdunstungswert, der stets kaum Beachtung findet, lasst sich in

76 KAPITEL 5. ANWENDUNG
allen anderen Komponenten kein eindeutiger Trend feststellen. In den Ein-zugsgebieten der Gera und Wilden Gera wurden vor allem Niederschlagswerteignoriert, die weiter als 15 km vom Einzugsgebiet entfernt gemessen wurden.Fur diese Gebiete scheinen auch die Schneedifferenzen unbedeutender zu seinals die absoluten Schneehohen, wahrend dies in den anderen Einzugsgebietennicht der Fall ist. Interessante Informationen liefert auch der Parameter σ2.Dieser ist ein Maß dafur, wie stark die Daten durch Rauschen interpretiertwerden. Ein kleiner σ2 - Wert heißt, dass das Modell die Daten durch we-nig Rauschen interpretiert und somit nahezu eine Interpolation durchfuhrt.Dem gegenuber fuhrt ein großer σ2 Wert dazu, dass die Daten im Wesent-lichen als
”zufallig“ betrachtet werden. Fur die Modelle der Einzugsgebiete
Wilde Gera und Gera wurden σ2 Werte bestimmt, die kleiner als 0, 01 sind.Desweiteren zeichnen sich diese beiden Modelle durch eine geringe Signalva-riation aus, das heißt die charakteristischen Langen sind insgesamt nicht zukurz. Dies fuhrt zu kleinen Varianzen des a posterio Prozesses. Damit sinddie berechneten Vorhersagen, zumindest auf Grundlage des Modelles, als sehrsicher anzunehmen. Im Gegensatz dazu zeigen die Modelle fur die Wipperund Roda, mit einem σ2-Wert der großer als eins ist eine wesentlich starkereBerucksichtigung des Rauschens. Beide Modelle weisen zudem eine schnelleSignalvariation auf, wie an den vielen extrem kurzen Langenskalierungen er-kennbar ist. Dies kann als Hinweis interpretiert werden, dass diese Modelleeine großere Unsicherheit aufweisen, obwohl fur das Einzugsgebiet der Wip-per sehr gute Ergebnisse geliefert werden.In den Abbildungen 5.3 - 5.6 sind die Konfidenzintervalle der Vorhersagengrau unterlegt. Diese geben das 0, 95 Quantil eines normalverteilten relativenFehlers an.
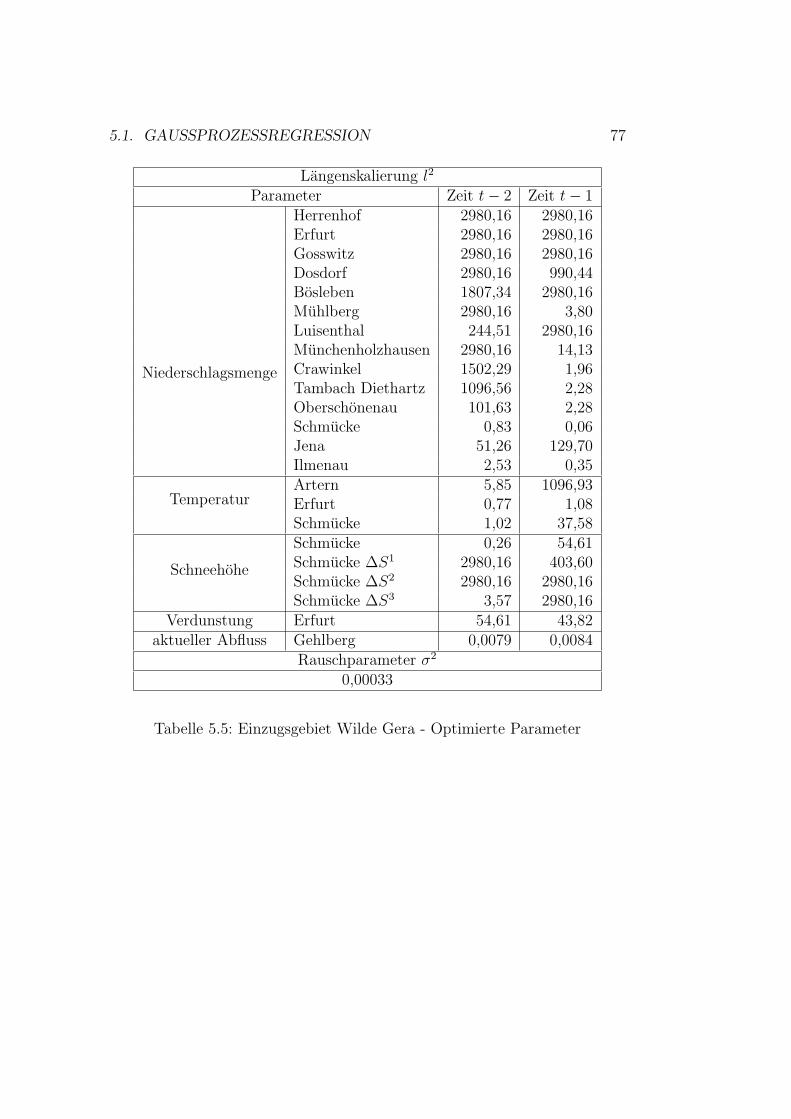
5.1. GAUSSPROZESSREGRESSION 77
Langenskalierung l2
Parameter Zeit t− 2 Zeit t− 1Herrenhof 2980,16 2980,16Erfurt 2980,16 2980,16Gosswitz 2980,16 2980,16Dosdorf 2980,16 990,44Bosleben 1807,34 2980,16Muhlberg 2980,16 3,80Luisenthal 244,51 2980,16Munchenholzhausen 2980,16 14,13Crawinkel 1502,29 1,96Tambach Diethartz 1096,56 2,28Oberschonenau 101,63 2,28Schmucke 0,83 0,06Jena 51,26 129,70
Niederschlagsmenge
Ilmenau 2,53 0,35Artern 5,85 1096,93Erfurt 0,77 1,08Temperatur
Schmucke 1,02 37,58Schmucke 0,26 54,61Schmucke ∆S1 2980,16 403,60Schmucke ∆S2 2980,16 2980,16
Schneehohe
Schmucke ∆S3 3,57 2980,16Verdunstung Erfurt 54,61 43,82
aktueller Abfluss Gehlberg 0,0079 0,0084Rauschparameter σ2
0,00033
Tabelle 5.5: Einzugsgebiet Wilde Gera - Optimierte Parameter
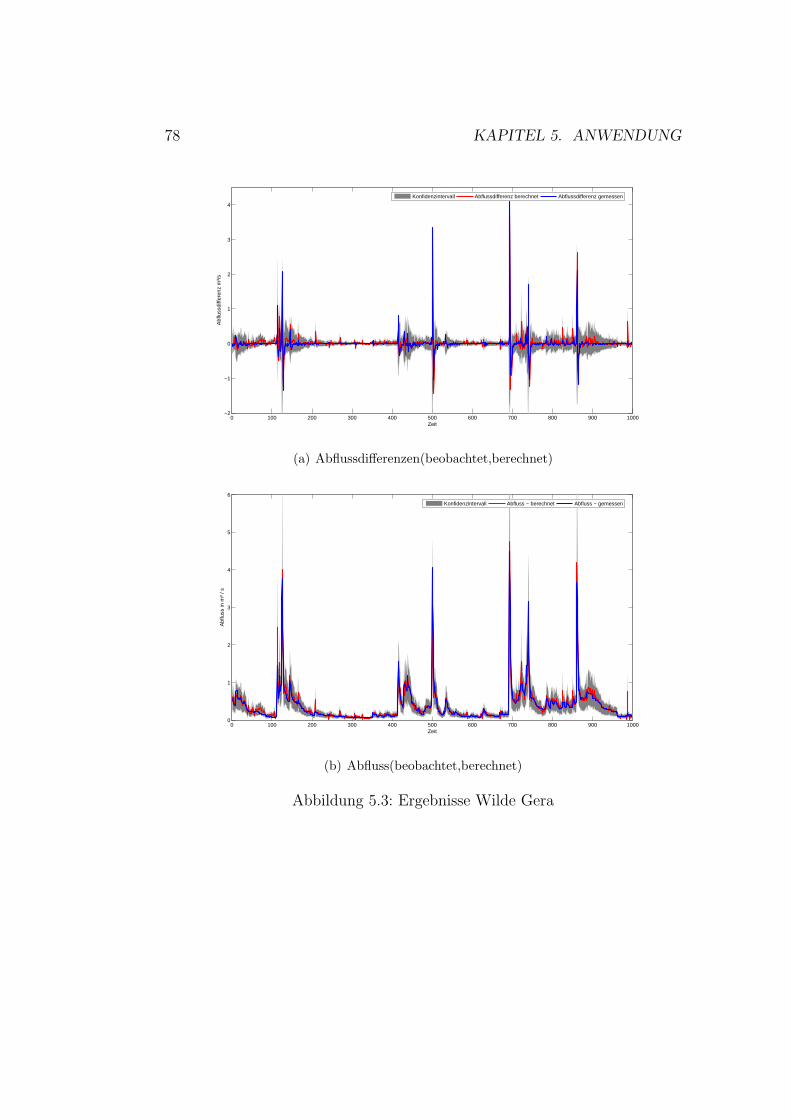
78 KAPITEL 5. ANWENDUNG
0 100 200 300 400 500 600 700 800 900 1000−2
−1
0
1
2
3
4
Zeit
Abf
luss
diffe
renz
m³/
s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
1
2
3
4
5
6
Zeit
Abf
luss
in m
³ / s
Konfidenzintervall Abfluss − berechnet Abfluss − gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.3: Ergebnisse Wilde Gera
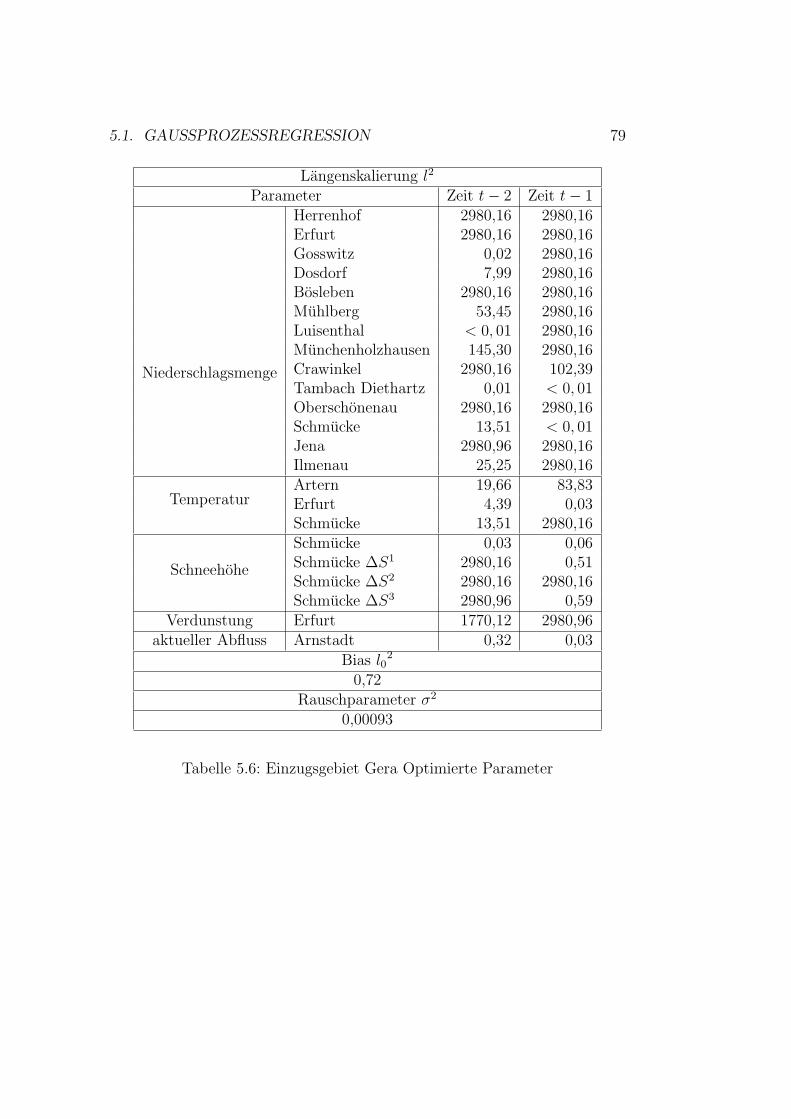
5.1. GAUSSPROZESSREGRESSION 79
Langenskalierung l2
Parameter Zeit t− 2 Zeit t− 1Herrenhof 2980,16 2980,16Erfurt 2980,16 2980,16Gosswitz 0,02 2980,16Dosdorf 7,99 2980,16Bosleben 2980,16 2980,16Muhlberg 53,45 2980,16Luisenthal < 0, 01 2980,16Munchenholzhausen 145,30 2980,16Crawinkel 2980,16 102,39Tambach Diethartz 0,01 < 0, 01Oberschonenau 2980,16 2980,16Schmucke 13,51 < 0, 01Jena 2980,96 2980,16
Niederschlagsmenge
Ilmenau 25,25 2980,16Artern 19,66 83,83Erfurt 4,39 0,03Temperatur
Schmucke 13,51 2980,16Schmucke 0,03 0,06Schmucke ∆S1 2980,16 0,51Schmucke ∆S2 2980,16 2980,16
Schneehohe
Schmucke ∆S3 2980,96 0,59Verdunstung Erfurt 1770,12 2980,96
aktueller Abfluss Arnstadt 0,32 0,03
Bias l02
0,72Rauschparameter σ2
0,00093
Tabelle 5.6: Einzugsgebiet Gera Optimierte Parameter
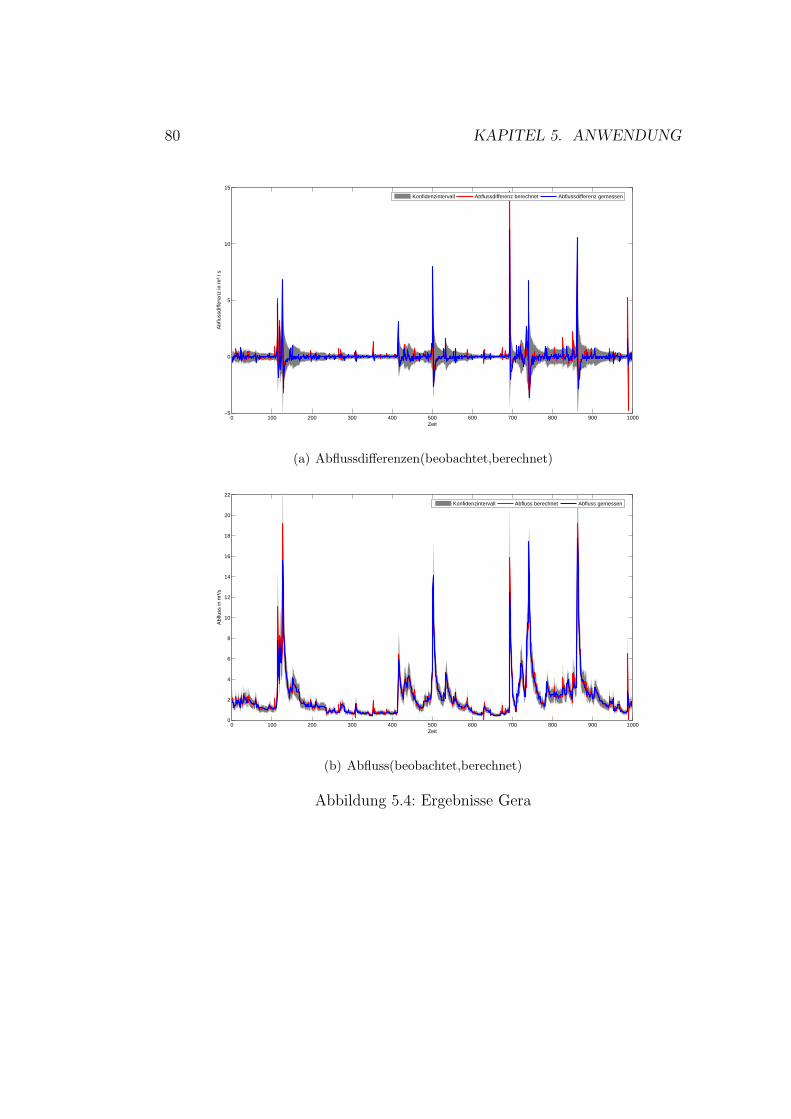
80 KAPITEL 5. ANWENDUNG
0 100 200 300 400 500 600 700 800 900 1000−5
0
5
10
15
Zeit
Abf
luss
diffe
renz
in m
³ / s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
2
4
6
8
10
12
14
16
18
20
22
Zeit
Abf
luss
in m
³/s
Konfidenzintervall Abfluss berechnet Abfluss gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.4: Ergebnisse Gera
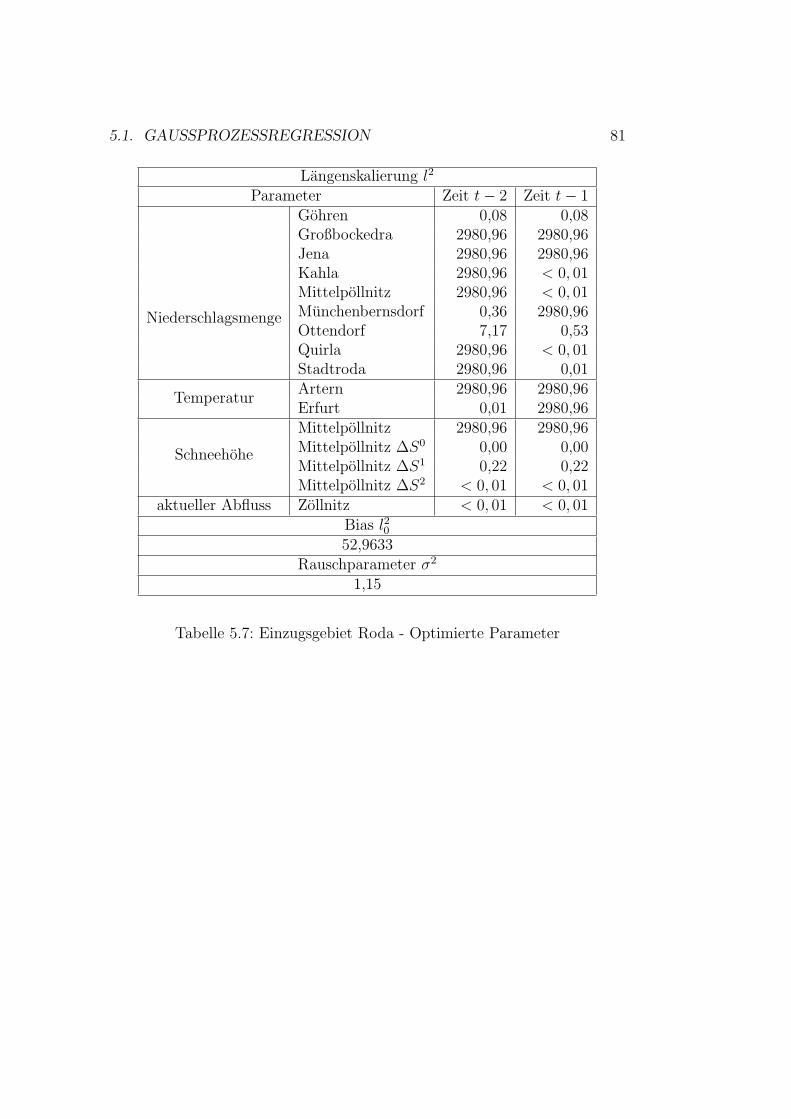
5.1. GAUSSPROZESSREGRESSION 81
Langenskalierung l2
Parameter Zeit t− 2 Zeit t− 1Gohren 0,08 0,08Großbockedra 2980,96 2980,96Jena 2980,96 2980,96Kahla 2980,96 < 0, 01Mittelpollnitz 2980,96 < 0, 01Munchenbernsdorf 0,36 2980,96Ottendorf 7,17 0,53Quirla 2980,96 < 0, 01
Niederschlagsmenge
Stadtroda 2980,96 0,01Artern 2980,96 2980,96
TemperaturErfurt 0,01 2980,96Mittelpollnitz 2980,96 2980,96Mittelpollnitz ∆S0 0,00 0,00Mittelpollnitz ∆S1 0,22 0,22
Schneehohe
Mittelpollnitz ∆S2 < 0, 01 < 0, 01aktueller Abfluss Zollnitz < 0, 01 < 0, 01
Bias l2052,9633
Rauschparameter σ2
1,15
Tabelle 5.7: Einzugsgebiet Roda - Optimierte Parameter
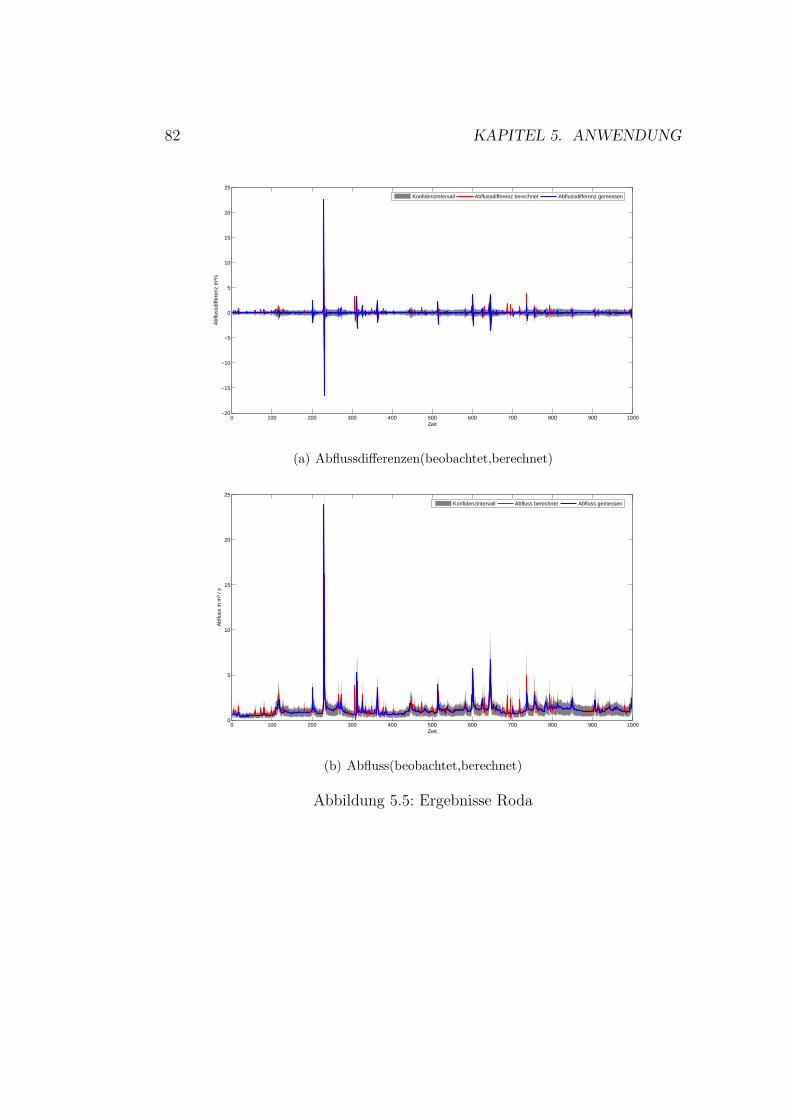
82 KAPITEL 5. ANWENDUNG
0 100 200 300 400 500 600 700 800 900 1000−20
−15
−10
−5
0
5
10
15
20
25
Zeit
Abf
luss
diffe
renz
m³/
s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
5
10
15
20
25
Zeit
Abf
luss
in m
³ / s
Konfidenzintervall Abfluss berechnet Abfluss gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.5: Ergebnisse Roda
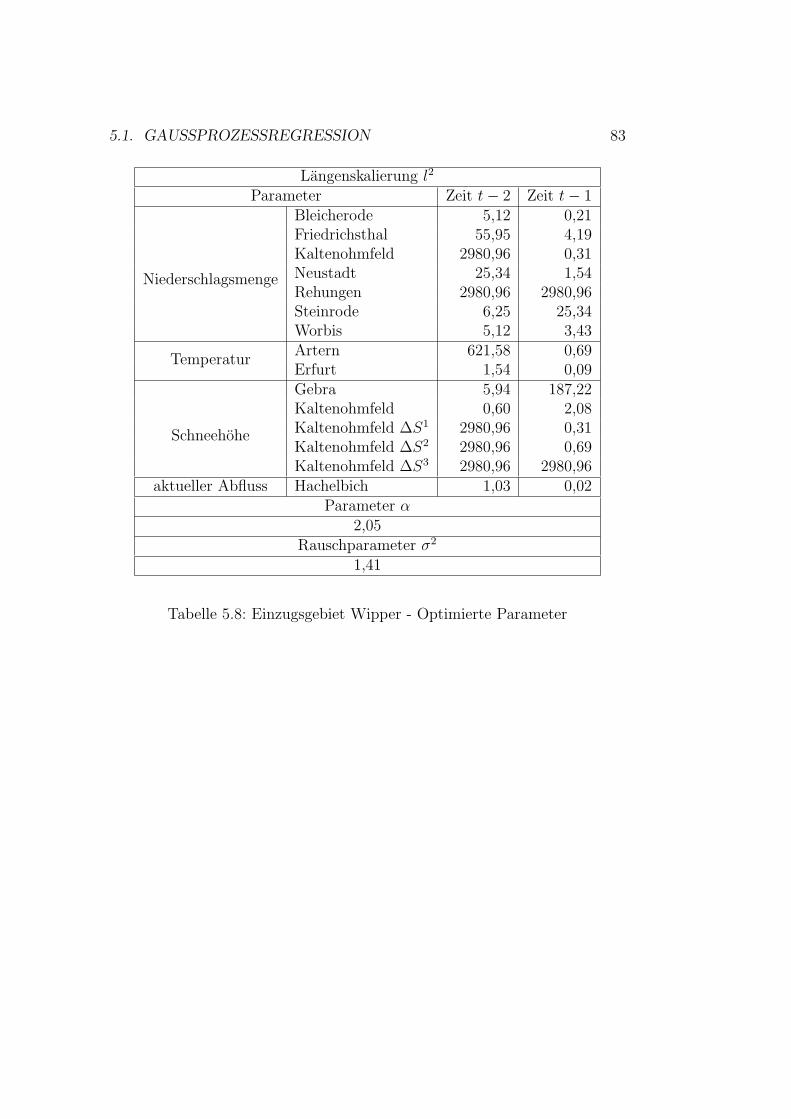
5.1. GAUSSPROZESSREGRESSION 83
Langenskalierung l2
Parameter Zeit t− 2 Zeit t− 1Bleicherode 5,12 0,21Friedrichsthal 55,95 4,19Kaltenohmfeld 2980,96 0,31Neustadt 25,34 1,54Rehungen 2980,96 2980,96Steinrode 6,25 25,34
Niederschlagsmenge
Worbis 5,12 3,43Artern 621,58 0,69
TemperaturErfurt 1,54 0,09Gebra 5,94 187,22Kaltenohmfeld 0,60 2,08Kaltenohmfeld ∆S1 2980,96 0,31Kaltenohmfeld ∆S2 2980,96 0,69
Schneehohe
Kaltenohmfeld ∆S3 2980,96 2980,96aktueller Abfluss Hachelbich 1,03 0,02
Parameter α2,05
Rauschparameter σ2
1,41
Tabelle 5.8: Einzugsgebiet Wipper - Optimierte Parameter
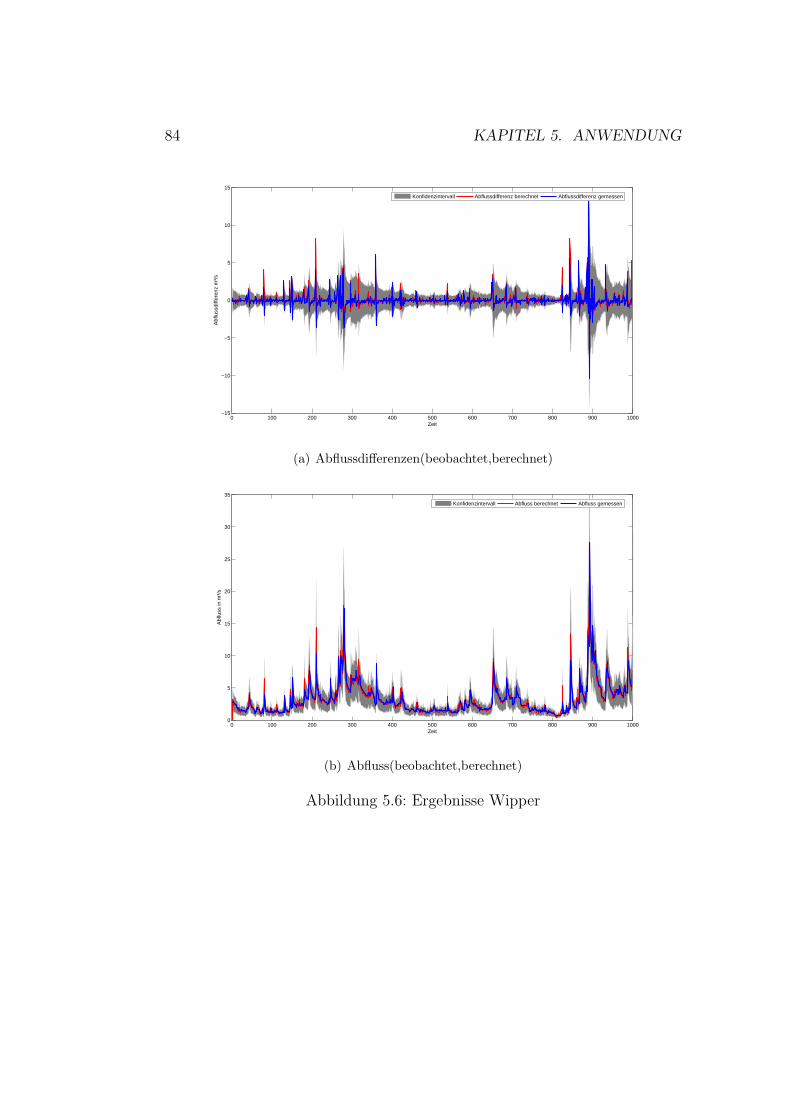
84 KAPITEL 5. ANWENDUNG
0 100 200 300 400 500 600 700 800 900 1000−15
−10
−5
0
5
10
15
Zeit
Abf
luss
diffe
renz
m³/
s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
5
10
15
20
25
30
35
Zeit
Abf
luss
in m
³/s
Konfidenzintervall Abfluss berechnet Abfluss gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.6: Ergebnisse Wipper

