
1. Comparación de dos muestras cuando no es posible ... · Regla de la multiplicación. Sabemos...
15
Parte 5. Pruebas no paramétricas. Autor: Santiago Perez Lloret En este documento analizaremos brevemente algunas pruebas de hipótesis que pueden aplicarse cuando las pruebas “t” no son válidas y nos focalizaremos sobre la prueba de Χ 2 (chi-cuadrado). 1. Comparación de dos muestras cuando no es posible aplicar las pruebas t. Es imprescindible tener en cuenta que los efectos de emplear una prueba de confrontación de hipótesis cuando sus requerimientos (también llamados “asunciones”) no se cumplen, pueden ser graves. Lo que ocurrirá será que el error α o el β se incrementarán en una magnitud imposible de precisar. De esta manera lo único que conseguiremos será un resultado en el que no podemos confiar. Por ello, cuando las asunciones para la aplicación de las pruebas t no se cumplen, debemos recurrir a otras alternativas. Comentaremos brevemente algunas de ellas. A continuación le mostramos la distribución poblacional de dos variables creatinina y hematocrito evaluada a partir de una base de datos que incluyó más de 10000 pacientes con enfermedades renales.
-
Upload
nguyenquynh -
Category
Documents
-
view
215 -
download
0
Transcript of 1. Comparación de dos muestras cuando no es posible ... · Regla de la multiplicación. Sabemos...
Parte 5. Pruebas no paramétricas.
Autor: Santiago Perez Lloret
En este documento analizaremos brevemente algunas pruebas de hipótesis que
pueden aplicarse cuando las pruebas “t” no son válidas y nos focalizaremos sobre
la prueba de Χ2 (chi-cuadrado).
1. Comparación de dos muestras cuando no es posible
aplicar las pruebas t.
Es imprescindible tener en cuenta que los efectos de emplear una prueba de
confrontación de hipótesis cuando sus requerimientos (también llamados
“asunciones”) no se cumplen, pueden ser graves. Lo que ocurrirá será que el error
α o el β se incrementarán en una magnitud imposible de precisar. De esta manera
lo único que conseguiremos será un resultado en el que no podemos confiar. Por
ello, cuando las asunciones para la aplicación de las pruebas t no se cumplen,
debemos recurrir a otras alternativas. Comentaremos brevemente algunas de
ellas.
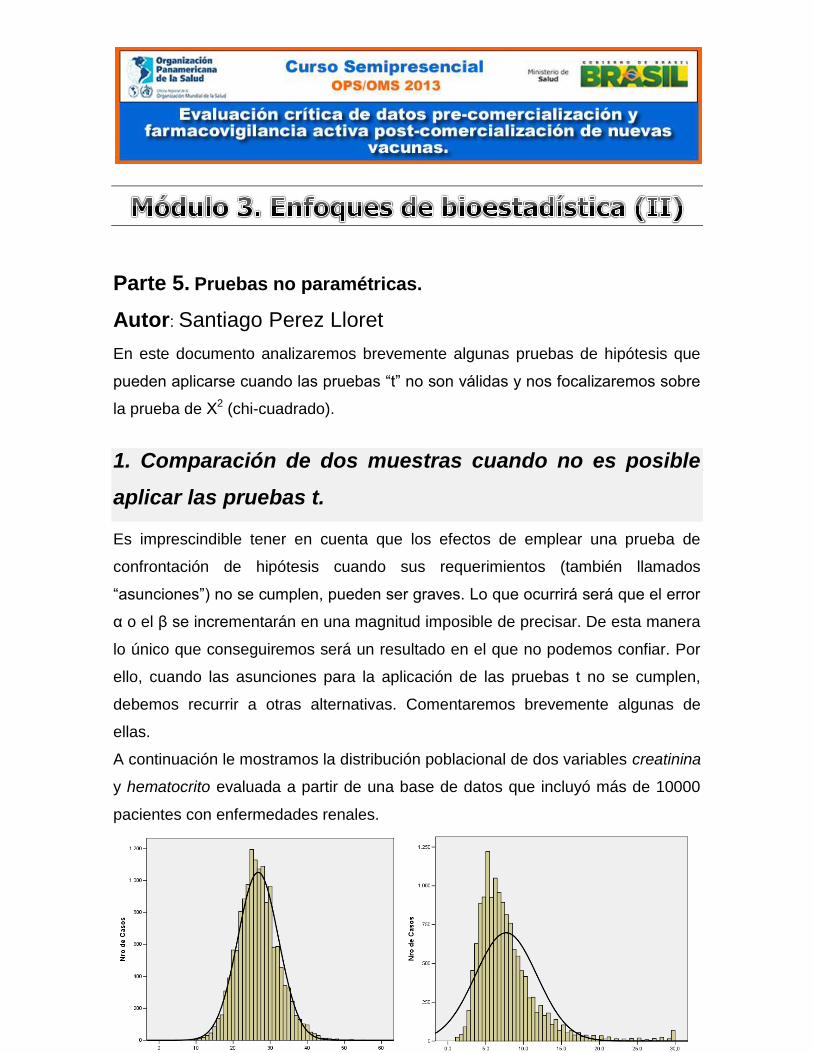
A continuación le mostramos la distribución poblacional de dos variables creatinina
y hematocrito evaluada a partir de una base de datos que incluyó más de 10000
pacientes con enfermedades renales.
