· ∝ ii TABLA DE CONTENIDO...
132
Probabilidad Libro de Texto Maria de la Luz Torres Valles Instituto Tecnológico de Durango
Transcript of · ∝ ii TABLA DE CONTENIDO...

Probabilidad Libro de Texto
Maria de la Luz Torres Valles
Instituto Tecnológico de Durango

µλτϖ ii
TABLA DE CONTENIDO INTRODUCCIÓN.................................................................................................................................................... V 1. ESTADÍSTICA DESCRIPTIVA......................................................................................................................... 6
1.1 INTRODUCCIÓN, NOTACIÓN SUMATORIA ................................................................................................ 6 1.1.1 Antecedentes de la Probabilidad ........................................................................................................ 6 1.1.2 Antecedentes de la Estadística............................................................................................................ 8 1.1.3 Notación Sumatoria.......................................................................................................................... 10
1.1.3.1 Propiedades de las Sumatorias ................................................................................................................................. 11 1.2 DATOS NO AGRUPADOS ......................................................................................................................... 15
1.2.1 Medidas de Tendencia Central para Datos No Agrupados ............................................................. 16 1.2.1.1 Media Aritmética (µ o X ) ............................................................................................................................ 17 1.2.1.2 Mediana (Med) ................................................................................................................................................ 18 1.2.1.3 Moda (Mo) ....................................................................................................................................................... 19 1.2.1.4 Medidas de tendencia central con menor incidencia..................................................................................... 20
1.2.1.4.1 Media Geométrica...................................................................................................................................... 20 1.2.1.4.2 Media Armónica ........................................................................................................................................ 20 1.2.1.4.3 Media Aritmética Ponderada o Promedio Ponderado ............................................................................. 20
1.2.2 Medidas de Dispersión...................................................................................................................... 21 1.2.2.1 Desviación Media o Promedio de Desviación (DM). ................................................................................... 22 1.2.2.2 Desviación Típica o Estándar (σ)................................................................................................................... 23 1.2.2.3 Varianza. .......................................................................................................................................................... 23
1.3 DATOS AGRUPADOS .............................................................................................................................. 25 1.3.1 Medidas de Tendencia Central para Datos Agrupados ................................................................... 28
1.3.1.1 Media Aritmética (µ o X ) ............................................................................................................................ 30 1.3.1.2 Mediana (Med) ................................................................................................................................................ 31 1.3.1.3 Moda (Mo) ....................................................................................................................................................... 33
1.3.2 Medidas de Dispersión para Datos Agrupados ................................................................................ 34 1.3.2.1 Desviación Media o Promedio de Desviación (DM) .................................................................................... 34 1.3.2.2 Desviación Típica o Estándar (σ)................................................................................................................... 35 1.3.2.3 Varianza ........................................................................................................................................................... 36
1.4 REPRESENTACIÓN DE UN CONJUNTO DADO DE DATOS, MEDIANTE UN HISTOGRAMA, POLÍGONO DE FRECUENCIA, OJIVAS, ETC. .................................................................................................................................. 36
1.4.1 Histograma o histograma de Frecuencia......................................................................................... 39 1.4.2 Polígono de frecuencia ..................................................................................................................... 40 1.4.3 Ojivas................................................................................................................................................. 40
2 FUNDAMENTOS DE PROBABILIDAD.................................................................................................... 42 2.1 CONJUNTOS Y TÉCNICAS DE CONTEO. ................................................................................................. 42
2.1.1 Teoría de Conjuntos ......................................................................................................................... 42 2.1.1.1 Definición ........................................................................................................................................................ 42 2.1.1.2 Características.................................................................................................................................................. 43 2.1.1.3 Representación................................................................................................................................................. 44 2.1.1.4 Relaciones ........................................................................................................................................................ 44
2.1.1.4.1 Igualdad ...................................................................................................................................................... 45 2.1.1.4.2 Inclusión ..................................................................................................................................................... 45
2.1.1.5 Operaciones ..................................................................................................................................................... 45 2.1.1.6 Leyes de Conjuntos ......................................................................................................................................... 48
2.1.2 Técnicas Conteo................................................................................................................................ 49 2.1.2.1 Permutaciones.................................................................................................................................................. 49
2.1.2.1.1 Permutación Ordinaria............................................................................................................................... 50 2.1.2.1.2 Permutación con Sustitución..................................................................................................................... 51 2.1.2.1.3 Permutación Circular ................................................................................................................................. 52 2.1.2.1.4 Permutación con Repetición ..................................................................................................................... 52
2.1.2.2 Combinaciones ................................................................................................................................................ 53 2.1.2.3 Diagrama de Árbol .......................................................................................................................................... 54