5.1. GAUSSPROZESSREGRESSION 85
5.1.4 Erweiterung des Vorhersagezeitraumes
Bisher wurden ausschließlich Vorhersagen uber genau einen Tag betrachtet(tpred = 1). Es sind jedoch Vorhersagen uber einen Zeitraum von einigen Ta-gen wunschenswert, so dass in diesem Abschnitt der Fall tpred > 1 untersuchtwird. Grundsatzlich wurde in Abschnitt ?? festgestellt, dass bereits aus-schließlich mit Daten des letzten Tages prazise Vorhersagen moglich sind. ImUmkehrschluß heißt dies, dass Ereignisse der jungsten Vergangenheit einenenormen Einfluss auf das Ergebnis haben. Mit anderen Worten: Es ist ziem-lich aussichtslos zu versuchen, Vorhersagen uber den Tag t+k zu treffen, ohneDaten uber den Tag t + k − 1 bereit zustellen. Dieses Problem wird umgan-gen, indem davon ausgegangen wird, dass zukunftige Klimadaten in gestorterForm als kurzfristige Wetterprognosen vorliegen. Leider waren fur die vor-liegende Arbeit keine realen Wetterprognosen uber einen ausreichend langenZeitraum verfugbar. Aus diesem Grunde wurde ein Stormodell eingefuhrt,welches die gemessenen Werte verfalscht und auf diese Art eine unsichereWetterprognose simuliert. Die Berechnungsvorschrift der gestorten Werte istmit Formel ?? gegeben.
x′ := x · (1 + U1 · r) + U2 · r wobei r ∼ U (−1, 1) und U1, U2 frei wahlbar.(5.1)
Die Storung besteht aus zwei Teilen. Der Teil U2·r sorgt fur eine Uberlagerungdes ursprunglichen Signals durch einfaches Rauschen, wahrend x ·(1 + U1 · r)einen relativen Fehler simuliert. Die Parameter U1 und U2 sind frei wahlbarund beschreiben die Starke der Storungen. Es wird hier stets U1 := U2 := Ugesetzt. Desweiteren ist r eine uber dem Intervall [−1, 1] gleichverteilte Zu-fallsvariable. Außerdem kann es vorkommen, dass nach dieser Berechnungs-vorschrift Werte entstehen, die in der Realitat nicht vorkommen konnen, wiezum Beispiel negative Niederschlage oder Schneehohen. Um dies zu verhin-dern, wird nach der Berechnung gepruft, ob der gestorte Wert zulassig ist. Istdies nicht der Fall, wird die Berechnung solange wiederholt, bis ein zulassigerWert berechnet wurde. Damit ist vollstandig beschrieben, wie gestorte Kli-madaten generiert werden.Neben diesen Klimadaten ist fur die Berechnung der Abflussmenge am Tagt + tpred die gemessene Abflussmenge am Tag t + tpred − 1 erforderlich. Furtpred = 1 liegt diese Messung tatsachlich vor. Ist tpred > 1, wird zunachst eineAbflussvorhersage fur tpred−1 durchgefuhrt und das Ergebnis als Schatzwertverwendet. Algorithmus ?? fasst das Vorgehen zusammen.
Da nicht anzunehmen ist, dass Wettervorhersagen als langjahrige Zeitreihenvorliegen, wird das Gaussprozessregressionsmodell mit ungestorten Daten fureine Vorhersage von einem Zeitschritt erstellt, wie in Abschnitt ?? dargestellt.