Observe que mientras que el histograma de distribución de frecuencia para la
variable hematocrito muestra una distribución que se ajusta casi perfectamente a
la distribución gaussiana, la creatinina no. En cambio ella muestra un sesgo
positivo (es decir, hacia la derecha). Se observa que la distribución normal no
provee un modelo satisfactorio para el análisis de esta variable.
En estos casos se pueden emplear transformaciones matemáticas. Existen un
buen número de ellas y su objetivo es, mediante la manipulación matemática, de
los datos, poder analizar, mediante métodos paramétricos (como las pruebas t),
variables cuyas distribuciones se alejan de la normalidad. Una de las más
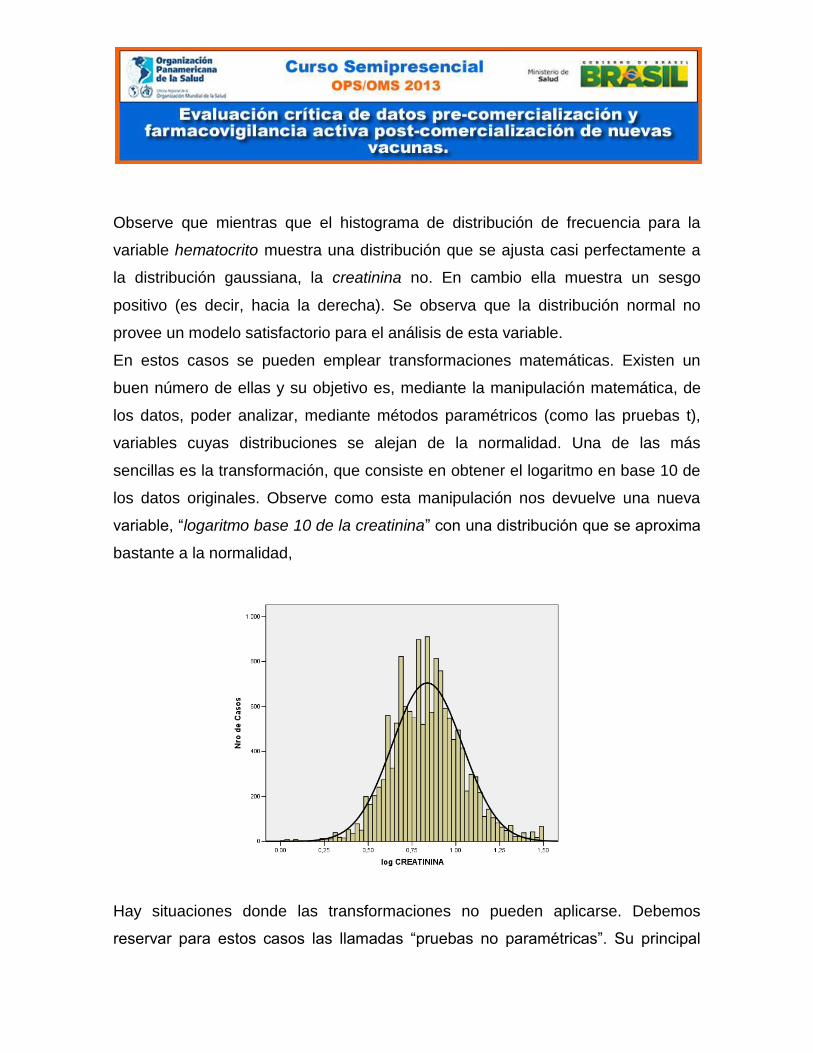
sencillas es la transformación, que consiste en obtener el logaritmo en base 10 de
los datos originales. Observe como esta manipulación nos devuelve una nueva
variable, “logaritmo base 10 de la creatinina” con una distribución que se aproxima
bastante a la normalidad,
Hay situaciones donde las transformaciones no pueden aplicarse. Debemos
reservar para estos casos las llamadas “pruebas no paramétricas”. Su principal
desventaja es que frecuentemente presentan menos poder estadístico en
comparación con las pruebas paramétricas. Esto implica que -en muchos casos-
no podremos rechazar H0 aún a pesar de que H1 sea en realidad verdadera.
Asimismo, las pruebas paramétricas nos permiten evaluar ciertos parámetros
poblacionales, basadas en la distribución muestral de la media, cosa que es
imposible con las pruebas no paramétricas. Por ello, estas pruebas deben
reservarse como última opción.
En la siguiente Tabla resumimos las diferentes pruebas que podemos utilizar en
diferentes situaciones.
Prueba paramétrica Situación Prueba no paramétrica
correspondiente
Prueba t para
muestras
independientes
Comparación de 2
muestras independientes
Prueba “U de Mann-
Whitney”
Prueba t para
muestras
dependientes
Comparación de muestras
apareadas Prueba de Wilcoxon
Análisis de la
Varianza (ANOVA)
Comparación de 3 o más
muestras independientes Prueba de Kruskal-Wallis
ANOVA para medidas
repetidas
Comparación de 3 o más
muestras dependientes Prueba de Friedman

2. Análisis de datos categóricos mediante la prueba de χ2
(Chi-cuadrado).
La prueba de Chi-cuadrado es una prueba de gran versatilidad que nos permite
evaluar asociaciones entre variables categóricas (ya sean nominales u ordinales).
Sin embargo, antes de pasar a describirla en mayor detalle, nos detendremos a
analizar un concepto de fundamental importancia, la “independencia probabilística
de los eventos”.
Eventos independientes. Regla de la multiplicación.