µλτϖ iii
2.1.2.4 Particiones Ordenadas..................................................................................................................................... 55 2.1.2.5 Diagrama para la Resolución de Problemas de Técnicas de Conteo ........................................................... 57
2.2 CONCEPTO CLÁSICO Y COMO FRECUENCIA RELATIVA ........................................................................ 58 2.3 ESPACIO MUESTRAL Y EVENTOS ........................................................................................................... 58 2.4 AXIOMAS Y TEOREMAS.......................................................................................................................... 59
2.4.1 Axiomas de Probabilidad.................................................................................................................. 59 2.4.2 Teoremas de Probabilidad ................................................................................................................ 60
2.5 ESPACIO FINITO EQUIPROBABLE........................................................................................................... 61 2.6 PROBABILIDAD CONDICIONAL E INDEPENDENCIA ................................................................................ 62
2.6.1 Probabilidad Condicional................................................................................................................. 62 2.7 TEOREMA DE BAYES.............................................................................................................................. 64
3 MODELOS ANALÍTICOS DE FENÓMENOS ALEATORIOS DISCRETOS ...................................... 67 3.1 DEFINICIÓN DE VARIABLE ALEATORIA DISCRETA................................................................................ 67 3.2 FUNCIÓN DE PROBABILIDAD Y DE DISTRIBUCIÓN, VALOR ESPERADO, VARIANZA Y DESVIACIÓN ESTÁNDAR............................................................................................................................................................. 68
3.2.1 Función de Probabilidad .................................................................................................................. 68 3.2.2 Función de Distribución................................................................................................................... 68 3.2.3 Medidas de Tendencia Central ......................................................................................................... 68
3.2.3.1 Valor esperado o media................................................................................................................................... 68 3.2.3.2 Moda................................................................................................................................................................. 68 3.2.3.3 Mediana............................................................................................................................................................ 69
3.2.4 Medidas de Variación ....................................................................................................................... 69 3.2.4.1 Varianza ........................................................................................................................................................... 69 3.2.4.2 Desviación Típica o Estándar ......................................................................................................................... 69
3.3 DISTRIBUCIÓN BERNOULLI ................................................................................................................... 69 3.4 DISTRIBUCIÓN BINOMIAL. .................................................................................................................... 70 3.5 DISTRIBUCIÓN HIPERGEOMÉTRICA...................................................................................................... 73
3.5.1 Aproximación de la hipergeométrica por la Binomial .................................................................... 76 3.6 DISTRIBUCIÓN GEOMÉTRICA................................................................................................................ 76 3.7 DISTRIBUCIÓN MULTINONIAL............................................................................................................... 78 3.8 DISTRIBUCIÓN DE POISSON ................................................................................................................... 79
4 MODELOS ANALÍTICOS DE FENÓMENOS ALEATORIOS CONTINUOS ..................................... 83 4.1 DEFINICIÓN DE VARIABLE ALEATORIA CONTÍNUA. .............................................................................. 83 4.2 FUNCIÓN DE DENSIDAD Y ACUMULATIVA. ............................................................................................ 84 4.3 VALOR ESPERADO, VARIANZA Y DESVIACIÓN ESTÁNDAR. ................................................................... 84
4.3.1 Medidas de Tendencia Central: ....................................................................................................... 84 4.3.1.1 Valor esperado o media de una V.A.C........................................................................................................... 84 4.3.1.2 Moda de una V.A.C......................................................................................................................................... 84 4.3.1.3 Mediana de una V.A.C.................................................................................................................................... 85
4.3.2 Medidas de Variación:...................................................................................................................... 85 4.3.2.1 Varianza de una V.A.C. .................................................................................................................................. 85 4.3.2.2 Desviación Típica o Estándar de una V.A.C. ................................................................................................ 85
4.4 DISTRIBUCIÓN UNIFORME Y EXPONENCIAL......................................................................................... 85 4.4.1 Distribución Uniforme...................................................................................................................... 85 4.4.2 Distribución Exponencial................................................................................................................. 86
4.5 DISTRIBUCIÓN NORMAL........................................................................................................................ 88 4.5.1 Aproximación de la Binomial a la Normal. ..................................................................................... 92
4.6 TEOREMA DE CHEBYSHEV. ................................................................................................................... 94 5 REGRESIÓN Y CORRELACIÓN SIMPLE .............................................................................................. 97
5.1 INTRODUCCIÓN. ..................................................................................................................................... 97 5.1.1 Tabla de Frecuencia Absoluta para Variables Bidimensionales. ................................................... 98 5.1.2 Tabla de Doble Entrada.................................................................................................................... 99 5.1.3 Distribuciones Marginales. ............................................................................................................ 100 5.1.4 Tabla de Frecuencia Relativa para Variables Bidimensionales. .................................................. 100 5.1.5 Funciones estadísticas: media, varianza, desviación y covarianza ............................................... 101

µλτϖ iv
5.1.6 Diagrama de Dispersión o Nube de Puntos ................................................................................... 103 5.2 REGRESIÓN LINEAL SIMPLE Y CURVILÍNEA. ....................................................................................... 107
5.2.1 Distinguir entre variable dependiente e independiente. ................................................................ 107 5.2.2 Diferencia entre Dependencia Funcional y Dependencia Estadística.......................................... 108 5.2.3 Definir ecuación de regresión y cuál es su aplicación. ................................................................. 110 5.2.4 Método de Mínimos Cuadrados ..................................................................................................... 111 5.2.5 Consideraciones sobre la recta de regresión.................................................................................. 116
5.3 CORRELACIÓN ..................................................................................................................................... 116 5.3.1 Coeficiente de Correlación de Pearson .......................................................................................... 117
5.4 EJERCICIO INTEGRAL.......................................................................................................................... 120 ANEXOS ................................................................................................................................................................ 127 REFERENCIAS BIBLIOGRÁFICAS................................................................................................................. 131