86 KAPITEL 5. ANWENDUNG
Algorithmus 5.1.2 : RunoffPrediction(PredictionModell G, Data D,Integer k, Storfaktor U)
if k = 1 then1
return G.Predict(D)2
else3
l := min {trel, k − 1}4
Qk−l := RunoffPrediction (G, D, k − l)5
Qk−l+1 := RunoffPrediction (G, D, k − l + 1)6
. . .7
Qk−1 := RunoffPrediction (G, D, k − 1)8
Dk := Merge (FalsifyData (D, U) , Rk−1, Rk−2, . . . , Rk−l)9
return G.Predict(Dk)10
end11
Storungen treten also erst in der Validierungsphase auf. Es ist zu erwarten,dass sich die Ergebnisse verbessern, wenn das Modell bereits mit gestortenDaten erstellt wird. Das heißt, sind ausreichend viele gestorte Datensatzevorhanden, so sollten diese fur die Modellerstellung eingesetzt werden. Aufdiesen Fall wird an dieser Stelle aber nicht weiter eingegangen. Statt dessenwird betrachtet, wie sich die Vorhersagegenauigkeit uber langere Zeitraumeverhalt. Abbildungen ?? - ?? zeigen die E2 - Werte der Berechnungen inAbhangigkeit von tpred und der Storgroße U . Prinzipiell ist zu sehen, dass dieGenauigkeit mit wachsendem Zeitraum tpred abnimmt. Allgemein lasst sichein starker Genauigkeitsverlust bei dem Ubergang von tpred = 1 auf tpred = 2feststellen. Bei einer weiteren Vergroßerung des Vorhersageintervalls fallt dieGenauigkeit zunachst langsamer. Nicht uberraschend ist, dass die Ungenauig-keiten mit steigendem Storfaktor U zunehmen. Es lasst sich beobachten, dassStorfaktoren bis 0, 5 wenig Einfluss haben, aber Storfaktoren ab 1, 0−2, 5 zustarken Verzerrungen fuhren. Die einzige Ausnahme ist das Modell des Ein-zugsgebietes der Roda. Der Storfaktor hat bei diesem kaum Auswirkungen.Insgesamt lasst sich feststellen, dass die Modelle fur langere Vorhersagen nurdann sinnvolle Ergebnisse liefern, wenn die prognostizierten Klimadaten ge-nauer sind, als die hier mit U = 0, 5 gestorten Daten. Der Vergleich dermit U = 0, 5 gestorten mit den originalen Zeitreihen hat ergeben, dass dieAhnlichkeit zwischen beiden Zeitreihen mit einem Korrelationskoeffizenten r2
von etwa 0, 9 - 0, 95 angegeben werden kann. Moderne Methoden zur quanti-tativen Vorhersage von Niederschlagsdaten erreichen selbst uber Vorhersage-zeitraume von einigen Stunden nur Genauigkeiten von r2 = 0, 3 (????). Diesist in etwa vergleichbar mit Storwerten von U ∈ [2, 5; 5, 0]. Somit werden
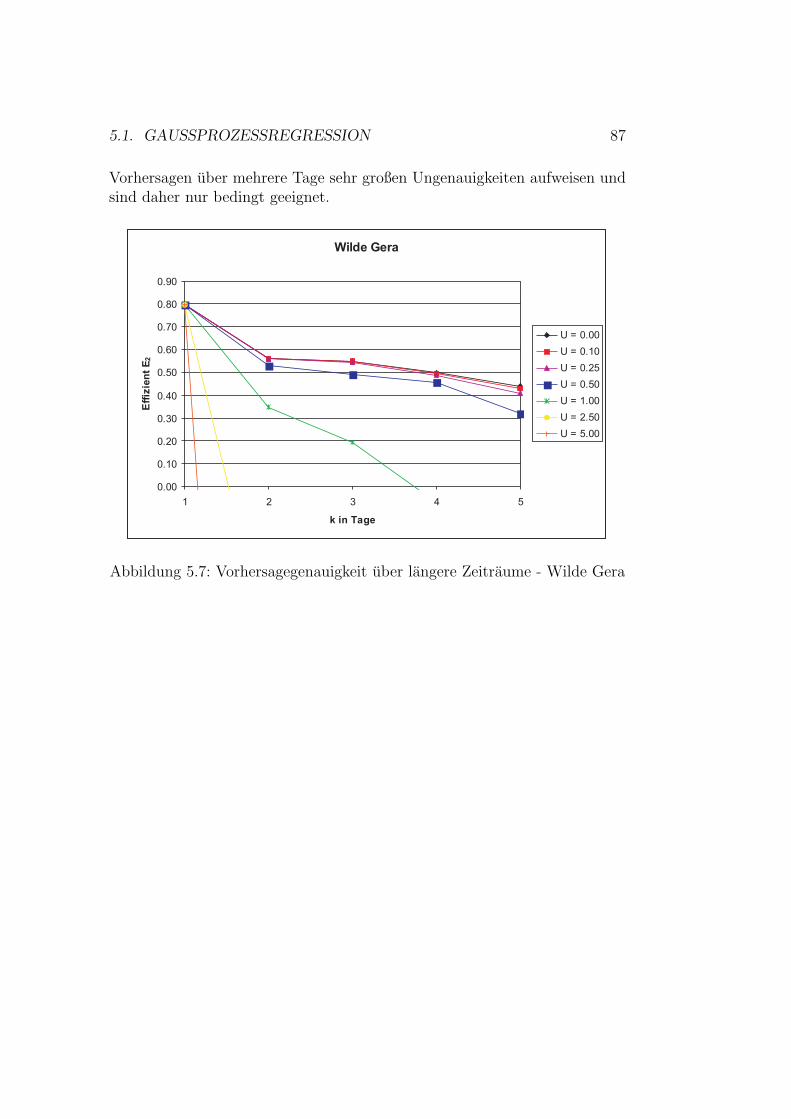
5.1. GAUSSPROZESSREGRESSION 87
Vorhersagen uber mehrere Tage sehr großen Ungenauigkeiten aufweisen undsind daher nur bedingt geeignet.
Wilde Gera
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1 2 3 4 5
k in Tage
Eff
izie
nt
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.7: Vorhersagegenauigkeit uber langere Zeitraume - Wilde Gera
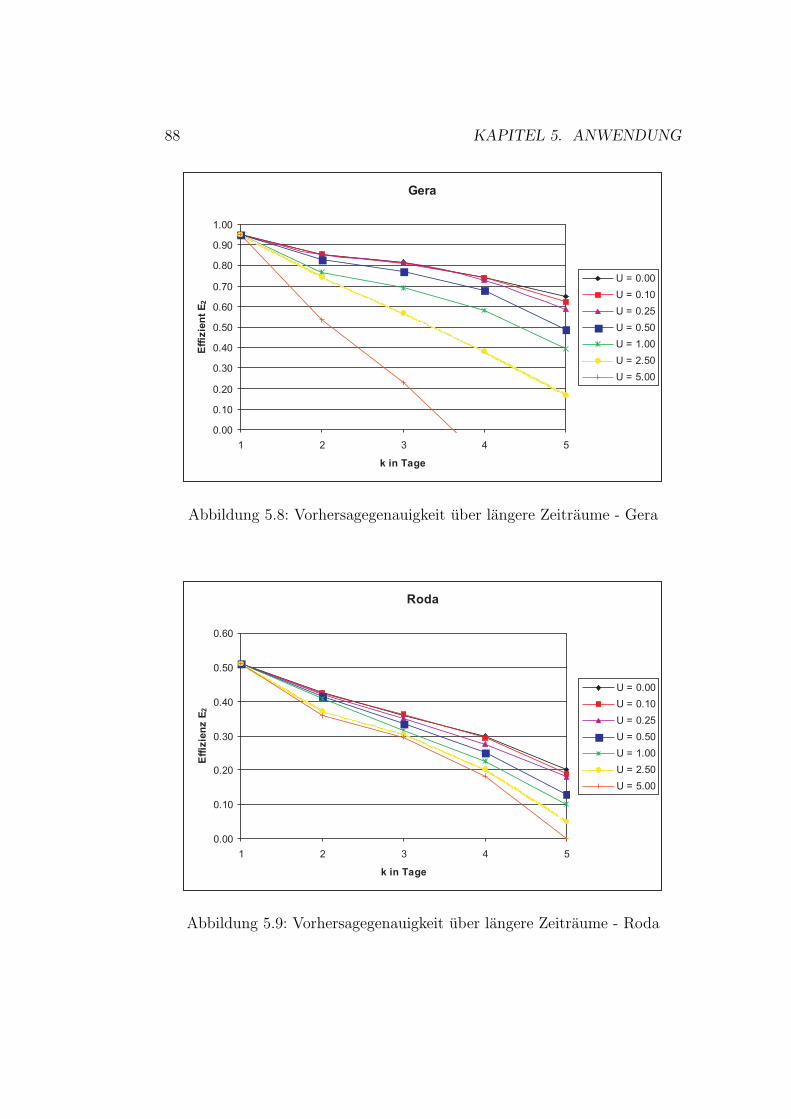
88 KAPITEL 5. ANWENDUNG
Gera
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 2 3 4 5
k in Tage
Eff
izie
nt
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.8: Vorhersagegenauigkeit uber langere Zeitraume - Gera
Roda
0.00
0.10
0.20
0.30
0.40
0.50
0.60
1 2 3 4 5
k in Tage
Eff
izie
nz
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.9: Vorhersagegenauigkeit uber langere Zeitraume - Roda
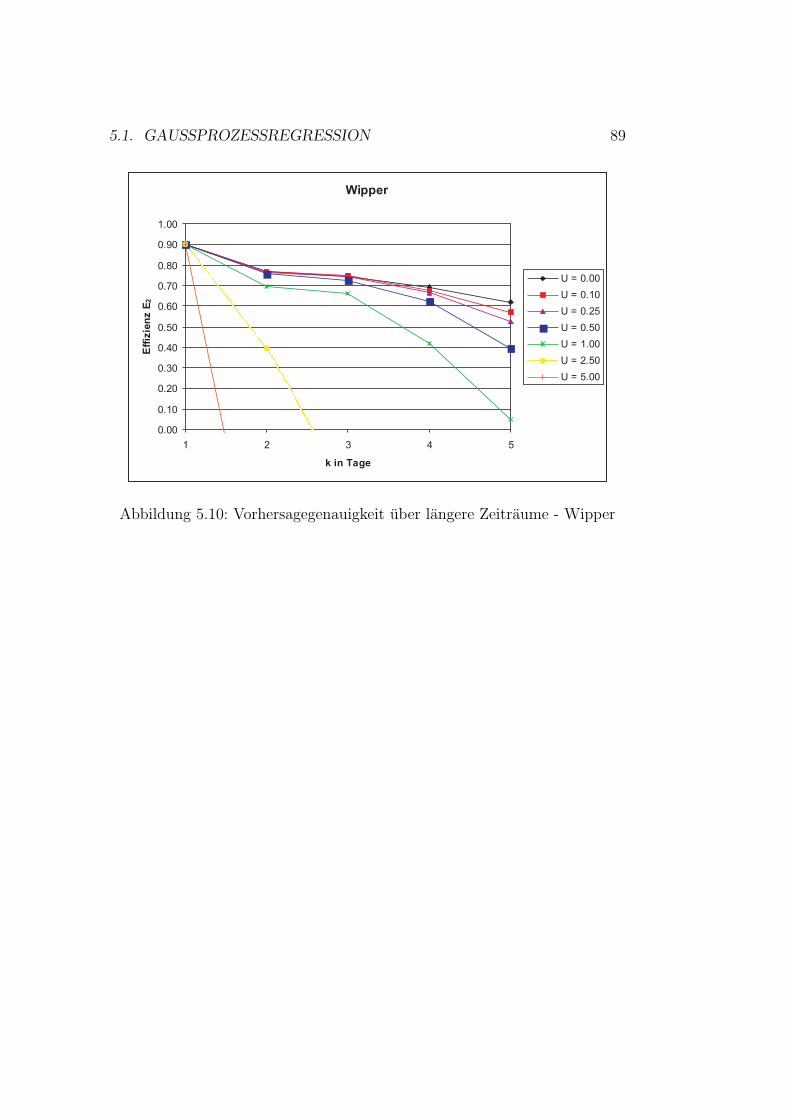
5.1. GAUSSPROZESSREGRESSION 89
Wipper
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 2 3 4 5
k in Tage
Eff
izie
nz
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.10: Vorhersagegenauigkeit uber langere Zeitraume - Wipper

90 KAPITEL 5. ANWENDUNG
5.2 Mehrschichtige Perzeptronennetze
5.2.1 Modellauswahl
Auch bei der Anwendung von Perzeptronennetzen mussen Modellparame-ter spezifiziert werden. Dabei handelt es sich um die Aktivierungsfunktion,das Lernverfahren, die Netztopologie und die Wahl des Relevanzzeitraumestrel. Im Folgenden wird beschrieben, wie die einzelnen Parameter spezifiziertwerden.
Aktivierungsfunktion Die Suche nach einer moglichst optimalen Akti-vierungsfunktion ist auf Grund der Suchraumgroße ein aufwandiges Unter-fangen. Motiviert durch gute Ergebnisse in anderen Arbeiten ((????) wirddie logistische Funktion mit Parameter γ = 1 gewahlt. Eine Darstellung desFunktionsverlaufes ist in Abbildung ?? zu sehen. ? gibt weitere Ausfuhrungenzu Aktivierungsfunktionen.
Lernverfahren In der vorliegenden Arbeit wird das Backpropagation -Lernverfahren mit Moment benutzt, welches in Abschnitt ?? beschriebenwurde. Neben dem Backpropagation - Lernverfahren existieren einige weite-re Lernverfahren, wie zum Beispiel die Methode des konjugierten Gradienten(??), Quickprob (??) und die Levenberg - Marquardt Methode (??). DieseLernverfahren sind jedoch wesentlich komplizierter, aufwandiger in der Be-rechnung oder es ist nicht klar, wie sie sich auf die Generalisierungsfahigkeitdes Netzes auswirken. Einige Ansatze zum Vergleich verschiedener Lernver-fahren werden von ? durchgefuhrt. Im Zuge der Auswahl des Lernverfahrensmussen auch dessen Parameter spezifiziert werden. Das einfache Backpropa-gation Lernverfahren mit Moment besitzt drei Parameter: Lernrate α, Mo-ment β und Anzahl der Lernepochen N . Die Anzahl der zu lernenden Epo-chen wird mit der Technik des
”Fruhen Stoppens“ bestimmt. Diese Methode
bestimmt die optimale Anzahl der Trainingsepochen, indem der Generalisie-rungsfehler mit Hilfe einer Kreuzvalidierung geschatzt wird, wie in Abschnitt?? beschrieben ist. Die anderen beiden Parameter werden, in Analogie zurBestimmung optimaler Parameter in Gaußprozessregressionsmodellen (Algo-rithmus ??), mit Hilfe eines Gradientenabstiegsverfahrens und der Methodeder Kreuzvalidierung bestimmt. Da es schwer ist einen geschlossenen Aus-druck fur den unbekannten Gradienten herzuleiten, wird dieser numerischermittelt.
Netztopologie Die Wahl der Netztopologie ist entscheidend dafur, ob dasPerzeptronennetz in der Lage ist, eine gute Reprasentation des Problems