Sabemos que no existe ninguna relación entre el color de pelo y el sexo, de modo
tal que no hay razón para suponer que existe una “asociación” entre estas dos
características. Supongamos que se evaluó el color de pelo en 500 hombres y un
número similar de mujeres y que se observaron estos resultados,
Mujeres Hombres Total
Rubios 250 (25%) 250 (25%) 500 (50%)
Pelirrojos 50 (5%) 50 (5%) 100 (10%)
Morochos 200 (20%) 200 (20%) 400 (40%)
Total 500 (50%) 500 (50%) 1000 (100%)
Observando los datos podemos llegar a la conclusión que la frecuencia de sujetos
con cabelleras de los diferentes colores es la misma en ambos sexos. En otras
palabras, podemos afirmar que los eventos “ser hombre” (o ser mujer) y “pelo

rubio” (o morocho o pelirrojo), son independientes entre sí. Analicemos con más
detalle la base matemática del concepto.
Podemos calcular con bastante precisión el porcentaje de sujetos en cada celda
conociendo los porcentajes de la fila y columna marcadas como “total”. Así, la
siguiente fórmula nos permitirá conocer el porcentaje de mujeres con pelo rubio:
p(mujer y pelo rubio) = p(pelo rubio) * P(mujer)
donde p= frecuencia relativa (o más sencillamente probabilidad)
De la columna de totales obtenemos que la p(pelo rubio) = 0.5 o 50%. Asimismo
de la fila totales obtenemos que la p(mujer) = 0.5 o 50%. Así,
P(mujer y pelo rubio) = 0.5 * 0.5 = 0.25 o 25%, que es el valor que figura en la
tabla.
Aplicando el mismo procedimiento podemos calcular los valores de todas las
celdas. Las probabilidades de los eventos (ser mujer/hombre por un lado y tener el
pelo de algún color por el otro) se denominan “probabilidades marginales”.
Por otro lado, podemos emplear una fórmula análoga para calcular la cantidad de
mujeres de pelo rubio, no ya la probabilidad. Veámosla,
cantidad de mujeres * cantidad de sujetos de pelo rubiocantidad de mujeres de pelo rubio=
cantidad total de sujetos evaluados
500 * 500250
1000
Que es similar a la cantidad de mujeres de pelo rubio que figuran en la tabla.
Diremos que 2 eventos son independientes cuando la probabilidad de su
ocurrencia conjunta (por ejemplo, ser mujer y de pelo rubio) es igual a la
multiplicación de las probabilidades marginales de los dos eventos. El

mismo concepto aplica al cálculo de la cantidad de sujetos en cada
circunstancia.
El funcionamiento de la prueba de Chi-cuadrado se basa en este concepto.
Esencialmente esta prueba nos permitirá calcular la probabilidad (valor p) de que
las dos variables categóricas sean independientes entre sí. Si dicha probabilidad
es inferior a 5% (p<0.05) descartamos la hipótesis de la independiencia (que será
H0) y aceptamos la hipótesis que establece una asociación entre las dos variables
en análisis.
3. Pasos de la prueba de Chi-cuadrado.
Comencemos con un ejemplo. Un investigador estaba interesado en evaluar la
eficacia de una nueva vacuna para el cólera en un grupo de sujetos expuestos y
no expuestos. Para ello se siguió durante 12 meses dos grupos de sujetos: uno
expuesto y otro no expuesto a la vacuna. Se registró la frecuencia de diarrea
severa. Observó los siguientes resultados,
Diarrea Sin Diarrea Total
Vacuna 366 2931 3297
Sin vacuna 345 672 1017
Total 711 3603 4314
Paso 1. Reformular la pregunta científica en forma de hipótesis estadísticas.
El interés recae en investigar la posible asociación entre determinada vacuna y la
aparición de diarrea. Dicho de otra manera, deseamos averiguar si existe una
diferencia entre la probabilidad de presentar diarrea habiendo sido vacunado y la

probabilidad de presentarla sin haber recibido la vacuna. Con estos conceptos, ya
estamos en condiciones de definir nuestras hipótesis:
H0= p(Diarrea/vacuna+) = p(Diarrea/vacuna-)
H1= p(Diarrea/vacuna+) ≠ p(Diarrea/vacuna-)
Paso 2. Seleccionar la prueba estadística adecuada.
Dado que estamos estudiando dos variables categóricas, emplearemos la prueba
de Chi-cuadrado. Estamos comparando la frecuencia relativa de una variable
(diarrea) en dos grupos independientes de sujetos (expuestos o no a la vacuna) y
nos queda determinar el tamaño de las frecuencias esperadas. Más adelante nos
referiremos a esto, por el momento supongamos que no son pequeñas, por lo cual
podemos utilizar la prueba de Chi-cuadrado.
Esta prueba se puede utilizar para comparar 2 variables categóricas (ordinales o
nominales) que contengan cualquier cantidad de niveles. Se denominan niveles a
los diferentes valores que pueden tomar cada una de estas variables.
Paso 3. Seleccionar el nivel de significación para la prueba.
Continuaremos trabajando con nivel de significancia deseado de 5%, lo que
determina que el error α = 0.05.
Pasos 4 y 5. Seleccionar el valor crítico para dicho nivel de significancia y
realizar los cálculos de la prueba estadística seleccionada.
Pasaremos ahora a describir en mayor profundidad las bases matemáticas de esta
prueba. Su estudio, nos permitirán arribar a una mejor comprensión del
funcionamiento de esta prueba.