µλτϖ v
Introducción
En este libro se tratan los temas que contiene el programa de estudios de la materia “Probabilidad” en la especialidad de Ingeniería Industrial del Sistema de Institutos Tecnológicos, fue realizado con la finalidad de que sirva como auxiliar en la preparación de los alumnos de Ingeniería Industrial, además de que también puede ser consultado por los alumnos que estén cursando la materia de Probabilidad en cualquiera de las especialidades que ofrece el sistema. El Libro está dividido en 5 capítulos, de acuerdo al número de unidades que componen el programa de estudios, El tema central del primer capítulo es la Estadística Descriptiva en este se abordan temas tales como: antecedentes de la probabilidad y la estadística, sumatorias y Manejo de Datos no Agrupados y Datos Agrupados a través del cálculo de las medidas de tendencia central, de dispersión y la representación gráfica de los datos. En el segundo capítulo denominado Fundamentos de Probabilidad se tratan los siguientes temas: Conjuntos y Técnicas de Conteo, el concepto clásico y como frecuencia relativa de la probabilidad, espacios muestrales y eventos, axiomas y teoremas de la probabilidad, espacio finito equiprobable, probabilidad condicional e independencia y teorema de Bayes. La información que contiene el tercer capítulo se relaciona con los Modelos Analíticos de Fenómenos Aleatorios Discretos; además de la definición de variable aleatoria discreta, la función de probabilidad y de distribución, valor esperado, varianza y desviación estándar se estudian las distribuciones: Bernoulli, Binomial, Hipergeométrica, Geométrica, Multinomial y Poisson. Los temas relacionados con los Modelos Analíticos de Fenómenos Aleatorios Continuos tales como: definición de variable aleatoria continua, función de densidad y acumulativa, valor esperado, varianza y desviación estándar así como las distribuciones Uniforme y Exponencial, Distribución Normal y Teorema de Chebyshev, se tratan en el capítulo cuatro. Corresponde al capítulo cinco, el estudio de temas relacionados con la Regresión Lineal y Correlación Simple.
Cada uno de los temas están abordados de acuerdo al punto de vista de la autora buscando siempre simplificar su comprensión; el criterio utilizado en la elaboración del libro fue abordar primero la parte conceptual del tema a tratar, luego las ecuaciones cuando así se requiere y se cierra el tema con ejemplos que contengan aparte del enunciado del ejercicio, las formulas a utilizar, el desarrollo paso a paso utilizando tablas y gráficas (si se requieren para la mejor comprensión) en las que se resaltan la información que se va generando con color amarillo y/o verde, hasta llegar al resultado. El logro de cualquier objetivo requiere de esfuerzo, se espera que este libro sirva de apoyo.
¡Bienvenidos al maravilloso mundo de la probabilidad!

EEssttaaddííssttiiccaaDDeessccrriippttiivvaa
1.1 Introducción, notación sumatoria 1.2 Datos no agrupados.
1.2.1 Medidas de tendencia central y de posición. 1.2.2 Medidas de dispersión
1.3 Datos agrupados 1.3.1 Tabla de frecuencia 1.3.2 Medidas de tendencia central y de posición 1.3.3 Medidas de dispersión
1.4 Representación de un conjunto dado de datos, mediante un histograma, polígono de frecuencia, ojivas, etc.
1. ESTADÍSTICA DESCRIPTIVA 11..11 IInnttrroodduucccciióónn,, nnoottaacciióónn ssuummaattoorriiaa
11..11..11 AAnntteecceeddeenntteess ddee llaa PPrroobbaabbiilliiddaadd
La Teoría de la Probabilidad, es la rama de las matemáticas que se ocupa de medir o determinar cuantitativamente la posibilidad de que ocurra un determinado suceso. Si queremos saber lo que sucederá mañana o la semana que entra, habrá que contemplar muchas probabilidades; lo que hace la teoría de la probabilidad es decirnos, esto es lo más probable o esto es lo que sucede más frecuentemente o hay una tendencia hacia aquello. La Probabilidad está basada en las técnicas de conteo y es fundamento necesario de la Estadística.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 7
Aunque algunos matemáticos como Gerolamo Cardano en el siglo XVI, habían hecho algunas contribuciones al desarrollo de la probabilidad, la Teoría de la probabilidad se atribuye a los matemáticos franceses del siglo XVII Blaise Pascal y Pierre de Fermat.
“Pascal tenía un colega que era jugador empedernido, un día su colega le dijo que quería resolver una duda que tenía sobre probabilidad y juegos de azar, el problema que llamó la atención de Pascal y Fermat, trataba sobre un juego de dados con un final en disputa, supongan que dos personas juegan dados, están a la mitad del juego y súbitamente deben abandonarlo, uno de ellos tiene mas puntos que el otro ¿Cómo dividirán el dinero de las apuestas de un modo justo? Para resolver el problema hay que mirar el futuro, ¿qué habría sucedido si hubieran podido terminar el juego? En un juego de cartas, Pascal y Fermat imaginaron un juego de dados de cinco turnos, el primero en ganar tres tiros, ganaría el juego, en su escenario, imaginaron que Fermat iba ganando dos tiros a uno.
Fermat solo necesitaba otro tiro para ganar, así que pensaron en todos los finales posibles: 1. Si Fermat ganaba los tiros 4 y 5, ganaba el juego, ya que habría ganado al
menos 3 tiros de 5. 2. Si Fermat ganaba el cuarto tiro y perdía el quinto, ganaba otra vez porque
habría ganado 3 tiros de 5. 3. Si Fermat perdía el cuarto tiro y ganaba el quinto, seguía ganando. 4. La única forma en que podía perder sería perdiendo los dos últimos tiros. Dadas tales posibilidades, Fermat y Pascal razonaron correctamente que las probabilidades eran 3 a 1 a favor de Fermat, por lo tanto, Fermat debería quedarse con ¾ partes del dinero y pascal con ¼, los matemáticos descubrieron que una leve ventaja aumentaría mucho las probabilidades de ganar de un jugador, más de 300 años después, los casinos sacan provecho de las leyes de la probabilidad. “1
Como ven, la Teoría de la Probabilidad, se desarrolló para entender los juegos de azar, Fermat y Pascal se convencieron de que el juego tiene mucho que ver con el pensamiento matemático y lógico. Tal vez Fermat y Pascal nunca imaginaron que
1 Vídeo Las Probabilidades Diarias
Jugador 1 2 3 4 5 Fermat
Pascal