5.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 91
zu erlernen. Netzstrukturen mit wenigen Knoten resultieren in einfachenschwach parametrisierbaren Modellen, wahrend große Strukturen komplexeModelle erzeugen, die oft mehrere hundert Parameter besitzen. Es ist wich-tig, die richtige Große des Netzes zu bestimmen, da ansonsten die Gefahr vonunder- beziehungsweise overfitting Effekten besteht (siehe auch Abschnitt ??). Um geeignete Topologien zu finden, werden viele Netze mit unterschiedli-cher Anzahl innerer Knoten und Schichten auf die Problemstellung angewen-det und anschließend entschieden, welche Topologie am gunstigsten ist. Essei nochmals vermerkt, dass die Validierungsdaten, die fur die Modellauswahlverwendet werden, disjunkt zu den Daten sind, die spater in der Phase derModellevaluation benutzt werden.
Wahl des relevanten Zeitraumes trel Bereits vor Anwendung der Gauß-prozessregression stellte sich die Frage, wie groß der Relevanzzeitraum seinsollte. Auf Grund des hohen Berechnungsaufwandes musste sich damit zufrie-den gegeben werden, lediglich zwei Schritte der Vergangenheit zu betrachten(trel = 2). Auf diese Einschrankung kann bei Verwendung von Perzeptronen-netzen verzichtet werden. Die Untersuchungen werden mit einem trel - Wertvon eins begonnen und so lange erhoht, bis sich die Modellergebnisse nichtweiter verbessern.
Ein Teil der Untersuchungsergebnisse ist in Abbildung ?? dargestellt. Fur allevier Einzugsgebiete wurde betrachtet, welche Modellgute Perzeptronennetzemit einer inneren Schicht erreichen, wenn zum einen die Anzahl der innerenKnoten variiert wird und zum anderen der Wert von trel verandert wird. InBezug auf die Anzahl der inneren Knoten lasst sich sagen, dass eine einzelneEinheit in der inneren Schicht zu wenig ist, um gute Ergebnisse zu liefern. Esreichen aber bereits drei Einheiten aus. Eine weitere Vergroßerung der inne-ren Schicht hat in keinem der untersuchten Einzugsgebiete zu wesentlichenVerbesserungen gefuhrt. Jedoch kam es, mit Ausnahme des Einzugsgebietesder Roda, zu keinen wesentlichen Verschlechterungen. Damit konnten zumin-dest in dieser Anwendung keine overfitting Effekte beobachtet werden. DieVerwendung großer Netze ist somit empfehlenswert.Der optimale Relevanzzeitraum trel ist stark einzugsgebietabhangig. Fur dieWilde Gera und die Gera wurde ein optimaler Wert von drei ermittelt, furdie Roda ein Wert von zwei und fur die Wipper ein Wert von vier. Fur dieEinzugsgebiete der Wilden Gera und Gera wird aber fast die gleiche Mo-dellgute mit einem Relevanzzeitraum von eins erzielt. Daten, die weiter inder Vergangenheit liegen, enthalten uber diese Einzugsgebiete nur wenige In-formationen, die durch das Netz verwertet werden konnen.Neben den dargestellten Untersuchungen werden außerdem Perzeptronennet-
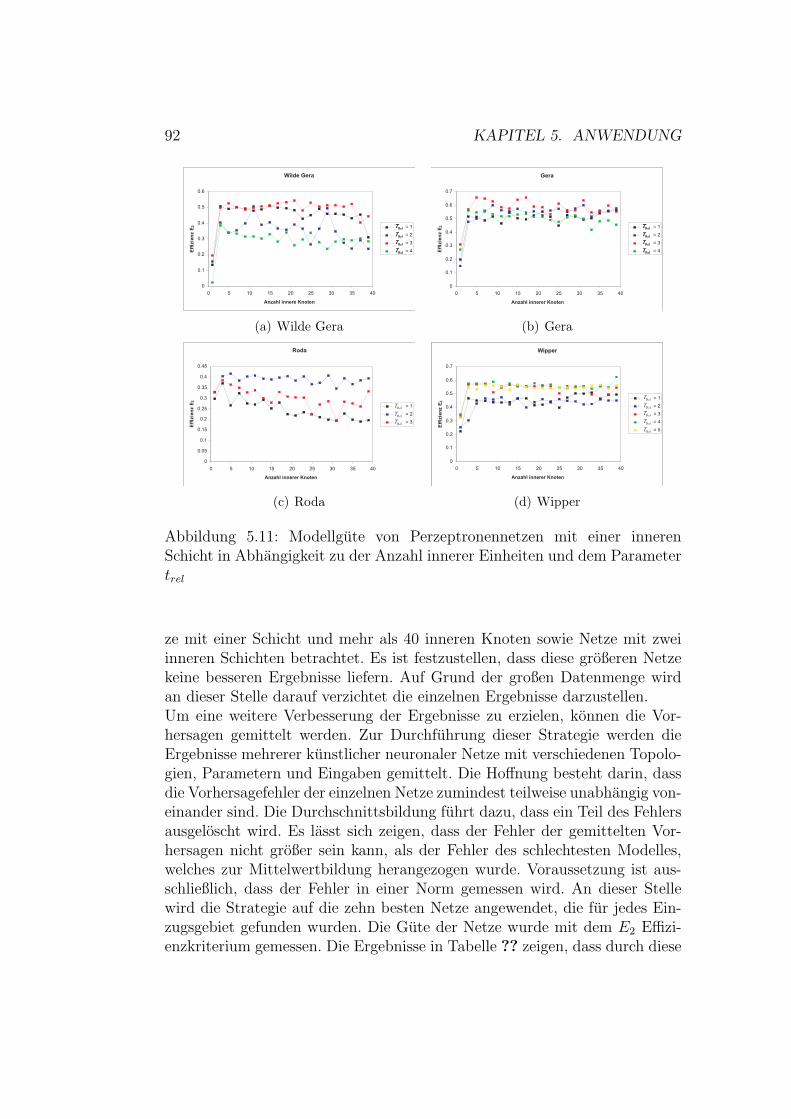
92 KAPITEL 5. ANWENDUNG
Wilde Gera
0
0.1
0.2
0.3
0.4
0.5
0.6
0 5 10 15 20 25 30 35 40
Anzahl innere Knoten
Eff
izie
nz
E2 TRel = 1
TRel = 2
TRel = 3
TRel = 4
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
(a) Wilde Gera
Gera
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 5 10 15 20 25 30 35 40
Anzahl innerer Knoten
Eff
izie
nz
E2 TRel = 1
TRel = 2
TRel = 3
TRel = 4
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
RelT
(b) Gera
Roda
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 5 10 15 20 25 30 35 40
Anzahl innerer Knoten
Eff
izie
nz
E2
TRel = 1
TRel = 2
TRel = 3
RelT
RelT
RelT
(c) Roda
Wipper
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 5 10 15 20 25 30 35 40
Anzahl innerer Knoten
Eff
izie
nz
E2
TRel = 1
TRel = 2
TRel = 3
TRel = 4
TRel = 5
RelT
RelT
RelT
RelT
RelT
Wipper
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 5 10 15 20 25 30 35 40
Anzahl innerer Knoten
Eff
izie
nz
E2
TRel = 1
TRel = 2
TRel = 3
TRel = 4
TRel = 5
RelT
RelT
RelT
RelT
RelT
(d) Wipper
Abbildung 5.11: Modellgute von Perzeptronennetzen mit einer innerenSchicht in Abhangigkeit zu der Anzahl innerer Einheiten und dem Parametertrel
ze mit einer Schicht und mehr als 40 inneren Knoten sowie Netze mit zweiinneren Schichten betrachtet. Es ist festzustellen, dass diese großeren Netzekeine besseren Ergebnisse liefern. Auf Grund der großen Datenmenge wirdan dieser Stelle darauf verzichtet die einzelnen Ergebnisse darzustellen.Um eine weitere Verbesserung der Ergebnisse zu erzielen, konnen die Vor-hersagen gemittelt werden. Zur Durchfuhrung dieser Strategie werden dieErgebnisse mehrerer kunstlicher neuronaler Netze mit verschiedenen Topolo-gien, Parametern und Eingaben gemittelt. Die Hoffnung besteht darin, dassdie Vorhersagefehler der einzelnen Netze zumindest teilweise unabhangig von-einander sind. Die Durchschnittsbildung fuhrt dazu, dass ein Teil des Fehlersausgeloscht wird. Es lasst sich zeigen, dass der Fehler der gemittelten Vor-hersagen nicht großer sein kann, als der Fehler des schlechtesten Modelles,welches zur Mittelwertbildung herangezogen wurde. Voraussetzung ist aus-schließlich, dass der Fehler in einer Norm gemessen wird. An dieser Stellewird die Strategie auf die zehn besten Netze angewendet, die fur jedes Ein-zugsgebiet gefunden wurden. Die Gute der Netze wurde mit dem E2 Effizi-enzkriterium gemessen. Die Ergebnisse in Tabelle ?? zeigen, dass durch diese
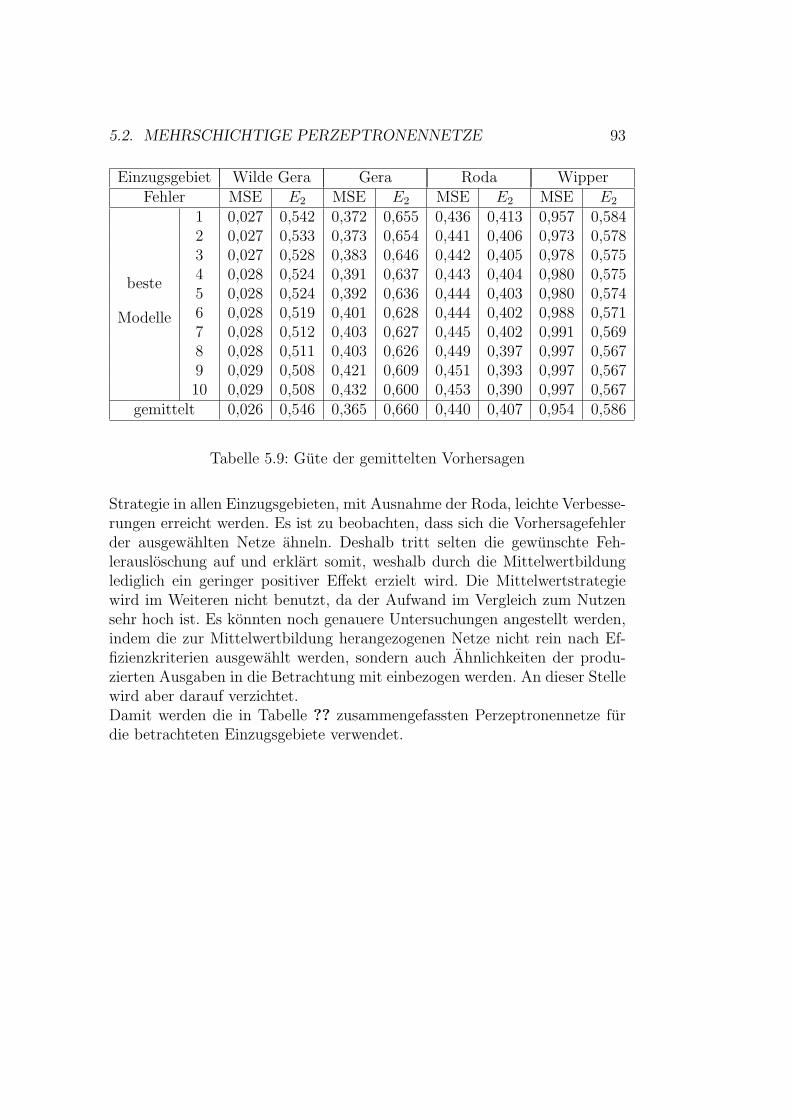
5.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 93
Einzugsgebiet Wilde Gera Gera Roda WipperFehler MSE E2 MSE E2 MSE E2 MSE E2
1 0,027 0,542 0,372 0,655 0,436 0,413 0,957 0,5842 0,027 0,533 0,373 0,654 0,441 0,406 0,973 0,5783 0,027 0,528 0,383 0,646 0,442 0,405 0,978 0,5754 0,028 0,524 0,391 0,637 0,443 0,404 0,980 0,575
beste5 0,028 0,524 0,392 0,636 0,444 0,403 0,980 0,5746 0,028 0,519 0,401 0,628 0,444 0,402 0,988 0,5717 0,028 0,512 0,403 0,627 0,445 0,402 0,991 0,5698 0,028 0,511 0,403 0,626 0,449 0,397 0,997 0,5679 0,029 0,508 0,421 0,609 0,451 0,393 0,997 0,567
Modelle
10 0,029 0,508 0,432 0,600 0,453 0,390 0,997 0,567gemittelt 0,026 0,546 0,365 0,660 0,440 0,407 0,954 0,586
Tabelle 5.9: Gute der gemittelten Vorhersagen
Strategie in allen Einzugsgebieten, mit Ausnahme der Roda, leichte Verbesse-rungen erreicht werden. Es ist zu beobachten, dass sich die Vorhersagefehlerder ausgewahlten Netze ahneln. Deshalb tritt selten die gewunschte Feh-lerausloschung auf und erklart somit, weshalb durch die Mittelwertbildunglediglich ein geringer positiver Effekt erzielt wird. Die Mittelwertstrategiewird im Weiteren nicht benutzt, da der Aufwand im Vergleich zum Nutzensehr hoch ist. Es konnten noch genauere Untersuchungen angestellt werden,indem die zur Mittelwertbildung herangezogenen Netze nicht rein nach Ef-fizienzkriterien ausgewahlt werden, sondern auch Ahnlichkeiten der produ-zierten Ausgaben in die Betrachtung mit einbezogen werden. An dieser Stellewird aber darauf verzichtet.Damit werden die in Tabelle ?? zusammengefassten Perzeptronennetze furdie betrachteten Einzugsgebiete verwendet.
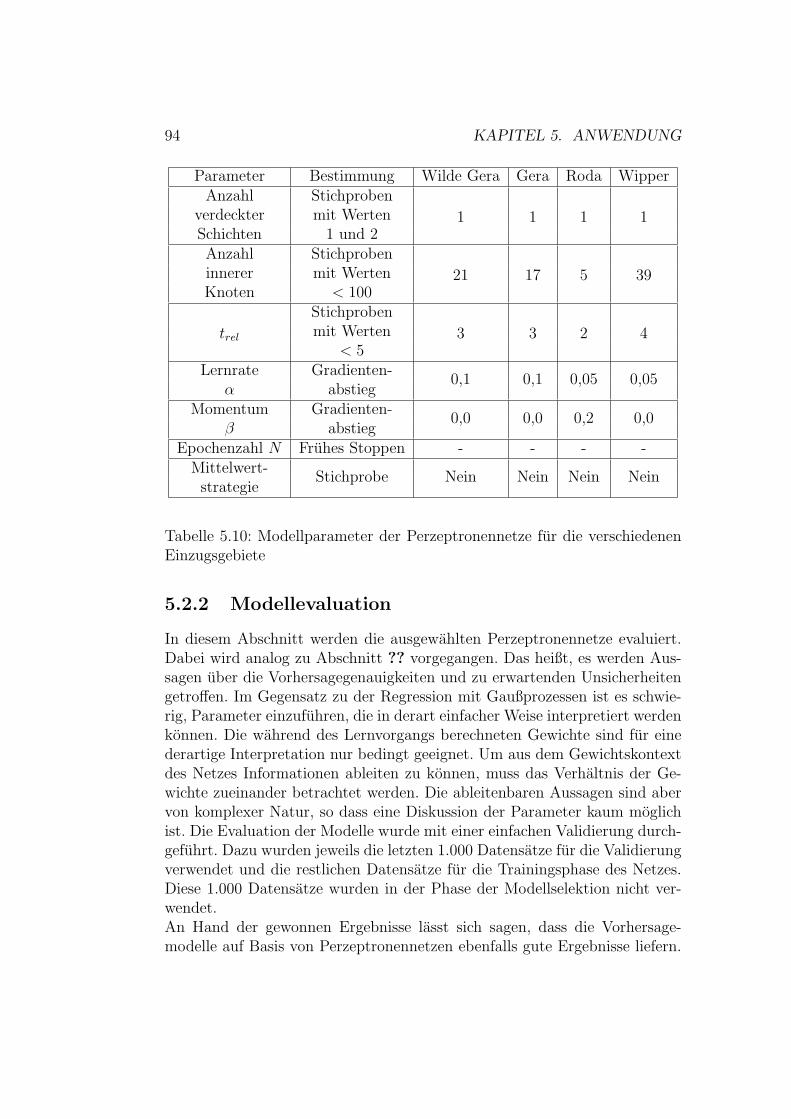
94 KAPITEL 5. ANWENDUNG
Parameter Bestimmung Wilde Gera Gera Roda WipperAnzahl Stichproben
verdeckter mit WertenSchichten 1 und 2
1 1 1 1
Anzahl Stichprobeninnerer mit WertenKnoten < 100
21 17 5 39
Stichprobenmit Wertentrel
< 53 3 2 4
Lernrate Gradienten-α abstieg
0,1 0,1 0,05 0,05
Momentum Gradienten-β abstieg
0,0 0,0 0,2 0,0
Epochenzahl N Fruhes Stoppen - - - -Mittelwert-strategie
Stichprobe Nein Nein Nein Nein
Tabelle 5.10: Modellparameter der Perzeptronennetze fur die verschiedenenEinzugsgebiete
5.2.2 Modellevaluation
In diesem Abschnitt werden die ausgewahlten Perzeptronennetze evaluiert.Dabei wird analog zu Abschnitt ?? vorgegangen. Das heißt, es werden Aus-sagen uber die Vorhersagegenauigkeiten und zu erwartenden Unsicherheitengetroffen. Im Gegensatz zu der Regression mit Gaußprozessen ist es schwie-rig, Parameter einzufuhren, die in derart einfacher Weise interpretiert werdenkonnen. Die wahrend des Lernvorgangs berechneten Gewichte sind fur einederartige Interpretation nur bedingt geeignet. Um aus dem Gewichtskontextdes Netzes Informationen ableiten zu konnen, muss das Verhaltnis der Ge-wichte zueinander betrachtet werden. Die ableitenbaren Aussagen sind abervon komplexer Natur, so dass eine Diskussion der Parameter kaum moglichist. Die Evaluation der Modelle wurde mit einer einfachen Validierung durch-gefuhrt. Dazu wurden jeweils die letzten 1.000 Datensatze fur die Validierungverwendet und die restlichen Datensatze fur die Trainingsphase des Netzes.Diese 1.000 Datensatze wurden in der Phase der Modellselektion nicht ver-wendet.An Hand der gewonnen Ergebnisse lasst sich sagen, dass die Vorhersage-modelle auf Basis von Perzeptronennetzen ebenfalls gute Ergebnisse liefern.