De manera similar a los casos anteriores, se trata de comparar dos conjuntos de
datos, un conjunto de datos será teórico y asumirá que H0 es verdadera. El otro
711*1017168
4314
3603*1017849
4314
711*3297543
4314
3603*32972754
4314
conjunto estará conformado por los datos observados. Se busca calcular “una
distancia relativa” entre los dos conjuntos de datos. Si dicha distancia supera el
“valor crítico” seleccionado en función del nivel de significancia deseado, entonces
habremos arribado a un valor “estadísticamente significativo” y estaremos en
condiciones de rechazar H0 y aceptar H1 como verdadera.
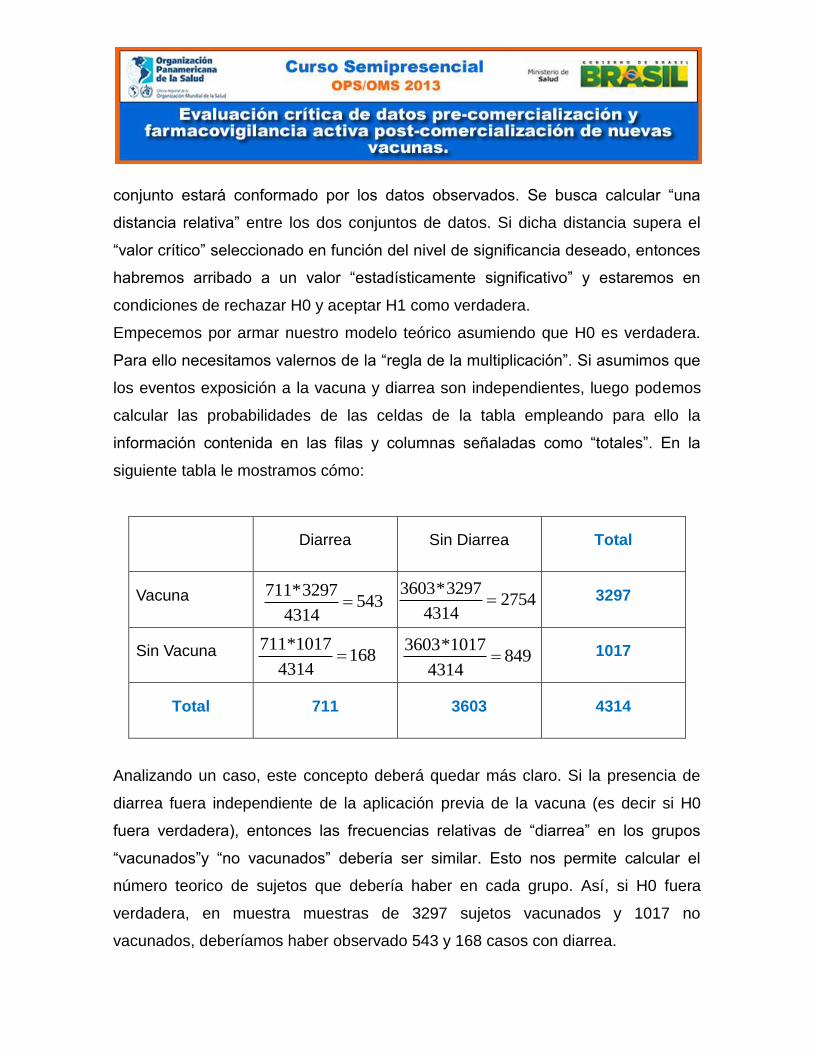
Empecemos por armar nuestro modelo teórico asumiendo que H0 es verdadera.
Para ello necesitamos valernos de la “regla de la multiplicación”. Si asumimos que
los eventos exposición a la vacuna y diarrea son independientes, luego podemos
calcular las probabilidades de las celdas de la tabla empleando para ello la
información contenida en las filas y columnas señaladas como “totales”. En la
siguiente tabla le mostramos cómo:
Diarrea Sin Diarrea Total
Vacuna
3297
Sin Vacuna
1017
Total 711 3603 4314
Analizando un caso, este concepto deberá quedar más claro. Si la presencia de
diarrea fuera independiente de la aplicación previa de la vacuna (es decir si H0
fuera verdadera), entonces las frecuencias relativas de “diarrea” en los grupos
“vacunados”y “no vacunados” debería ser similar. Esto nos permite calcular el
número teorico de sujetos que debería haber en cada grupo. Así, si H0 fuera
verdadera, en muestra muestras de 3297 sujetos vacunados y 1017 no
vacunados, deberíamos haber observado 543 y 168 casos con diarrea.