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 8
aparte del juego, la Teoría de la Probabilidad se puede aplicar en cualquier actividad de la vida cotidiana, en esto radica su verdadera importancia. 11..11..22 AAnntteecceeddeenntteess ddee llaa EEssttaaddííssttiiccaa
La Estadística se encarga de la recolección, procesamiento, análisis e interpretación de datos numéricos que ayuden a resolver problemas como el diseño de experimentos y la toma de decisiones. Existen algunas representaciones gráficas y otros símbolos hechos por las antiguas civilizaciones sobre rocas, pieles, paredes de cuevas etc., relacionados con el conteo de personas, animales o cosas que pueden ser consideradas como formas sencillas de estadística; también existen registros de agricultura y comercio de los babilonios que datan del año 3000 a.C.; de los egipcios en el siglo XXXI a.C. sobre población; de los Chinos, de los Griegos, sin embargo, el primer estudio de población que llama la atención es el realizado en el año 1066 por encargo del William el conquistador, rey de Inglaterra, el país fue dividido en pequeñas áreas y se registro en número de personas por cada zona y el tipo de productos que se producían ahí, estos datos fueron registrados en un libro llamado “El Libro del Juicio Final” (Domesday Book), sin embargo no pasó de ser solo una colección de datos hasta a mediados de siglo XVII en la que se conoció el verdadero poder del libro al efectuarse un análisis e interpretación de los datos por parte de John Graunt tendero de profesión quién determinó a partir de los datos registrados, correlacionado bautismos con nacimientos, nacimientos con mujeres en edad de criar, número de mujeres con número de familias y su tamaño, que en ese tiempo, la población de Inglaterra no era de 2 millones como se especulaba sino que a era solo una quinta parte, 384,000 personas aproximadamente. Muchos expertos actuales creen que la estimación de Graunt era muy cercana a la realidad, al sacar conclusiones de los datos, Graunt realizó el análisis estadístico moderno. En la actualidad, la Estadística se utiliza como una poderosa herramienta en cualquier rama del conocimiento. En Ingeniería se puede utilizar en el control de calidad de un producto; en Medicina para conocer la eficacia de un nuevo medicamento; en el Deporte para medir los logros de los deportistas; en Educación para mostrar la eficacia de los métodos de estudio; en el Comercio para surtir productos de temporada; en Economía Doméstica para controlar el gasto familiar. Sin duda sería demasiado extenso ejemplificar la utilización de la estadística también en: Biología, Economía, Política, Psicología, Agricultura, Física, Química, Opinión Pública, Trabajo Social, etc.
Actualmente la Estadística tiene dos ramificaciones: Estadística Descriptiva y Estadística Inferencial. La Estadística Descriptiva, la cual es motivo de estudio en este capítulo, trabaja con todos los individuos de la población que cumplan con una característica previamente especificada. Tiene como finalidad recolectar información, analizarla, elaborarla y simplificarla lo necesario para que pueda ser interpretada cómoda y rápidamente, y por tanto, pueda utilizarse eficazmente para el fin que se desee, se recomienda realizar los siguientes pasos:

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 9
1. Determinar la característica del individuo se desea estudiar. 2. Recopilar la información de cada individuo que cumple con la característica
definida (se pueden utilizar entrevistas, mediciones, sondeos, encuestas, etc.). 3. Previa clasificación, se elaboran tablas de frecuencia. 4. A partir de las tablas, se representan los datos en forma gráfica (histogramas,
polígonos, ojivas). 5. Obtención de parámetros estadísticos (medidas de tendencia centra, y de
dispersión). La Estadística Inferencial, contrario a la Estadística Descriptiva, solo trabaja con una muestra de la población, y a partir de los resultados que se obtienen en esta, se hacen inferencias sobre toda la población, en esta es importante la selección de la muestra, debe ser representativa de la población para evitar inferencias erróneas y tener un mayor grado de certidumbre. No debemos perder de vista que la recopilación de datos por si sola, no nos dice nada, solo estaremos haciendo estadística con “e” minúscula, si realmente queremos hacer Estadística con “E” mayúscula, los datos se deben someter a un proceso de análisis e interpretación, que nos lleve a la toma de decisiones, fundamentadas en la Teoría de la Probabilidad para alcanzar la mayor posibilidad de éxito.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 10
11..11..33 NNoottaacciióónn SSuummaattoorriiaa
Para determinar si un elevador con capacidad de 400 Kg. soporta el peso de 6 personas que desean abordarlo, ¿usted que haría? Sin duda, optaría por sumar los pesos de las 6 personas para conocer si el peso total no excede la capacidad del elevador. Bien, ahora imaginemos que los pesos de las 6 personas son:
Persona Peso en Kg.1 80 2 63 3 75 4 52 5 47 6 68
Nuestro conjunto de observaciones 80, 63, 75, 52, 47, 68, está asociado a la variable peso a la cual llamaremos “X”. La letra i la utilizaremos para indicar el número de observación (en este ejemplo, el número de la persona a la que corresponde el peso, ejemplo: la cuarta persona pesa 52 Kg.). Al total de observaciones (número de personas que desean abordar el elevador) le llamaremos n.
La letra S del alfabeto griego (Σ), nos sirve para representar la sumatoria de los valores. De acuerdo con lo anterior, nuestro conjunto de observaciones se representa de la siguiente manera:
i X1 80 2 63 3 75 4 52 5 47 6 68
Ahora bien, dado un conjunto de observaciones de alguna variable representada por X1, X2,..., Xn, podemos expresar su suma X1 + X2 +...+Xn en forma abreviada como:
∑=
n
iiX
1

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 11
Esto se lee “suma de los Xi desde i igual a 1 hasta “n” en donde:
3856847527563806543
6
121 =+++++=+++++=∑
=
XXXXXXXi
i
1.1.3.1 Propiedades de las Sumatorias 1.- Si c es una constante cualquiera que multiplica a la variable X, entonces:
i
n
ii
n
iXccX
11 ==Σ=Σ
Demostración:
( )ni
n
i
ni
n
i
XXXcXc
cXcXcXcX
+++=Σ=
+++=Σ
=
=
...
...
211
211
Ejemplo: Un centro comercial tienen la siguiente promoción, en cada compra que usted realice durante el mes, le proporcionan una tarjeta para que la raspe y conozca el número de puntos a los que se hizo acreedor, el número de puntos será multiplicado por 4 y son acumulables; al finalizar el mes, de acuerdo al número de puntos obtenidos le darán un obsequio. Si en total realizó 5 compras y obtuvo los siguientes puntos, ¿cuántos puntos acumuló al final del mes?
i X1 -3 2 53 14 75 0
Solución: c = 4
40445
1
5
1=Σ=Σ
== iiiiXX Porque
4002842012
)0(4)7(3)1(4)5(4)3(445
1
=++++−=
++++−=Σ= ii
X
40)10(4
)07153(45
1
==
++++−=Σ= ii
X

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 12
2. Si X es una constante, entonces nXX i
n
i=Σ
=1
Demostración: Si Xi =1 en la propiedad anterior, entonces
414
4111114
1
4
1
=×=
=+++==∑∑==
i
iii
nX
X
Ejemplo: Si usted cursa actualmente 6 materias y todas tienen un valor de 8 créditos, ¿cuantos créditos está cursando? Solución:
4888888886
1=+++++=Σ
=io también 48)8(68
6
1==Σ
=i
3. Si tenemos 2 o más conjuntos de observaciones del mismo tamaño que deseamos sumar y estas son acumulables entonces:
i
n
ii
n
ii
n
iiii
n
iZYXZYX
1111)(
====Σ+Σ+Σ=++Σ
Demostración:
)...()...()...(
)(...)()()(
212121
111
2221111
nnn
i
n
ii
n
ii
n
i
nnniii
n
i
ZZZYYYXXX
ZYX
ZYXZYXZYXZYX
+++++++++++=
Σ+Σ+Σ=
+++++++++=++Σ
===
=
Ejemplo: 4 Alumnos formarán parte de un equipo deportivo, deben ir a que les tomen medidas para que les confeccionen el uniforme (pants(X), chamarra (Y) y shorts (Z), los tres son de la misma tela. De acuerdo a la siguiente tabla, ¿Cuanta tela deberá comprar la modista?
i X Y Z1 1.5 1.8 .75 2 1.7 2 .85 3 1.65 1.95 .8 4 1.55 1.85 .75

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 13
Solución:
5.17
)15.4()40.4()55.4()05.4(
)75.85.155.1()8.95.165.1()85.27.1()75.8.15.1()(4
1
=+++=
+++++++++++=++Σ= iiii
ZYX
5.1715.36.74.6
)75.8.85.75(.)85.195.128.1()55.165.17.15.1(4
1
4
1
4
1
=++=
+++++++++++=Σ+Σ+Σ=== iiiiii
ZYX
4. Si c es una constante que se suma a Xi entonces ncXcX i
n
ii
n
i+Σ=+Σ
== 11)(
Demostración:
∑∑∑∑====
+=+=+4
1111)(
ii
n
i
n
ii
n
ii ncXcXcX
Ejemplo: Por cada venta de productos con un valor mayor o igual a $300.00, el empleado de una tienda, se quedará con $50.00 de comisión. Al final del día ¿cuánto deberá reportar a caja?
i X1 420.00 2 375.00 3 530.00
Solución: c = $50.00 que deberá restar a cada precio
11751501325)50(3)530375420()(
11751501325)505050()530375420(
1175480325370)50530()50375()50420()(
4
1
3
1
3
1
3
1
=−=−++=−
=+=++−++=−
=++=−+−+−=−
∑
∑∑
∑
=
==
=
ii
iii
ii
cnX
cX
cX