5.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 95
E2 absolut E2 relativ MSEWilde Gera 0,89 0,60 0,02
Gera 0,94 0,56 0,28Roda 0,53 0,59 0,26
Wipper 0,93 0,46 0,61
Tabelle 5.11: Vorhersagegenauigkeit
Belegt wird dies zum einen durch die Abflussdiagramme in den Abbildun-gen 5.12 - 5.15 und zum anderen durch die berechnten Effizienzen. Die E2
Werte und der mittlere quadratische Fehler der absoluten und relativen Ab-flusse sind in Tabelle 5.10 zusammengefasst. Die absoluten Effizienzen (alsodas Ubereinstimmungsmaß von Qt+1 und ft+1), liegen großtenteils im Be-reich um 0,9, die relativen Effizenzen (also das Ubereinstimmungsmaß vonQt+1 − Qt und ft+1 − Qt) im Bereich von 0,46 bis 0,6. Großere Fehler gibtes wieder in den Abflussberechnungen der Roda. Die Nash - Sutcliffe Effizi-enz berechnet sich zu 0, 53. Damit bleiben alle Modelle hinter der wahrendder Modellselektionsphase erzielten Genauigkeit zuruck. Uber die Ursache furdieses Verhalten lasst sich nur spekulieren. Denkbar ist, dass die Verwendungeiner großeren Trainingsmenge dazu fuhrt, dass die ausgewahlte Netztopo-logie oder andere Verfahrensparameter nicht mehr geeignet sind. Moglichist auch, dass die zusatzlichen Trainingsdaten zufallig zu einem schlechterenVerhalten fuhren oder die Validierungsdaten besondere Probleme bereiten.Dagegen spricht, dass die Evaluation der Gaußprozessmodelle ein genau ge-genteiliges Verhalten gezeigt hat, das heißt die Ergebnisse wurden bei der Mo-dellevalution nochmals deutlich besser. Im weiteren Vergleich sind, die vonden Perzeptronennetzen berechneten Abflusswerte, etwas schlechter als diemit der Gaußprozessregression berechneten Ergebnisse. Die Unterschiede inden Gutekriterien sind aber meistens sehr klein. Lediglich die Ergebnisse imEinzugsgebiet der Wipper bleiben hinter den vergleichbaren Resultaten derGaußprozessregression zuruck. Werden die einzelnen berechneten Vorhersa-gen der Gaußprozessmodelle mit denen der Perzeptronennetze verglichen, soist erkennbar, dass die meisten und vor allem die großten Fehler in exakt den-selben Situationen auftreten. Also vor allem bei Schneeschmelz- und extre-men Niederschlagsereignissen. Im Einzugsgebiet der Roda fallt auf, dass dieberechneten Abflusse systematisch zu niedrig sind. Zusammenfassend kannfestgestellt werden, dass kunstliche neuronale Netze in den Untersuchungengute Ergebnisse liefern, aber bezuglich der Genauigkeit und Interpretierbar-keit der Aussagen, sich etwas schlecher verhalten als die Gaußprozessregres-sion.
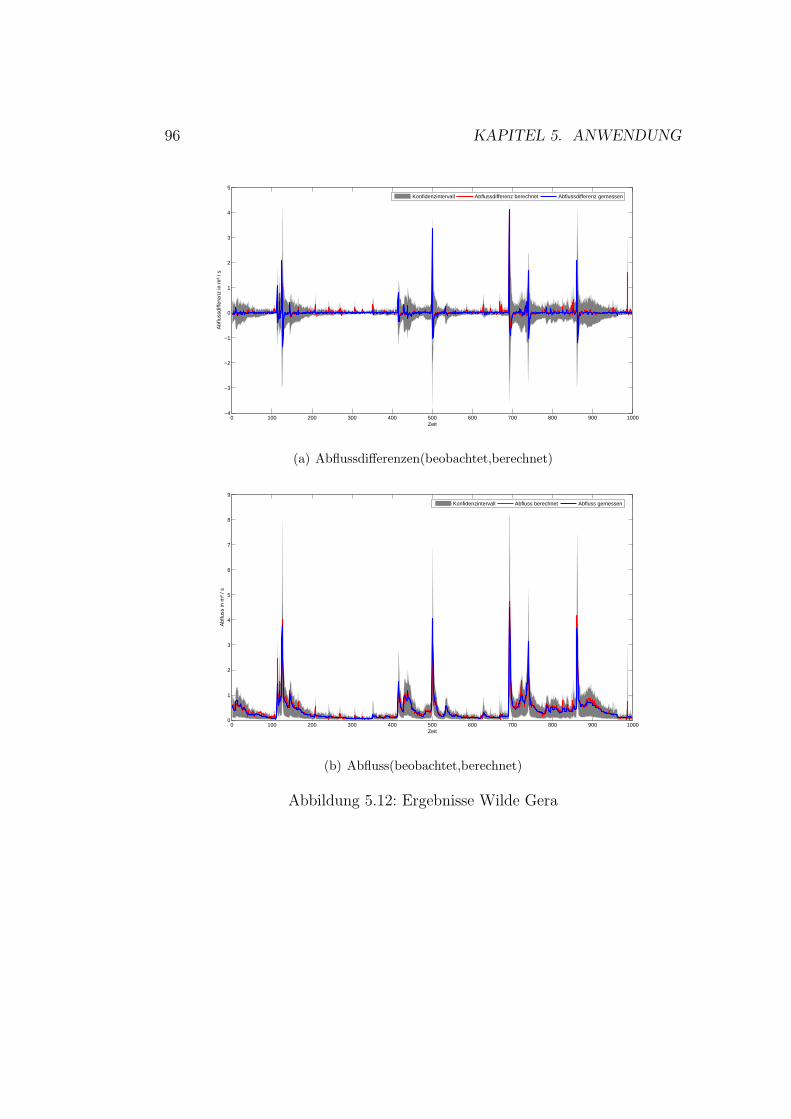
96 KAPITEL 5. ANWENDUNG
0 100 200 300 400 500 600 700 800 900 1000−4
−3
−2
−1
0
1
2
3
4
5
Zeit
Abf
luss
diffe
renz
in m
³ / s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
1
2
3
4
5
6
7
8
9
Zeit
Abf
luss
in m
³ / s
Konfidenzintervall Abfluss berechnet Abfluss gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.12: Ergebnisse Wilde Gera
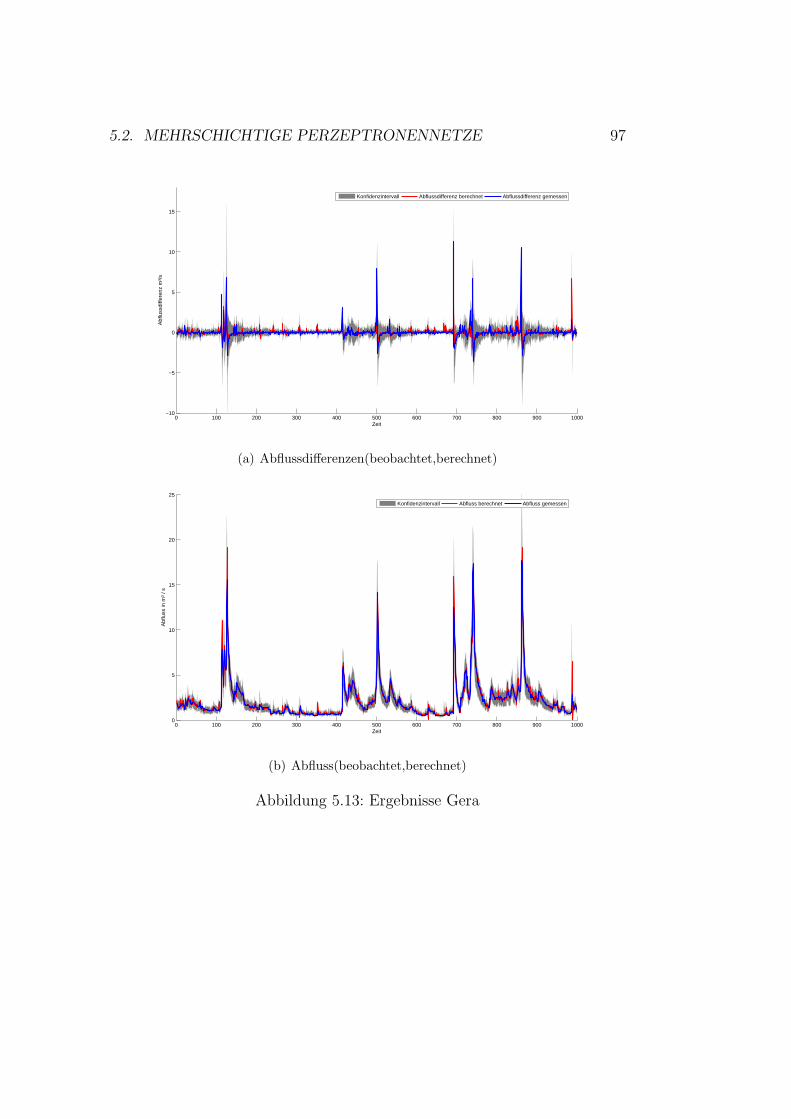
5.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 97
0 100 200 300 400 500 600 700 800 900 1000−10
−5
0
5
10
15
Zeit
Abf
luss
diffe
renz
m³/
s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
5
10
15
20
25
Zeit
Abf
luss
in m
³ / s
Konfidenzintervall Abfluss berechnet Abfluss gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.13: Ergebnisse Gera
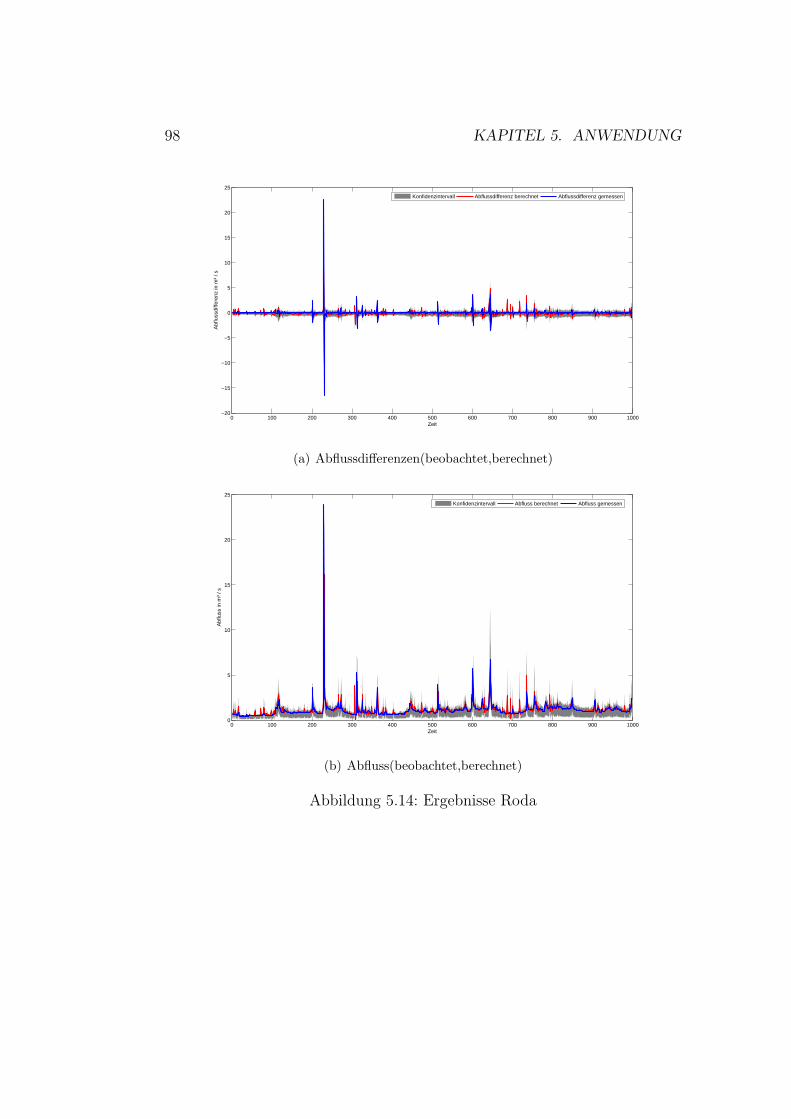
98 KAPITEL 5. ANWENDUNG
0 100 200 300 400 500 600 700 800 900 1000−20
−15
−10
−5
0
5
10
15
20
25
Zeit
Abf
luss
diffe
renz
in m
³ / s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
5
10
15
20
25
Zeit
Abf
luss
in m
³ / s
Konfidenzintervall Abfluss berechnet Abfluss gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.14: Ergebnisse Roda
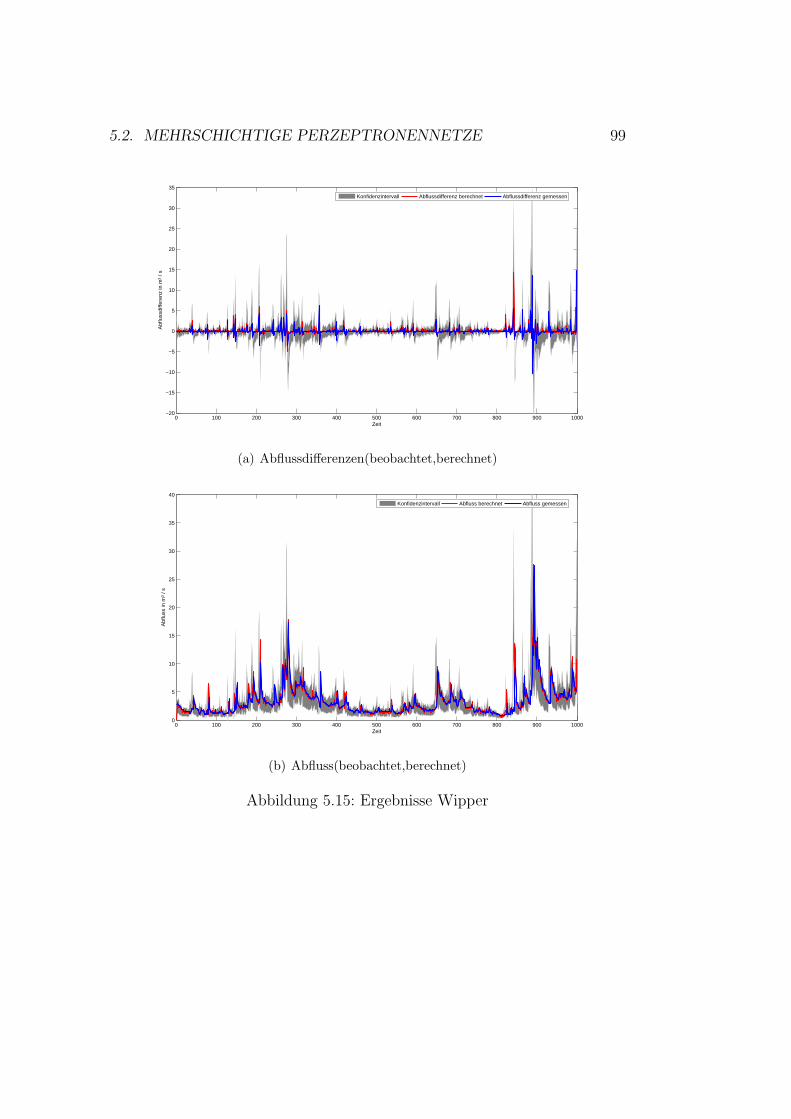
5.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 99
0 100 200 300 400 500 600 700 800 900 1000−20
−15
−10
−5
0
5
10
15
20
25
30
35
Zeit
Abf
luss
diffe
renz
in m
³ / s
Konfidenzintervall Abflussdifferenz berechnet Abflussdifferenz gemessen
(a) Abflussdifferenzen(beobachtet,berechnet)
0 100 200 300 400 500 600 700 800 900 10000
5
10
15
20
25
30
35
40
Zeit
Abf
luss
in m
³ / s
Konfidenzintervall Abfluss berechnet Abfluss gemessen
(b) Abfluss(beobachtet,berechnet)
Abbildung 5.15: Ergebnisse Wipper