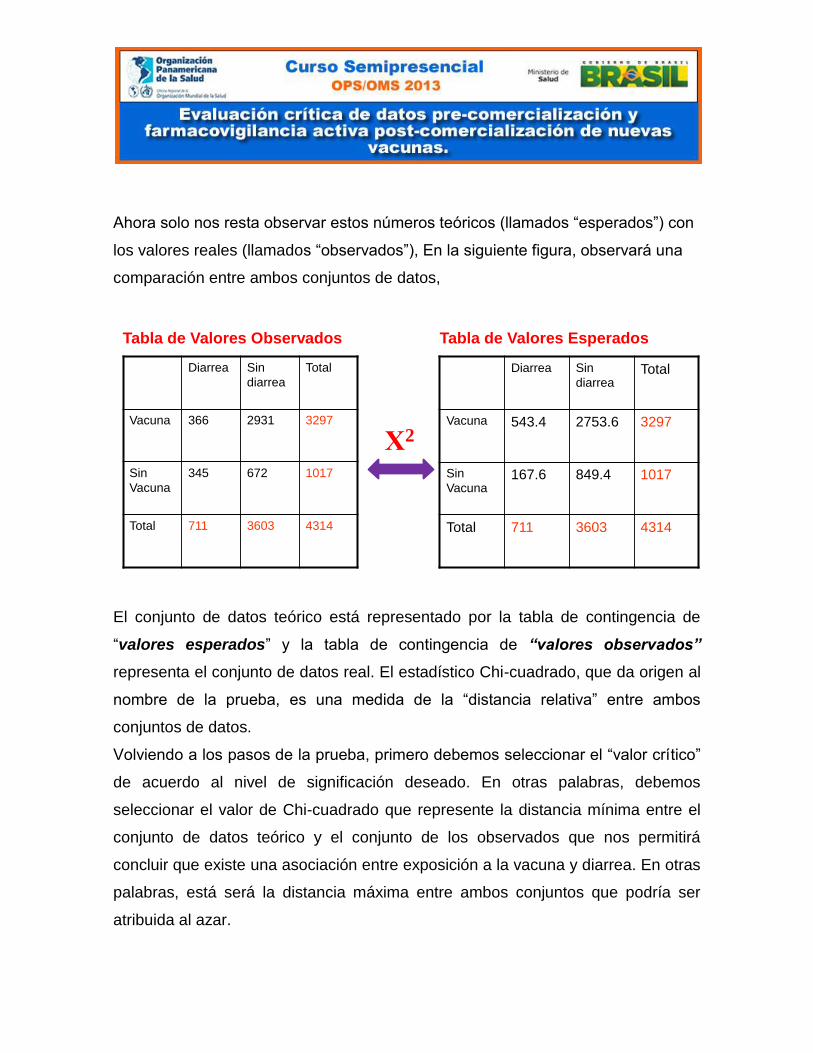
Ahora solo nos resta observar estos números teóricos (llamados “esperados”) con
los valores reales (llamados “observados”), En la siguiente figura, observará una
comparación entre ambos conjuntos de datos,
El conjunto de datos teórico está representado por la tabla de contingencia de
“valores esperados” y la tabla de contingencia de “valores observados”
representa el conjunto de datos real. El estadístico Chi-cuadrado, que da origen al
nombre de la prueba, es una medida de la “distancia relativa” entre ambos
conjuntos de datos.
Volviendo a los pasos de la prueba, primero debemos seleccionar el “valor crítico”
de acuerdo al nivel de significación deseado. En otras palabras, debemos
seleccionar el valor de Chi-cuadrado que represente la distancia mínima entre el
conjunto de datos teórico y el conjunto de los observados que nos permitirá
concluir que existe una asociación entre exposición a la vacuna y diarrea. En otras
palabras, está será la distancia máxima entre ambos conjuntos que podría ser
atribuida al azar.
Diarrea Sin
diarrea
Total
Vacuna 366 2931 3297
Sin
Vacuna
345 672 1017
Total 711 3603 4314
Diarrea Sin
diarreaTotal
Vacuna 543.4 2753.6 3297
Sin
Vacuna167.6 849.4 1017
Total 711 3603 4314
Χ2
Tabla de Valores Observados Tabla de Valores Esperados

Para la selección de este valor crítico nos valdremos de la Tabla de valores de la
distribución Chi-cuadrado que le mostramos en el Apéndice I. Para esto sólo
necesitamos conocer el valor que se calcula como el (número de columnas – 1) *
(número de filas – 1), lo que en este caso equivale a (2 – 1) * (2 – 1) = 1*1=1 y el
nivel de significancia deseado, que era 0.05. Así obtenemos que el valor crítico de
Chi-cuadrado = 3.84
Ahora sólo resta calcular el valor Chi-cuadrado para la distancia entre los dos
conjuntos de datos. Afortunadamente este valor es calculado frecuentemente por
todos los paquetes informáticos de estadística, así que nos contentaremos con
decirle que en este caso el valor de chi-cuadrado fue de 294.11.
Paso 6. Obtener la conclusión de la prueba estadística.
Ahora solo nos resta comparar los valores de chi-cuadrado crítico (3.84) con el
valor calculado (294.11). Dado que 294.11 > 3.84 concluimos que la probabilidad
de que H0 sea verdadera es < 5% (p<0.05), lo cual nos permite rechazarla y
aceptar H1 como verdadera. De esta manera podemos concluir que la
probabilidad de padecer diarrea habiendo recibido la vacuna no es similar a la
probabilidad de sufrirla no habiendo recibido la vacuna, por lo cual debe existir una
asociación entre la diarrea y la exposición a la vacuna, o lo que es lo mismo, que
estos eventos no son independientes.
Asunciones de la prueba de Chi-cuadrado.
La prueba de Chi-cuadrado puede ser aplicada a un gran número de
circunstancias, la única limitación es cuando se presentan frecuencias esperadas
bajas. Con frecuencias esperadas hacemos referencias a los valores de las celdas
en la tabla de valores esperados. Se sugiere que cuando se observe que el valor
de cualquier celda < 2 o cuando un 20% o más de las celdas tienen valores < 5, se

utilice otra prueba. Bajo estas condiciones el valor de Chi-cuadrado se infla
espuriamente, incrementando el error alfa en una magnitud desconocida. En otras
palabras, el riesgo de aceptar H1 siendo H0 verdadera se incrementará de una
manera no controlable.