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 14
Ejemplo: Dados X Y4 65 48 56 8
DETERMINAR:
a) xii
23
1=Σ Solución: 105642516854 2222
3
1=++=++=Σ
= iiX
b) 24
1)3( +Σ
= iiX Solución:
315811216449
)36()38()35()34()3( 222224
1
=+++=
+++++++=+Σ= ii
X
c) 324
1+Σ
= iiX Solución:
14431413)36642516(
3)6854(3 222224
1
=+=++++=
++++=+Σ=
ii
X
d) iiiYX
4
1=Σ Solución:
132)48402024
)8*6()5*8()4*5()6*4(4
1
=+++=
+++=Σ= iii
YX

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 15
11..22 DDaattooss nnoo AAggrruuppaaddooss
Cuando la cantidad de datos es mínima y por consecuencia su manejo es sencillo, permite fácilmente la obtención resultados representativos, se trabaja con la totalidad de los datos (x) es decir, con datos no agrupados. Contar con un grupo de datos agrupados o no agrupados por si mismo no nos dice nada, si queremos conocer cual es la tendencia de los datos, o que tan distante podemos esperar un dato con respecto a la mayoría, debemos calcular estadísticos que nos indiquen por ejemplo el valor promedio o la desviación estándar, estos estadísticos son identificados con letras griegas si fue calculado a partir de la totalidad de los datos que forman la población y con letras latinas si el estadístico fue calculado solo con una muestra de la población. Cabe señalar que si los valores de la muestra son enteros y en caso de que los resultados obtenidos de los estadísticos sean con decimales, estos deberán aproximarse al entero más cercano. Ejemplo: A un grupo de 25 alumnos que cursan la carrera de Ingeniería en Sistemas,
se les preguntó la cantidad de dinero que gastan diariamente con el propósito de saber: ¿Cuánto gasta en promedio diariamente un alumno?
Se recomienda seguir los siguientes pasos: 1. Toma o Recolección de Datos: Refiere a la obtención de una colección de datos
que no han sido ordenados numéricamente, es decir, es la selección de una muestra aleatoria de la población de interés.
Para este ejemplo, se recopilaron 25 datos que corresponden a la cantidad de dinero que gastan diario 25 alumnos de la especialidad de Ingeniería en sistemas. Por lo tanto, n = 25.
20 10 35 40 20 35 15 45 20 25 15 30 20 30 20 25 25 35 20 10 25 15 20 25 35
2. Ordenación de Datos: Es la colocación de los números tomados en orden creciente o decreciente de magnitud. (leer la siguiente tabla de arriba hacia abajo y de izquierda a derecha )
10 15 20 20 25 25 30 35 45 10 15 20 20 25 25 35 3515 20 20 20 25 30 35 40

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 16
3. Elaboración de la Tabla de Distribución de Frecuencia: Es la tabla que se forma por 3 columnas, La primera de ellas, representa el número de clase (k); la segunda (x), indica el conjunto de valores que intervienen en la muestra, también se le conoce como conjunto imagen. En la tercera columna, se registra la frecuencia (f),es decir, cuantos valores x existen en la muestra. La sumatoria de f debe ser igual a n (Σ(f) = n).
Tabla de Distribución de Frecuencia
k x f1 10 22 15 33 20 74 25 55 30 26 35 47 40 18 45 1
n = 25
8. Cálculo de las Medidas de Tendencia Central: Las más comunes son: Media Aritmética, Mediana y Moda; existen otras con menos incidencia aunque no por ello menos importantes como son: Media Geométrica, Media Armónica y Media Ponderada, el cálculo de estas se describe en el apartado 1.2.1.
9. Calculo de las Medidas de Dispersión: Se les conoce también como medidas de
variación y en el apartado 1.2.2 se estudiarán la Desviación Media, la Desviación Estándar y la Varianza.
11..22..11 MMeeddiiddaass ddee TTeennddeenncciiaa CCeennttrraall ppaarraa DDaattooss NNoo AAggrruuppaaddooss
Se les conoce también como medidas de centralización, se emplean para indicar un valor que tiende a ser el más representativo de un conjunto de números.
Las medidas de mayor importancia son: La Media Aritmética, la Mediana y la Moda. Aunque se emplean con menor incidencia también están: la media geométrica, la media armónica y la media ponderada.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 17
1.2.1.1 Media Aritmética (µ o X )
Representa el valor promedio de un conjunto de datos y se obtiene a partir de la sumatoria del conjunto de valores que forman la población o la muestra divididos entre el total de ellos.
n
Xn
ii∑
== 1µ
Por lo tanto: µ =20+10+35+40+20+35+15+45+20+25+15+30+20+30+20+25+25+35+20+10+25+15+20+25+35
25
256.2425
6151 ≈===∑
=
n
Xn
ii
µ
Cuando en la muestra existen repeticiones de datos, la media aritmética también se puede calcular a partir de la siguiente expresión:
n
Xfm
kkk∑
== 1)(
µ
Donde: fk = frecuencia de clase Xk = valor de x de la clase n = total de datos de la muestra
Estos datos son tomados de la Tabla de Distribución de frecuencia.
Tabla de Distribución de Frecuencia
k x f fk Xk1 10 2 20 2 15 3 45 3 20 7 140 4 25 5 125 5 30 2 60 6 35 4 140 7 40 1 40 8 45 1 45
n = 25 615 =∑
=
m
kkk Xf
1
)(