100 KAPITEL 5. ANWENDUNG
5.2.3 Erweiterung des Vorhersagezeitraumes
In diesem Abschnitt wird untersucht, welche Genauigkeit Perzeptronennetzebei Vorhersagen uber mehrere Zeitschritte erreichen. Das Vorgehen gestaltetsich vollkommen analog zu dem in Abschnitt ?? beschriebenen. Zusammen-gefasst heißt das, dass zukunftige Klimadaten in gestorter Form vorliegen.Als Stormodell wird Gleichung ?? verwendet. Die Vorhersage der Abflusseerfolgt schrittweise. Es wird zunachst der Abflusses zum Zeitpunkt t + 1 be-rechnet. Mit diesem erfolgt die Berechnung des Abfluss am Tag t + 2 und soweiter. Das Verfahren lasst sich aus Algorithmus ?? ubernehmen.Die Abbildungen ?? - ?? zeigen die Ergebnisse der Untersuchungen. DieKurvenverlaufe ahneln den Ergebnissen, durch die Gaußprozessregressiongewonnen wurden. Die Gute der Ergebnisse wird mit einer Vergroßerungder Storungen und des Vorhersagezeitraum stets kleiner. Bei Anwendungder Gaußprozessregression wurde bemerkt, dass gerade der Ubergang vontpred = 1 auf tpred = 2 eine starke Verschlechterung zur Folge hat. Dies kannhier nicht beobachtet werden. So lange der Storfaktor einen Wert von 0, 5nicht uberschreitet, lasst sich feststellen, dass die zweitagigen Vorhersagenfast genauso gut sind wie die eintagigen Vorhersagen. Außerdem lasst sichwieder feststellen, dass auch mehrtagige Vorhersagen, die mit einem kleinerenStorfaktor als 0, 5 gestort wurden, eine brauchbare Genauigkeit aufweisen.Allerdings nimmt bei langeren Vorhersagen die Genauigkeit ahnlich starkab, wie es schon in der Anwendung der Gaußprozesse beobachtet wurde.Auf Grund der Tatsache, dass quantitative Niederschlagsvorhersagen nachaktuellem Stand der Technik sehr ungenau sind, muss festgestellt werden,dass Vorhersagen uber mehrere Tage sehr große Unsicherheiten aufweisen.Vorhersagen uber mehrere Tage sind daher kaum durchfuhrbar. Es lasst sichbeobachten, dass das Modell fur das Einzugsgebiet der Roda besonders un-empfindlich auf Storungen reagiert. Dies ist ein Hinweis darauf, dass dasModell nicht sensitiv auf Klimadaten ist und lediglich den Abflusswertengroßere Bedeutung zukommen lasst. Damit erklaren sich auch die schlechtenErgebnisse des Modelles fur das Einzugsgebiet der Roda.
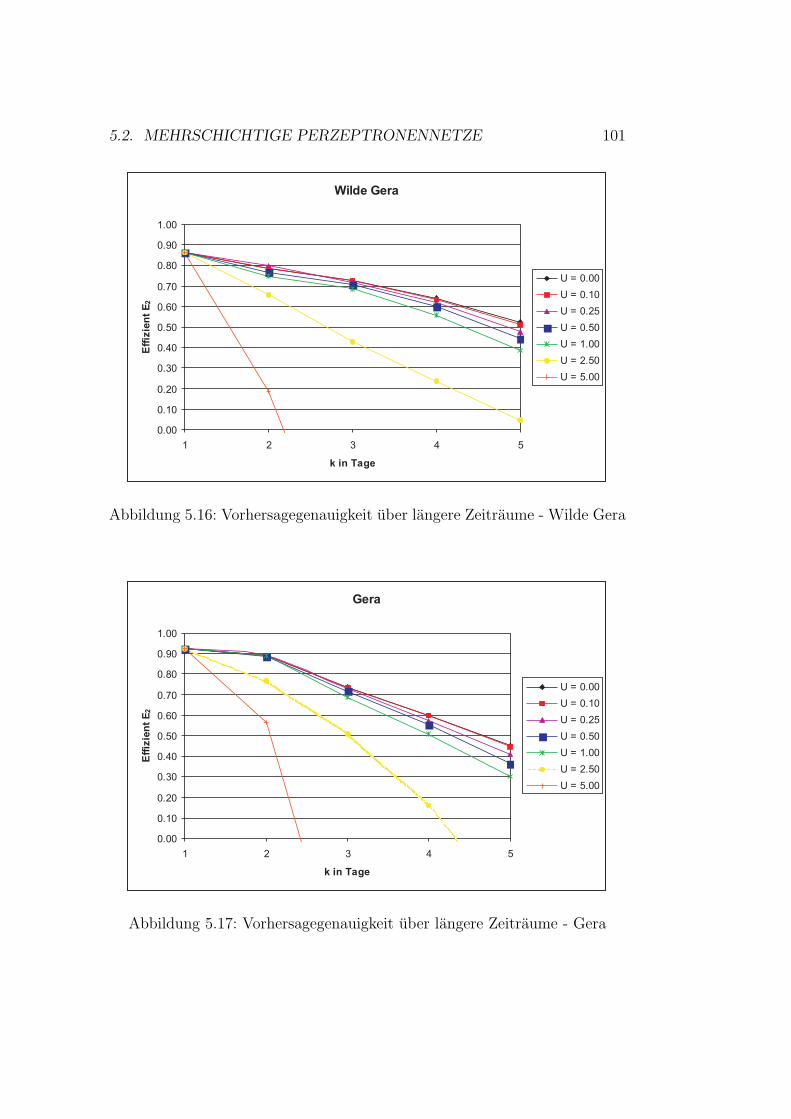
5.2. MEHRSCHICHTIGE PERZEPTRONENNETZE 101
Wilde Gera
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 2 3 4 5
k in Tage
Eff
izie
nt
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.16: Vorhersagegenauigkeit uber langere Zeitraume - Wilde Gera
Gera
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 2 3 4 5
k in Tage
Eff
izie
nt
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.17: Vorhersagegenauigkeit uber langere Zeitraume - Gera
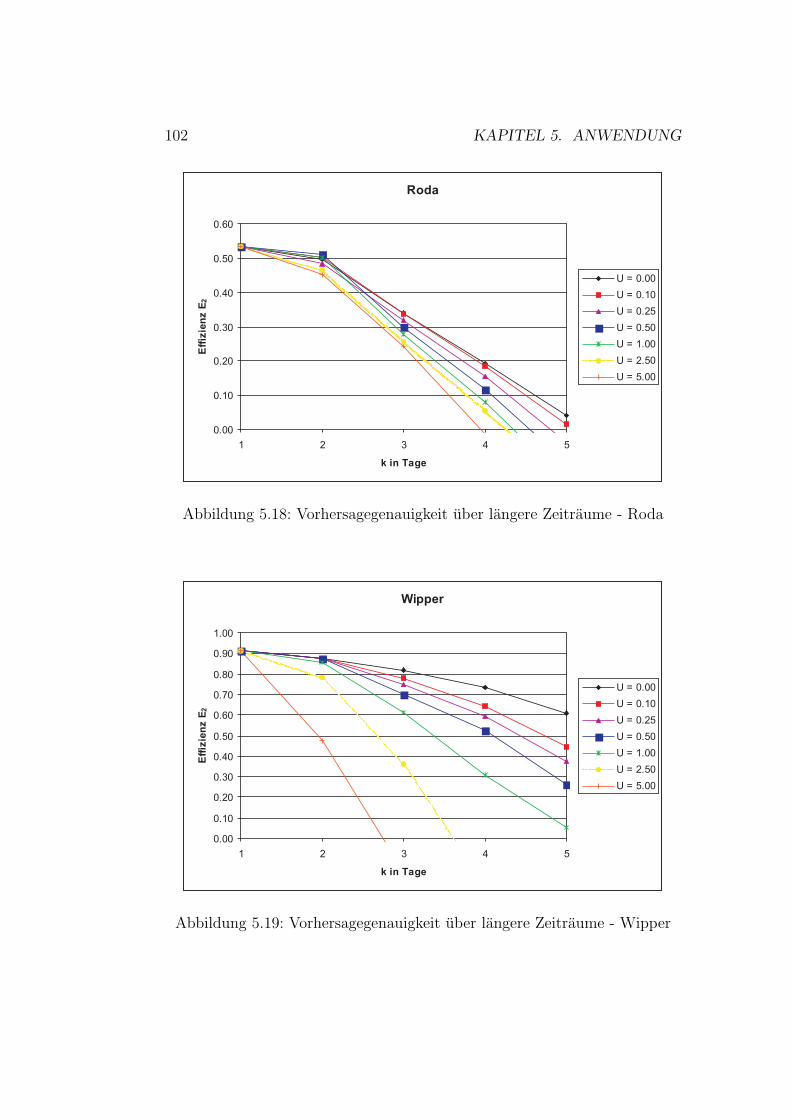
102 KAPITEL 5. ANWENDUNG
Roda
0.00
0.10
0.20
0.30
0.40
0.50
0.60
1 2 3 4 5
k in Tage
Eff
izie
nz
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.18: Vorhersagegenauigkeit uber langere Zeitraume - Roda
Wipper
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 2 3 4 5
k in Tage
Eff
izie
nz
E2
U = 0.00
U = 0.10
U = 0.25
U = 0.50
U = 1.00
U = 2.50
U = 5.00
Abbildung 5.19: Vorhersagegenauigkeit uber langere Zeitraume - Wipper

Kapitel 6
Zusammenfassung und Ausblick
Inhalt der vorliegende Arbeit ist die hydrologischen Abflussmodellierung mitHilfe statistischer Methoden. Motiviert wird dieses Thema durch den Bedarfan kurzfristigen Hochwasservorhersagen, die es erlauben fruhzeitig Maßnah-men zur Verhinderung beziehungsweise Eindammung von Hochwasserkata-strophen zu ergreifen. Hydrologische Modelle fur diese Anwendung mussenin der Lage sein, prazise kurzfristige Vorhersagen zu liefern und sollen außer-dem mit minimalen Aufwand fur eine Vielzahl von Einzugsgebieten einsetz-bar sein. Um ein Verstandnis fur diese Problematik zu entwickeln, werdenzunachst grundlegende hydrologische Zusammenhange dargestellt und prin-zipielle Moglichkeiten der hydrologischen Modellierung aufgezeigt. Dabei istfestzustellen, dass statistische Modelle den aufgezahlten Anforderungen ge-recht werden konnen. Unter Berucksichtigung der Eigenschaften statistischerVerfahren wird eine formale Beschreibung der Problemstellung gegeben undes erfolgt die Auswahl der abflussrelevanten Großen eines Einzugsgebietes. ImEinzelnen werden Niederschlag-, Temperatur-, Schnee-, Verdunstungs- undgegenwartige Abflussdaten ausgewahlt. Zum Abschluß des ersten Kapitelswerden einige Fragestellungen bezuglich der raumlichen und zeitlichen Aus-wahl der Daten betrachtet und die Vorverarbeitung der Daten erlautert.Inhalt des zweiten Kapitels ist die Vorstellung der verwendeten Methoden.Zuerst werden zwei ausgewahlte statistische Verfahren beschrieben, die aufdie Problemstellung angewendet werden. Als erstes werden mehrschichtigePerzeptronennetze (MLP) benutzt. Diese speziellen kunstlichen neuronalenNetze werden bereits seit Mitte der neunziger Jahre erfolgreich fur die hy-drologische Modellierung eingesetzt. Demgegenuber haben moderne Metho-den vor allem aus der Klasse der
”Kernel machines“ bisher wenig Beach-
tung gefunden. Besonders die Gaußprozessregression erscheint aber vielver-sprechend, da diese bereits mit großem Erfolg fur die Modellierung anderernaturlicher Prozesse eingesetzt wurde. Es ist daher von Interesse die Gauß-
103