En estas situaciones se recomienda el empleo de la prueba exacta de Fisher. Esta
prueba es menos potente que la de Chi-cuadrado pero no presenta sesgos con
frecuencias esperadas pequeñas. No entraremos en detalles sobre sus cálculos,
baste decir que sus resultados se interpretan de manera similar a los de la prueba
de Chi-cuadrado.
Estimado participante, hemos arribado al final del módulo!!!.
Esperamos que los textos lo hayan ayudado a comprender
mejor la forma en que los investigadores diseñan los
estudios y analizan sus resultados. Nos gustaría que
retuviera en la mente los siguientes conceptos
fundamentales:

Existen diversos diseños de estudios de investigación
clínica, siendo algunos de los más frecuentes los
estudios transversales, los de casos y controles, los de
cohortes y los ensayos clínicos aleatorizados
controlados.
Siempre se debe intentar utilizar los diseños que
presenten menor predisposición a los sesgos.
Los estudios clínicos aleatorizados controlados bien
diseñados y conducidos son los que tienen menor
probabilidad de sufrir sesgos.
Cuando estos no puedan utilizarse, deberán preferirse
los estudios de cohorte. Sin embargo, cuando el evento
en estudio ocurre con baja frecuencia o presenta una
latencia muy importante, deberá utilizarse un estudio de
casos y controles.
Los resultados de los estudios de investigación puede
analizarse mediante pruebas de confrontación de
hipótesis.
La mayor parte de las veces las variables cuantitativas
podrán ser utilizadas mediante una prueba “t” de
Student, mientras que las variables ordinales o
nominales podrán ser analizadas mediante la prueba de
Χ2.
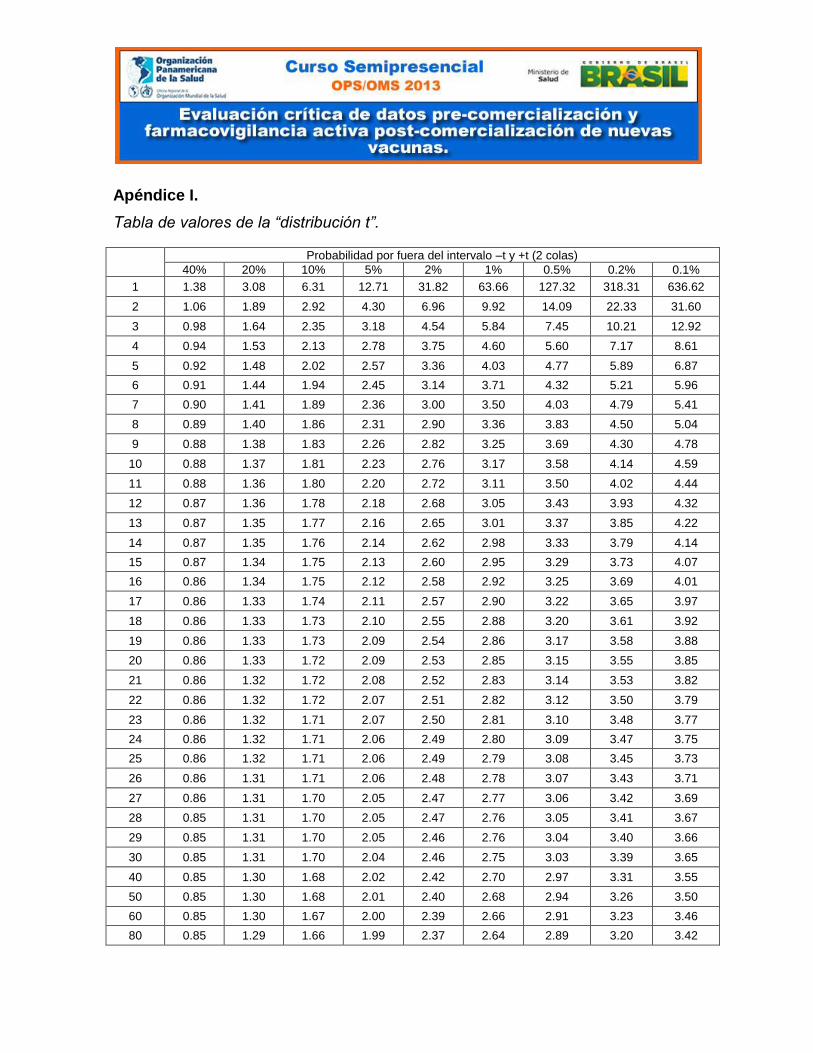
Apéndice I.
Tabla de valores de la “distribución t”.