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 18
256.2425
615)(
1 ≈===∑
=
n
Xfm
kkk
µ
1.2.1.2 Mediana (Med)
La mediana representa el valor central de los datos ya ordenados de acuerdo a su magnitud. Para datos No agrupados, la mediana es igual al valor medio de la muestra ya ordenada, para notar la diferencia, a continuación se presentan los datos desordenados (tal y como se recopilaron y posteriormente, se presentan ya ordenados de menor a mayor.
Datos desordenados:
20, 10, 35, 40, 20, 35, 15, 45, 20, 25, 15, 30, 20, 30, 20, 25, 25, 35, 20, 10, 25, 15, 20, 25, 35 Datos ordenados: 10, 10, 15, 15, 15, 20, 20, 20, 20, 20, 20, 20, 25, 25, 25, 25, 25, 30, 30, 35, 35, 35, 35, 40, 45 Puesto que el número 25 se encuentra justo en el centro de la lista numérica ya que existen doce números menores o iguales que 25 y doce números mayores o iguales que 25 , éste es del valor que toma la mediana; por lo tanto:
Pero, ¿qué pasa si el número de valores es par?, es decir, que en lugar de 25 datos fueran 10 por ejemplo, en este caso, se ordena la lista y se toman los dos números que quedan en el centro y se obtiene el promedio de ellos, es decir, se suman y el resultado se divide entre 2, el valor resultante, es el valor de la media.
Ejemplo: 10, 10, 15, 15, 15, 20, 20, 20, 20, 20
Los dos datos que se encuentran al centro de la lista numérica son 15 y 20, existen cuatro números menores o iguales a 15 y cuatro números mayores o iguales a 20, en este caso la Mediana se obtiene de la siguiente manera:
Med = 25

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 19
185.172
352
2015≈==+=Med
1.2.1.3 Moda (Mo)
Representa el valor que más veces se repite en la muestra, por lo que, para identificar la clase modal, se recurre a la clase que tenga mayor frecuencia, este dato lo podemos obtener de la lista de datos ordenada como se muestra a continuación:
10, 10, 15, 15, 15, 20, 20, 20, 20, 20, 20, 20, 25, 25, 25, 25, 25, 30, 30, 35, 35, 35, 35, 40, 45 o de la Tabla de Distribución de Frecuencia:
Tabla de Distribución de Frecuencia
k x f1 10 2 2 15 3 3 20 74 25 5 5 30 2 6 35 4 7 40 1
8 45 1
n = 25
En ambos casos, vemos que el número con mayor frecuencia es el 20, por lo tanto:
Si dentro de la muestra existen 2 valores que tienen el mismo número máximo de repeticiones, entonces se dice que la muestra es bimodal y se toman ambos valores como la moda, diferenciándolas con el subíndice 1 y 2 como en el ejemplo que se muestra a continuación:
10, 10, 15, 15, 15, 20, 20, 25, 25, 25
Tanto el 15 como el 25 tienen el valor máximo de repeticiones (3), por lo tanto, esta muestra es bimodal.
Mo1 = 15Mo2= 25
Mo = 20

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 20
1.2.1.4 Medidas de tendencia central con menor incidencia Como se explica al inicio del tema de medidas de tendencia central para datos no agrupados, existen algunas de estas con menor incidencia pero no por ello son menos importantes, tal es el caso de la Media Geométrica, la Media Armónica y la Media Ponderada que se estudian a continuación.
1.2.1.4.1 Media Geométrica Se define como la raíz n-ésima del producto de los valores de la variable.
10x10x15x15x15x20x20x20x20x20x20x20x25x25x25x25x25x30x30x35x35x35x35x40x45 =1.0255833984375e+34
2393.22343750255833984.125 ≈=+= eG
1.2.1.4.2 Media Armónica Se define como el valor inverso de la media aritmética de los recíprocos de los valores de la variable.
∑∑==
== n
i i
n
i i x
n
xn
H
11
1111
451
401
351
351
351
351
301
301
251
251
251
251
251
201
201
201
201
201
201
201
151
151
151
101
101
251 ++++++++++++++++++++++++
==∑
ix
nH
2122.211
1
≈==∑
=
n
i ix
nH
1.2.1.4.3 Media Aritmética Ponderada o Promedio Ponderado Se utiliza cuando las variables en estudios (x), son afectadas por ciertos pesos o factores (w), en este caso, el valor promedio de los datos viene dado por:
∑
∑
=
== m
kk
m
kkk
w
wx
1
1µ