104 KAPITEL 6. ZUSAMMENFASSUNG UND AUSBLICK
prozessregression auf die Problemstellung anzuwenden und einen Vergleichmit mehrschichtigen Perzeptronennetzen vorzunehmen. Die Gaußprozesse-regression beruht auf der Annahme, dass Beobachtungen einem normalver-teilten stochastischen Prozess folgen. Allein dadurch kann gezeigt werden,dass neue Beobachtungen die Wahrscheinlichkeitsverteilung der alten Beob-achtungen nicht andert. Diese einfache Feststellung ermoglicht es, Aussagenuber unbekannte Werte zu treffen. Durch die Auswahl der Kovarianzfunktiondes Gaußprozesses konnen a priori Annahmen in die Regression eingebrachtwerden. In diesem Zusammenhang ist es moglich, die Parameter der Kovari-anzfunktion automatisch zu bestimmen und auf diese Weise eine Gewichtungin der Relevanz der Eingabegroßen zu erhalten. Dies erlaubt es beispielsweisenicht relevante und somit uberflussige Eingabekomponenten zu erkennen undzu eleminieren.Mehrschichtige Perzeptronennetze basieren auf einer vollkommen anderenGrundlage. Ein mehrschichtiges Perzeptronennetz arbeitet der Art, dass esEingaben entgegen nimmt, diese durch ein Netz aus Verarbeitungseinhei-ten propagiert und dadurch eine Ausgabe erzeugt. Die Verarbeitungseinhei-ten sind untereinander durch gewichtete Verbindungen vernetzt. Durch dieWahl der Gewichte lasst sich die Transferfunktion zwischen Ein- und Ausga-be festlegen. Lernverfahren ermoglichen eine automatische Bestimmung derGewichte. In der vorliegenden Arbeit wird das Backpropagation Verfahrenverwendet, welches in Abschnitt ?? beschrieben wird. Bei Anwendung desVerfahrens konnen allerdings einige Probleme auftreten, auf die in Abschnitt?? eingegangen wird.Zum Vergleich der beiden Verfahren lasst sich an dieser Stelle sagen, dass bei-de Verfahren fur die hochdimensionalen Regression eingesetzt werden konnen.Gaußprozesse zeichnen sich durch ihr solides theoretisches Grundgerust aus,sind aber in Bezug auf Berechnungsaufwand und Speicherplatzbedarf proble-matisch. Dominierend im Aufwand ist die Losung eines linearen Gleichungs-systems, welches sich in kubischer Zeitkomplexitat und quadratischer Spei-cherplatzkomplexitat in der Anzahl der Trainingsdaten niederschlagt. DasBackpropagation Verfahren hat zwar ebenfalls einen hohen Rechenzeitbe-darf, ist aber im Speicherbedarf viel genugsamer. Leider ist es nicht direktmoglich aus den Ergebnissen des Backpropagation Verfahrens Informationenuber die Relevanz der Eingabedaten abzuleiten. Nach der Beschreibung derbeiden Verfahren wird sich damit befasst, wie die vorhandenen Daten effizi-ent eingesetzt werden konnen, um mit einer moglichst großen Trainingsmen-ge die Erstellung der Gaußprozessmodelle und der mehrschichtigen Perzep-tronennetze vornehmen zu konnen und trotzdem noch genugend Daten zurVerfugung zu haben um eine aussagekraftige Modellevaluation durchfuhrenzu konnen. Dazu wird in Abschnitt ?? die Methode der Kreuzvalidierung

105
beschrieben und verschiedene Fehlermaße vorgestellt. Verwendung finden dieFehlermaße des mittleren quadratischen Fehlers (MSE) und die Nash - Sut-cliffe Effizienz (E2). Nach diesen ausfuhrlichen Vorbetrachtungen erfolgt dieAnwendung der beiden Verfahren. Da es nicht moglich erscheint hinreichendprazise allgemeine Aussagen zu treffen, wird das Verhalten der beiden statisti-schen Verfahren auf ausgewahlten Einzugsgebieten untersucht. Dafur werdenin Kapitel 3 zunachst die vier Untersuchungsgebiete im Uberblick vorgestellt.Dies sind die Einzugsgebiete der Wilden Gera, der Gera, der Roda und derWipper. Alle vier Einzugsgebiete befinden sich in Deutschland, im Bundes-land Thuringen. Die Einzugsgebiete unterscheiden sich zum Teil stark inGroße, Bodenbeschaffenheit, Landnutzung und abfließender Wassermenge.Das vierte Kapitel teilt sich in die Anwendung der Gaußprozessregression(Abschnitt ??) und die Anwendung mehrschichtiger Perzeptronennetze (Ab-schnitt ??). Beide Abschnitte sind so gegliedert, dass fur jedes Einzugsgebietein geeignetes Modell bestimmt wird und dieses im nachsten Unterabschnitt,zunachst fur einen Vorhersagezeitraum von einem Zeitschritt, evaluiert wird.Im dritten Unterabschnitt wird versucht den Vorhersagezeitraum auf mehre-re Zeitschritte zu erweitern.Die Suche nach geeigneten Modellen besteht im Rahmen der Gaußprozessre-gression vor allem darin geeignete Kovarianzfunktionen und Erwartungswert-funktionen und zu finden, sowie die Optimierung derselbigen. Auf Grund derhohen Komplexitat der Berechnungen muss die Trainingsmenge kunstlichverkleinert werden. Hierzu wird eine Greedy - Strategie verwendet. Die Re-sultate des Modellauswahlphase sind, dass durch Anwendung der Greedy -Strategie die Trainingsmenge auf bis zu 40% verkleinert werden kann, dieRelevanzanalyse durch Optimierung der Parameter prinzipiell sinnvolle Er-gebnisse liefert und viele Gaußprozessmodelle sehr gute Ergebnisse in Bezugauf die Problemstellung liefern. Die besten Modelle wurden meist mit neu-ronalen Netzwerk Kovarianzfunktionen, linearen Erwartungswertfunktionenund einem Eingabezeitraum trel von zwei erreicht.Bei mehrschichtigen Perzeptronennetzen gestaltet sich die Modellauswahl et-was einfacher. Modellparameter, die bestimmt werden mussen, sind die Netz-topologie, Verfahrensparameter des Backpropagation Lernverfahrens und derRelevanzzeitraum trel. Die Netztopologie und der Parameter trel werden mitHilfe einer vollstandigen Suche bestimmt und die Verfahrensparameter mitHilfe eines Gradientenabstiegs. Eine kunstliche Verkleinerung der Trainings-menge ist nicht erforderlich, allerdings kann auch keine Relevanzanalyse durch-gefuhrt werden. Außerdem werden gemittelte Vorhersagen betrachtet. Beider Modellauswahl zeigt sich, dass bereits kleine Netze mit einer Schichtund wenigen Knoten gute Ergebnisse liefern, sich große Netze aber seltenschlechter verhalten. Die Lernrate liegt im Bereich von 0, 05 bis 0, 1. Das

106 KAPITEL 6. ZUSAMMENFASSUNG UND AUSBLICK
Tragheitsmoment β des Backpropagation - Verfahrens wird in drei Fallen zu0 und einmal zu 0, 2 bestimmt und wird damit praktisch unwirksam. DerRelevanzzeitraum schwankt je nach Einzugsgebiet zwischen zwei und vierTagen. Desweiteren zeigt sich, dass die gemittelten Vorhersagen kaum zu ei-ner Verbesserung der Ergebnisse beitragen.Die Untersuchung der gewahlten Gaußprozess und Perzeptronennetz Mo-
delle, zunachst auf Vorhersagen uber einen Tag, zeigt, dass beide Verfahrengute Ergebnisse liefern. Die relativen Nash - Sutcliffe Effizienzen liegen durch-schnittlich bei 0, 58 und die absoluten Werte durchschnittlich bei 0, 83. Nurim Einzugsgebiet der Roda werden vergleichsweise schlechte Ergebnisse er-zielt, die Vorhersagen der neuronalen Netze zeigen hier eine systematischeUnterschatzung. Insgesamt zeichnen sich die Gaußprozessmodelle durch et-was bessere Modelleffizienzen aus, als die vergleichbaren neuronalen Netze.Unsicherheiten treten bei beiden Ansatzen in den selben Situationen auf.Dazu gehoren vor allem starke Niederschlagsereignisse und Schneeschmelzen.Vorteilhaft an den Ergebnisse der Gaußprozessregression ist, dass die Para-meter der entstehenden Modelle oftmals direkt interpretiert werden konnenund bereits im Vorfeld eine Einschatzung der Modelle erlauben. Um eineVerlangerung des Vorhersagezeitraumes zu gewahrleisten wird angenommen,dass zukunftige Eingabedaten in verrauschter Form zur Verfugung stehen.Die Vorhersage der Abflusswerte erfolgt iterativ, zunachst fur den Tag t + 1,dann fur den Tag t + 2 bis hin zu dem gewunschten zukunftigen Tag. Auchhier lassen sich in den Ergebnissen der Gaußprozessregression und der Per-zeptronennetze keine großen Unterschiede feststellen. Die Genauigkeit ver-ringerte sich in beiden Fallen stark mit einem Anwachsen des Vorhersage-zeitraumes und der Intensitat der Storungen. Gaußprozessregressionsmodel-le zeigen einen besonders starken Abfall der Gute bei der Vergroßerung desVorhersagezeitraumes auf zwei Tage. Solange die Starke der Storungen ei-ne gewisse Grenze nicht uberschreitet, werden auch fur langere Vorhersa-gezeitraume brauchbare Ergebnisse geliefert. Der Korrelationskoeffizient r2
zwischen gestorten und ungestorten Daten sollte mindestens einen Wert von0, 9 aufweisen. Heutige Methoden zur quantitativen Niederschlagsvorhersagekonnen diese Genauigkeit nicht erreichen, so dass eine Vorhersage des Ab-flusses uber mehrere Tage derzeit nicht moglich ist.Zusammenfassend lasst sich sagen, dass die vorgestellten Verfahren in derLage sind prazise Abflussvorhersagen fur einen Zeitraum von 24 Stunden zugeben. Langere Vorhersagen sind kaum realisierbar, da derzeitige Methodennicht in der Lage sind, Niederschlage mit ausreichender Prazision zu progno-stizieren.Ist fur den realen Einsatz zu entscheiden, welche der beiden Methoden ver-wendet werden soll, so ist die Regression mit Gaußprozessen zu bevorzugen.Die Grunde hierfur sind nicht nur in den etwas besseren Modellergebnissen zu

107
sehen, sondern vor allem in der besseren Interpretierbarkeit der Modelle. JedeVorhersage eines Gaußprozessmodells besteht aus einer Wahrscheinlichkeits-verteilung, die neben dem Erwartungswert auch eine Varianz besitzt. Daduchliefert das Modell selbst eine Aussage daruber, wie sicher eine bestimmte Vor-hersage ist. Zu dieser Einschatzung sind mehrschichtige Perzeptronennetzenicht in der Lage. Desweiteren besitzen die Kovarianzfunktionen der Gauß-prozesse Parameter, die leicht interpretiert werden konnen und Ruckschlusseauf die Relevanz einzelner Eingabekomponenten erlauben. Dadurch konnenInformation gewonnen werden, die weit uber einzelne Vorhersagen hinaus ge-hen.Als Standardparameterisierung der Gaußprozessregression ist eine neuronaleNetzwerk Kovarianzfunktion mit linearer Erwartungswertfunktion und LMSE
Kriterium fur die Parameteroptimierung zu empfehlen, da mit dieser Kom-bination in allen betrachteten Untersuchungsgebieten sehr gute Ergebnisseerzielt werden. Bei Bedarf kann damit auf einen aufwandigen Modellaus-wahlprozess verzichtet werden. Eine Optimierung der Kovarianzfunktions-parameter ist dennoch erforderlich. Der hierfur erforderliche Rechen- undSpeicherbedarf stellt den großten Nachteil der Gaußprozessregression dar,da aus diesem Grund einige Einschrankungen getroffen werden mussten. Esist daher denkbar, dass eine zukunftige Erhohung der Rechenkapazitat zuMoglichkeiten fuhrt, die weitere Verbesserungen der Ergebnisse mit sich brin-gen. Beispielsweise ist es wunschenswert die Anzahl der Trainingsbeispielenicht einzuschranken und die gesamte Trainingsmenge fur die Regression zuverwenden. Sinnvoll ist es auch Kovarianzfunktionen mit einer großeren An-zahl von Parametern zu betrachten. Beispielsweise wurden fur die MatrixΣ der neuronalen Netzwerk Kovarianzfunktion bisher stets Diagonalmatri-zen verwendet, wodurch die Anzahl der Parameter, aber auch der Modellie-rungsmoglichkeiten stark reduziert wurden. Vielversprechend ist die Anwen-dung der Gaußprozessregression auf andere hydrologische Problemstellungen,insbesondere dort wo bereits kunstliche neuronale Netze mit Erfolg verwen-det werden. Beispiele hierfur sind unter anderem: das Fullen von Lucken inZeitreihen unter Anwendung einer zeitlichen oder raumlichen Regression, diekurzfristige Prognose von Niederschlagen auf Datengrundlage von Zeitreihenoder von Radarbeobachtungen und die statistische Modellierung von Stoff-transportprozessen in Fließgewassern, sowie die Vorhersage der Wasserqua-litat. Selbst wenn die Regression mit Gaußprozessen dabei großen Erfolg hat,werden kunstliche neuronale Netzen dadurch aber auf keinen Fall uberflussig,da diese sehr flexibel einsetzbar sind und Anwendungsmoglichkeiten besit-zen, die weit uber die der Gaußprozessregression hinaus gehen. Die Gauß-prozessregression kann auch als mogliche Alternative angesehen werden, dieeingesetzt werden kann, wenn kustliche neuronale Netze bei einer Regressi-onsaufgabe versagen und die Ursache hierfur nicht bekannt ist.

108 KAPITEL 6. ZUSAMMENFASSUNG UND AUSBLICK

Literaturverzeichnis
A. S. Tokar, P. A. J. Rainfall-runoff modeling using artificial neural networks.Journal of Hydrologic Engineering, pages 232–239, 1999.
Abbott, M. and J. Refsgaard. Distributed hydrological modelling. KluwerAcademic, 1996.
Abramowitz, M. and I. A. Stegun. Handbook of Mathematical Functions withFormulas, Graphs, and Mathematical Tables. Dover, New York, 1964.
Alt, W. Nichtlineare Optimierung. Eine Einfuhrung in Theorie, Verfahrenund Anwendungen. Vieweg, 2002.
Aqil, M., I. Kita, A. Yano, and S. Nishiyama. A comparative study of artificialneural networks and neuro-fuzzy in continuous modeling of the daily andhourly behaviour of runoff. Journal of Hydrology, 337(1-2):22–34, 2007.
Bartlett, P. For valid generalization, the size of the weights is more importantthan the size of the network. Advances in Neural Information ProcessingSystems, 9(134-140):8J, 1997.
Bastarache, D., N. El-Jabi, N. Turkkan, and T. Clair. Predicting conductivityand acidity for small streams using neural networks. Can. J. Civ. Eng, 24(6):1030–1039, 1997.
Bathurst, J. Physically-Based Distributed Modelling of an UplandCatchment Using the Systeme Hydrologique Europeen. Journal of Hy-drology JHYDA 7, 87(1/2), 1986.
Baumgartner, A., H. Liebscher, and P. Benecke. Lehrbuch der Hydrologie.Borntraeger, 1996.
Bedient, P., B. Hoblit, D. Gladwell, and B. Vieux. NEXRAD Radar for FloodPrediction in Houston. Journal of Hydrologic Engineering, 5(3):269–277,2000.
109

110 LITERATURVERZEICHNIS
Blight, B. and L. Ott. A Bayesian approach to model inadequacy for poly-nomial regression. Biometrika, 62(1):79, 1975.
Calver, A. Calibration, Sensitivity and Validation of a Physically-BasedRainfall-Runoff Model. Journal of Hydrology JHYDA 7, 103(1-2), 1988.
Carreira-Perpinan, M. A review of dimension reduction techniques. Tech-nique Report, CS-96-09. Department of Computer Science, University ofSheffield, 1996.
C.W. Dawson, R. W. An artifical neural network approach to rainfall-runoffmodelling. Hydrological Sciences Journal, pages 47–66, 1998.
D. Bastarache, N. E.-J. and N. Turkham. Predicting conductivity and aci-dity for small streams using neural networks. Canadian Journal of CivilEngineering, pages 1030–1039, 1997.
Damrath, U., G. Doms, D. Fruehwald, E. Heise, B. Richter, and J. Steppeler.Operational quantitative precipitation forecasting at the German WeatherService. Journal of Hydrology(Amsterdam), 239(1):260–285, 2000.
Dooge, J. General report on model structure and classification. In Logi-stics and Benefits of Using Mathematical Models of Hydrologic and WaterResource Systems, volume 13, pages 1–21, 1981.
Fahlman, S. Faster-Learning Variations on Back-Propagation: An Empiri-cal Study. Proceedings of the 1988 Connectionist Models Summer School,pages 38–51, 1988.
G. Allen, L. M. An evaluation of neural networks and discriminant ana-lysis methods for application in operational rain forecasting. AustralianMeteorological Magazine, pages 17–28, 1994.
Geisser, S. Predictive Inference: An Introduction. Chapman and Hall, 1993.
Golding, B. Quantitative precipitation forecasting in the UK. Journal ofHydrology(Amsterdam), 239(1):286–305, 2000.
H. R. Maier, G. C. D. Neural networks for the prediction and forecastingof water resource variables: a review of modelling issues and applications.Environmental Modelling and Software, pages 101–124, 2000.
Haude, W. Zur Bestimmung der Verdunstung auf moglichst einfache Weise.Deutscher Wetterdienst, 1955.