Probabilidad por fuera del intervalo –t y +t (2 colas)
40% 20% 10% 5% 2% 1% 0.5% 0.2% 0.1%
1 1.38 3.08 6.31 12.71 31.82 63.66 127.32 318.31 636.62
2 1.06 1.89 2.92 4.30 6.96 9.92 14.09 22.33 31.60
3 0.98 1.64 2.35 3.18 4.54 5.84 7.45 10.21 12.92
4 0.94 1.53 2.13 2.78 3.75 4.60 5.60 7.17 8.61
5 0.92 1.48 2.02 2.57 3.36 4.03 4.77 5.89 6.87
6 0.91 1.44 1.94 2.45 3.14 3.71 4.32 5.21 5.96
7 0.90 1.41 1.89 2.36 3.00 3.50 4.03 4.79 5.41
8 0.89 1.40 1.86 2.31 2.90 3.36 3.83 4.50 5.04
9 0.88 1.38 1.83 2.26 2.82 3.25 3.69 4.30 4.78
10 0.88 1.37 1.81 2.23 2.76 3.17 3.58 4.14 4.59
11 0.88 1.36 1.80 2.20 2.72 3.11 3.50 4.02 4.44
12 0.87 1.36 1.78 2.18 2.68 3.05 3.43 3.93 4.32
13 0.87 1.35 1.77 2.16 2.65 3.01 3.37 3.85 4.22
14 0.87 1.35 1.76 2.14 2.62 2.98 3.33 3.79 4.14
15 0.87 1.34 1.75 2.13 2.60 2.95 3.29 3.73 4.07
16 0.86 1.34 1.75 2.12 2.58 2.92 3.25 3.69 4.01
17 0.86 1.33 1.74 2.11 2.57 2.90 3.22 3.65 3.97
18 0.86 1.33 1.73 2.10 2.55 2.88 3.20 3.61 3.92
19 0.86 1.33 1.73 2.09 2.54 2.86 3.17 3.58 3.88
20 0.86 1.33 1.72 2.09 2.53 2.85 3.15 3.55 3.85
21 0.86 1.32 1.72 2.08 2.52 2.83 3.14 3.53 3.82
22 0.86 1.32 1.72 2.07 2.51 2.82 3.12 3.50 3.79
23 0.86 1.32 1.71 2.07 2.50 2.81 3.10 3.48 3.77
24 0.86 1.32 1.71 2.06 2.49 2.80 3.09 3.47 3.75
25 0.86 1.32 1.71 2.06 2.49 2.79 3.08 3.45 3.73
26 0.86 1.31 1.71 2.06 2.48 2.78 3.07 3.43 3.71
27 0.86 1.31 1.70 2.05 2.47 2.77 3.06 3.42 3.69
28 0.85 1.31 1.70 2.05 2.47 2.76 3.05 3.41 3.67
29 0.85 1.31 1.70 2.05 2.46 2.76 3.04 3.40 3.66
30 0.85 1.31 1.70 2.04 2.46 2.75 3.03 3.39 3.65
40 0.85 1.30 1.68 2.02 2.42 2.70 2.97 3.31 3.55
50 0.85 1.30 1.68 2.01 2.40 2.68 2.94 3.26 3.50
60 0.85 1.30 1.67 2.00 2.39 2.66 2.91 3.23 3.46
80 0.85 1.29 1.66 1.99 2.37 2.64 2.89 3.20 3.42
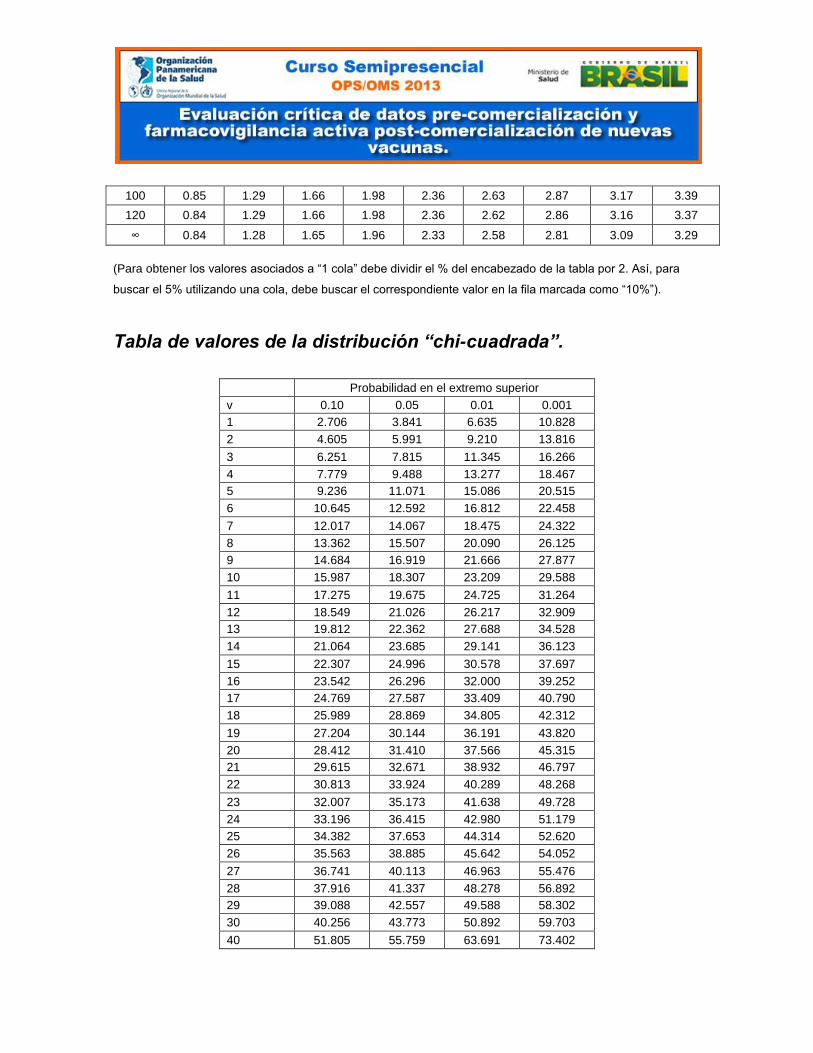
100 0.85 1.29 1.66 1.98 2.36 2.63 2.87 3.17 3.39
120 0.84 1.29 1.66 1.98 2.36 2.62 2.86 3.16 3.37
∞ 0.84 1.28 1.65 1.96 2.33 2.58 2.81 3.09 3.29
(Para obtener los valores asociados a “1 cola” debe dividir el % del encabezado de la tabla por 2. Así, para
buscar el 5% utilizando una cola, debe buscar el correspondiente valor en la fila marcada como “10%”).
Tabla de valores de la distribución “chi-cuadrada”.
Probabilidad en el extremo superior
v 0.10 0.05 0.01 0.001
1 2.706 3.841 6.635 10.828
2 4.605 5.991 9.210 13.816
3 6.251 7.815 11.345 16.266
4 7.779 9.488 13.277 18.467
5 9.236 11.071 15.086 20.515
6 10.645 12.592 16.812 22.458
7 12.017 14.067 18.475 24.322
8 13.362 15.507 20.090 26.125
9 14.684 16.919 21.666 27.877
10 15.987 18.307 23.209 29.588
11 17.275 19.675 24.725 31.264
12 18.549 21.026 26.217 32.909
13 19.812 22.362 27.688 34.528
14 21.064 23.685 29.141 36.123
15 22.307 24.996 30.578 37.697
16 23.542 26.296 32.000 39.252
17 24.769 27.587 33.409 40.790
18 25.989 28.869 34.805 42.312
19 27.204 30.144 36.191 43.820
20 28.412 31.410 37.566 45.315
21 29.615 32.671 38.932 46.797
22 30.813 33.924 40.289 48.268
23 32.007 35.173 41.638 49.728
24 33.196 36.415 42.980 51.179
25 34.382 37.653 44.314 52.620
26 35.563 38.885 45.642 54.052
27 36.741 40.113 46.963 55.476
28 37.916 41.337 48.278 56.892
29 39.088 42.557 49.588 58.302
30 40.256 43.773 50.892 59.703
40 51.805 55.759 63.691 73.402
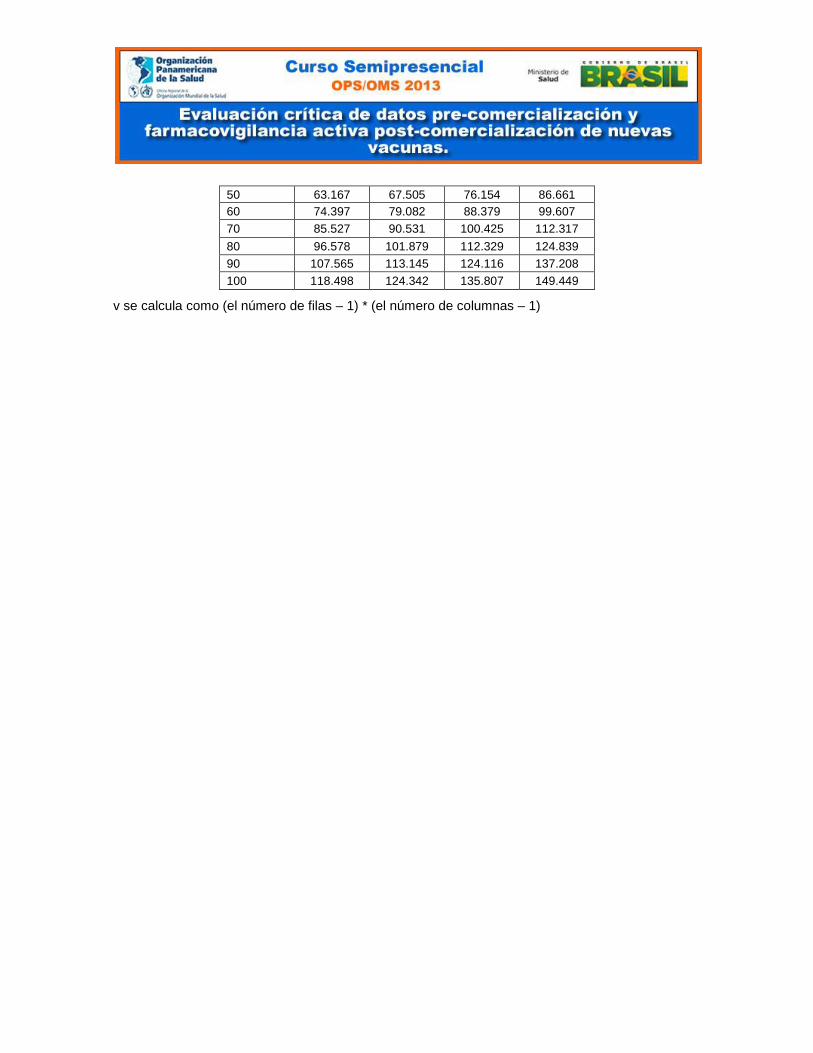
50 63.167 67.505 76.154 86.661
60 74.397 79.082 88.379 99.607
70 85.527 90.531 100.425 112.317
80 96.578 101.879 112.329 124.839
90 107.565 113.145 124.116 137.208
100 118.498 124.342 135.807 149.449
v se calcula como (el número de filas – 1) * (el número de columnas – 1)


