LITERATURVERZEICHNIS 111
Haykin, S. Neural Networks: A Comprehensive Foundation. Prentice HallPTR Upper Saddle River, NJ, USA, 1994.
Hermann, M. Numerische Mathematik. Oldenbourg, 2001.
Hsu, K., H. Gupta, and S. Sorooshian. Artificial neural network modeling ofthe rainfall-runoff process. Water Resources Research, 31(10):2517–2530,1995.
Iglewicz, B. Robust scale estimators and confidence intervals for location.Understanding Robust and Exploratory Data Analysis. Wiley, New York,pages 404–429, 1983.
Imrie, C., S. Durucan, and A. Korre. River flow prediction using artificialneural networks: generalization beyond the calibration range. Journal ofHydrology(Amsterdam), 233(1):138–153, 2000.
J. M. Faures, D.C. Goodrich, D. W. and S. Soroshian. Impact of small-scalespatial rainfall variability on runoff modeling. Journal of Hydrology, pages309 – 326, 1995.
J.E. Nash, J. S. River flow forecasting through conceptual models. Journalof Hydrology, pages 282 – 290, 1970.
J.L. Crespo, E. M. Drought estimation with neural networks. Advances inEngineering Software, pages 167–170, 1993.
Johansson, E., F. Dowla, and D. Goodman. Backpropagation learning formultilayer feed-forward neural networks using the conjugate gradient me-thod. International Journal of Neural Systems, 2(4):291–301, 1992.
Karunanithi, N., W. Grenney, D. Whitley, and K. Bovee. Neural networksfor river flow prediction. Journal of Computing in Civil Engineering, 8(2):201–220, 1994.
Krause, P. Internes Arbeitsscript zum J2000 am Lehrstuhl fur Geoinforma-tik, Geohydrologie und Modellierung; Institut fur Geographie; FriedrichSchiller Universitat Jena, 2004.
Krause, P., D. Boyle, and F. Base. Comparison of different efficiency criteriafor hydrological model assessment. Advances in Geosciences, 5:89–97, 2005.
Krause, P., F. Julich, and P. S. und Technologische Entwicklung. Das hy-drologische Modellsystem j2000: Beschreibung und Anwendung in grossenFlussgebieten. Forschungszentrum, Zentralbibliothek, 2001.

112 LITERATURVERZEICHNIS
Leavesley, G. and L. Stannard. The precipitation-runoff modeling system-PRMS. Computer Models of Watershed Hydrology, pages 281–310, 1995.
Lorrai, M. and G. Sechi. Neural nets for modelling rainfall-runoff transfor-mations. Water Resources Management, 9(4):299–313, 1995.
Maidment, D. Handbook of Hydrology. McGraw-Hill, 1993.
McCulloch, W. and W. Pitts. A logical calculus of the ideas immanent innervous activity. Bulletin of Mathematical Biophysics, 5:115–133, 1943.
Minns, A. and M. Hall. Artificial neural networks as rainfall-runoff models.Hydrological Sciences Journal/Journal des Sciences Hydrologiques, 41(3):399–417, 1996.
Monteith, J. Evaporation and environment. In The state and movement ofwater in living organism, pages 205 – 234. Cambridge (Univ Press), 1965.
More, J. The Levenberg-Marquardt algorithm: implementation and theory.Conference on numerical analysis, 28, 1977.
Nandakumar, N. and R. Mein. Uncertainty in rainfall - runoff model simula-tions and the implications for predicting the hydrologic effects of land-usechange. Journal of Hydrology, pages 211 – 232, 1997.
Nauck, D., F. Klawonn, and R. Kruse. Neuronale Netze und Fuzzy-systeme: Grundlagen des Konnektionismus, neuronaler Fuzzy-systeme undder Kopplung mit wissensbasierten Methoden. Vieweg, 1996.
Neal, R. Bayesian Learning for Neural Networks. Springer, 1996.
Rasmussen, C. and C. Williams. Gaussian Processes for Machine Learning.Springer, 2006.
R.D. Braddock, M.L. Kremmer, L. S. Feed forward artifical neural networkmodel for forecasting rainfall run-off. In Proceedings of the InternationalCongress on Modelling and Simulation (Modsim 97), pages 1653–1658,1997.
Renger, M. and G. Wessolek. Auswirkungen von grundwasserabsenkung undnutzungsanderung auf die grundwasserneubildung. Mittelungen des Insti-tuts fur Wasserwesen, pages 295 – 307, 1990.
Ruck, M. Jahresruckblick Naturkatastrophen 2002. Topics, Jg, 10, 2003.

LITERATURVERZEICHNIS 113
Scholkopf, B. and A. Smola. Learning with Kernels: Support Vector Machi-nes, Regularization, Optimization, and Beyond. MIT Press Cambridge,MA, USA, 2001.
Schroder, W. Grundlagen des Wasserbaus: Hydrologie, Hydraulik-Wasserbau. Werner, Dusseldorf, 1994.
Shamseldin, A. Application of a neural network technique to rainfall-runoffmodelling. Journal of Hydrology(Amsterdam), 199(3):272–294, 1997.
Sherman, L. K. Streamflow from rainfall by the unit-graph method. Eng.News Record, pages 501 – 505, 1932.
Stein, M. Interpolation of Spatial Data: Some Theory for Kriging. Springer,1999.
Sugimoto, S., E. Nakakita, and S. Ikebuchi. A stochastic approach to short-term rainfall prediction using a physically based conceptual rainfall model.Journal of Hydrology(Amsterdam), 242(1):137–155, 2001.
Sun, X., R. Mein, T. Keenan, and J. Elliott. Flood estimation using radarand raingauge data. Journal of Hydrology(Amsterdam), 239(1):4–18, 2000.
Swerdlow, N. Ancient Astronomy and Celestial Divination. Mit Pr, 1999.
Tetko, I., D. Livingstone, and A. Luik. Neural network studies. 1. Compari-son of overfitting and overtraining. Journal of Chemical Information andComputer Sciences, 35(5):826–833, 1995.
Thirumalaiah, K. and M. Deo. Real-time flood forecasting using neural net-works. COMPUT AID CIV INFRASTRUCT ENG, 13(2):101–111, 1998.
Thornthwaite, C. An approach toward a rational classification of climate.Geographical Review, pages 55 – 94, 1948.
Toth, E., A. Brath, and A. Montanari. Comparison of short-term rainfallprediction models for real-time flood forecasting. Journal of Hydrolo-gy(Amsterdam), 239(1):132–147, 2000.
Tveter, D. Backpropagators review, 2004. Web Pages athttp://www.dontveter.com/bpr/bpr.html.
W., K. and T. Th. Water related disasters : Loss trends and possible countermeasures from a (re)insurers viewpoint. In Floods Droughts and Landslides- Who plans, who pays, 2002.

114 LITERATURVERZEICHNIS
Wahba, G. Spline Models for Observational Data. Society for Industrial &Applied Mathematics, 1990.

Glossar
automatische Relevanzbestimmung
Automatische Bestimmung des Einflusses einzelner Eingabefaktorenauf die Ergebnisgroße
Bodenart
Beim Bodenwarmestrom handelt es sich und die Warmeernergiemenge,welche aufgrund von Warmeleitung von einer warmeren zu einer kalterenBodenschicht fließt.
Bodenart
Die Bodenart beschreibt die Zusammensetzung des Bodens bezuglichder Hauptbodenarten: Sand, Schluff, Ton, Lehm
charakteristischen Langenskalierung
Gewichtung von Eingabegroßen
Einzugsgebiet
Das Einzugsgebiet ist jener Bereich, der alle Niederschlage und die dar-aus entstehenden Abflusse in ein Fließgewasser ableitet und es damitspeist
Gaußprozess
siehe Abschnitt ??
Generalisierungsfehler
Fehler den ein statistisches Modell auf unbekannten Daten macht
Gradientenabstiegsverfahren
lokales Optimierungsverfahren
115

116 Glossar
Interflow
Teil des Niederschlages, der nicht bis zur Grundwasseroberflache ge-langt, sondern aus dem Gebiet als unterirdischer Abfluss den Was-serlaufen zufließt oder eine Wasserstromung, die sich durch die oberenSchichten einer Formation mit einer Menge bewegt, die weit uber dernormalen Versickerung liegt.
kunstliche neuronale Netze
siehe Abschnitt ??
Kernel Machine
statistische Verfahren, die mit Kernel Funktionen arbeiten.
Konfidenzintervall
Das Konfidenzintervall schließt einen Bereich um den geschatzten Wertdes Parameters ein, der vereinfacht gesprochen mit einer zuvor festge-legten Wahrscheinlichkeit die wahre Lage des Parameters trifft.
Kovarianzfunktion
Beschreibt die Ahnlichkeit zwischen Zufallsvariablen, (siehe Definition??)
Kovarianzfunktion der Matern Klasse
spezielle Klasse von Kovarianzfunktion, siehe Abschnitt ??
Kreuzvalidierung
siehe Abschnitt ??
Lithosphare
Die Lithosphare umfasst die Erdkruste und den lithospharischen Man-tel.
Marginal Likelihood
siehe Abschnitt ??
Modellkalibrierung
Anpassung der Modellparameter auf eine spezielles Einzugsgebiet
Neuronale Netzwerk Kovarianzfunktion
spezielle Klasse von Kovarianzfunktion, siehe Abschnitt ??

Glossar 117
Niederschlag
Wasser der Atmosphare, das nach Kondensation oder Sublimation vonWasserdampf in der Lufthulle ausgeschieden wurde und sich infolge derSchwerkraft entweder zur Erdoberflache bewegt oder zur Erdoberflachegelangt ist (siehe Abschnitt ??).
overfitting
Ein Regressionmodell ist overfitted, falls es durch Uberparamterisierungperfekt an die Daten angepasst ist, obwohl es dem Regressionsproblemnicht gerecht wird.
Perkolation
Die Perkolation beschreibt das Durchfließen von Wasser durch ein festesSubstrat.
potentielle Verdunstung
maximal mogliche Verdunstung unter gewissen Umweltbedingungen
quadratisch exponentielle Kovarianzfunktion
spezielle Klasse von Kovarianzfunktion, siehe Abschnitt ??
Rational quadratische Kovarianzfunktion
spezielle Klasse von Kovarianzfunktion, siehe Abschnitt ??
Regression
statistisches Analyseverfahren zum Herstellen von Beziehungen zwi-schen Variablen
Sattigungsdampfdruck
Der Sattigungsdampfdruck beschreibt den bei einer bestimmten Tem-peratur maximalen Dampfdruck.
Sattigungsdefizit
Das Sattigungsdefizit, auch Dampfhunger oder eingeschrankt Dampf-druckdifferenz, bringt zum Ausdruck, wie stark ein Gas bezuglich einerKomponente gesattigt ist.
statistisches Modell
Modell auf rein statistischer Grundlage

118 Glossar
Topographie
Form, Relief und Art der Erdoberflache
Training
Anpassung eines statistischen Modelles mit Hilfe eines Lernverfahrensund einer Menge von Trainingsdaten
Trainingsdaten
Menge von Beispielen eines funktionalen Zusammenhanges
underfitting
Ein Regressionsmodell ist underfitted, falls es mit der Menge der er-laubten Basisfunktionen dem Regressionsproblem nicht gerecht werdenkann
Validierung
Test des Modells mit unbekannten Daten mit dem Ziel den Generali-sierungsfehler abzuschatzen
Verdunstung
Die Verdunstung ist der Vorgang, bei dem Wasser bei Temperatu-ren unter dem Siedepunkt vom flussigen oder festen Zustand in dengasformigen ubergeht (siehe Abschnitt ??)
Verdunstungswarme
Die Verdampfungswarme ist die Warmemenge, die benotigt wird, umeine bestimmte Menge einer Flussigkeit vom flussigen in den gasformigenAggregatzustand zu bringen.
Vorfluter
Gerinne, in dem Wasser in ein Gewasser abfließen kann
Warmekapazitat
Bezeichnet das Vermogen eines Korpers, Energie in Form von thermi-scher Energie statistisch verteilt auf die Freiheitsgrade zu speichern.
Wasserabfluss
Wasservolumen, das pro Zeiteinheit einen definierten oberirdischen Fließ-querschnitt durchfließt

Glossar 119
Wasserspeicher
Wasservorrat eines Einzugsgebietes

120 Glossar

Selbststandigkeitserklarung
Selbststandigkeitserklarung
Ich erklare, dass ich die vorliegende Arbeit selbststandig und nur unter Ver-wendung der angegebenen Quellen und Hilfsmittel angefertigt habe. Ich habeaus anderen Werken entnommene Daten, Abbildungen sowie wortliche undsinngemaße Zitate mit Quellenangaben gekennzeichnet.
Jena, den 12. Januar 2008
Christian Fischer
121

122 Glossar
Im letzten Jahrzehnt ist in der Anzahl der Arbeiten auf dem Feld derKernel Maschinen ein enormer Anstieg zu verzeichnen gewesen. Sehr ver-breitet sind die Arbeiten zu Support Vektor Maschinen (SVM). Allerdingswurde wahrend dieser Zeit auch viel Aktivitat darauf verwendet, Gaußpro-zessmodelle auf Problemstellungen aus dem Bereich des maschinellen Ler-nens anzuwenden. Gaußprozesse stellen einen universellen und praktischenAnsatz zum Lernen mit Kernel Maschinen dar. Durch ein solides statistischeFundament birgt das Lernen mit Gaußprozessen Vorteile bezuglich der Inter-pretierbarkeit von Modellvorhersagen und bietet ein fundiertes Frameworkfur Modellauswahl und die anschließende Modellerstellung. Theoretische undpraktische Entwicklungen haben in den letzten Jahren dazu gefuhrt, dassGaußprozesse eine ernst zu nehmende Methode im Bereich von Anwendun-gen des uberwachten Lernens geworden sind. Trotzdem hat diese Verfah-rensklasse bisher wenig Beachtung im Bereich von hydrologischen Problem-stellungen gefunden. Es ist daher von Interesse die Gaußprozessregressionauf die Problemstellung der Rainfall-Runoff-Modellierung anzuwenden. DieGaußprozesseregression beruht auf der Annahme, dass Beobachtungen einemnormalverteilten stochastischen Prozess folgen. Allein dadurch kann gezeigtwerden, dass neue Beobachtungen die Wahrscheinlichkeitsverteilung der al-ten Beobachtungen nicht andert. Diese einfache Feststellung ermoglicht es,Aussagen uber unbekannte Werte zu treffen. Durch die Auswahl der Kovari-anzfunktion des Gaußprozesses konnen a priori Annahmen in die Regressioneingebracht werden. In diesem Zusammenhang ist es moglich, die Parameterder Kovarianzfunktion automatisch zu bestimmen und auf diese Weise eineGewichtung in der Relevanz der Eingabegroßen zu erhalten. Dies erlaubt esbeispielsweise nicht relevante und somit uberflussige Eingabekomponentenzu erkennen und zu eleminieren.