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 21
Debido a que la serie de datos con la que hemos estado trabajando no está afectada por un peso o factor (w), para ejemplificar esta medida en particular, cambiaremos nuestra muestra, ahora tomemos los datos de un solo alumno que estudia en el Instituto Tecnológico de Durango: supongamos que éste alumno está estudiando la carrera de Ingeniería Industrial y que actualmente cursa las siguientes asignaturas: Matemáticas, Probabilidad, Informática y Metodología de la Investigación, cada una de ellas con un valor curricular de 8 créditos; también cursa la materia de Dibujo con un valor curricular de 4 créditos y por último la materia de Ingeniería Industrial, la cual tiene un valor curricular de 6 créditos.
Desde el momento en el que a cada materia se le asigna un peso o factor específico (en este caso los créditos de cada materia), para obtener el promedio obtenido, no basta con el cálculo de la media aritmética, en este caso, se debe calcular el promedio a través de la Media Ponderada, para esto, es necesario conocer aparte del número de créditos de cada materia (w), la calificación obtenida en cada una de las materias (x).
Materia Cred.
(w) Calif. (x) wk xk
Matemáticas 8 70 560 Probabilidad 8 80 640 Informática 8 90 720 Dibujo 4 100 400 Int. Ingeniería Industrial 6 90 540 Met. de la Investigación 8 70 560
Σ(w) = 42 Σ( wk xk )= 3420
8142.8142
3420
1
1 ≈===∑
∑
=
=m
kk
m
kkk
w
wxµ
11..22..22 MMeeddiiddaass ddee DDiissppeerrssiióónn..
Se les conoce también como medidas de variación y nos permite conocer si los valores de la variable de estudio están relativamente cercanos o si se encuentran dispersos tomando como punto de referencia la media (µ).

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 22
Operación indicada
Resultado de la
Operación
1.2.2.1 Desviación Media o Promedio de Desviación (DM). Se emplea para medir el promedio de los alejamientos de los datos observados en la muestra respecto a la media y se define mediante:
n
xfMD
m
kkk∑
=
−= 1
µ
Donde: µ = 25 m = número total de clases xk = Valor de la variable x en la clase k
l xk-µ l = Valor absoluto de la diferencia de la variable x con respecto a su media aritmética
fk = Frecuencia de la clase k
Estos datos los podemos calcular fácilmente a partir de la Tabla de Distribución de Frecuencia.
Tabla de Distribución de Frecuencia
Ahora si, ya que conocemos los datos requeridos, se sustituyen en la ecuación para conocer la Desviación Media (MD).
72.725
1801 ≈==−
=∑
=
n
xfMD
m
kkk µ
k x f l x k-µ l l x k-µ l f k l x k-µ l f k l x k-µ l1 10 2 l 10-25 l 15 2 x 15 30 2 15 3 l 15-25 l 10 3 x 10 30 3 20 7 l 20-25 l 5 7 x 5 35 4 25 5 l 25-25 l 0 5 x 0 05 30 2 l 30-25 l 5 2 x 5 10 6 35 4 l 35-25 l 10 4 x 10 40 7 40 1 l 40-25 l 15 1 x 15 15 8 45 1 l 45-25 l 20 1 x 20 20
Σ(f) = 25 Σ( f k l x k-µ l)= 180

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 23
1.2.2.2 Desviación Típica o Estándar (σ). Es una de las medidas más importantes dentro de la estadística, mide la dispersión en unidades idénticas a aquellas en las que las xi están dadas y se obtiene a través de la siguiente fórmula:
1
)(1
2
−
−=∑
=
n
xfm
kkk µ
σ
Donde: µ = 25 xk = Valor de la variable x en la clase k
(xk -µ )2 = Diferencia de x con respeto a su media aritmética elevada al cuadrado.
fk = Frecuencia de clase. n = Tamaño de la muestra =25. Recurrimos nuevamente a la Tabla de Distribuciones de Frecuencia y agregamos las columnas que sean necesarias para facilitar los cálculos; en lo sucesivo, no se agregarán columnas para indicar las operaciones, se agregarán solo las columnas que contengan el resultado de la operación.
Tabla de Distribución de Frecuencia
k x f xk-µ ( xk-µ)2 fk( xk-µ )2
1 10 2 -15 225 450 2 15 3 -10 100 300
3 20 7 -5 25 175 4 25 5 0 0 05 30 2 5 25 50 6 35 4 10 100 400 7 40 1 15 225 225 8 45 1 20 400 400
n = 25 Σ = 2000
12.923.8324
20001
)(1
2
===−
−=∑
=
n
xfm
kkk µ
σ
1.2.2.3 Varianza. Es la medida de variabilidad de la población y está dada por σ2 por lo tanto, una vez que se conoce el valor de la Desviación Estándar, es muy sencillo obtener la varianza y viceversa.
23.8312.9var 22 ===σ

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 24
Nótese que para el cálculo de la Desviación Estándar y la Varianza, no aproximamos los valores al entero más próximo debido a que si lo hubiésemos hecho, no habría coincidencia en los resultados.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 25
11..33 DDaattooss AAggrruuppaaddooss
Habrá ocasiones en que el tamaño de la muestra aleatoria sea muy grande; obviamente, la gran cantidad de información nos dificulta el proceso y análisis de la misma complicando también la obtención de resultados, en estos casos, se recomienda simplificar el proceso de análisis de la muestra de estudio organizando y ordenando la información numérica, de tal forma que se pueda agrupar por rangos predeterminados y disminuir el número de clases que se registren en una Tabla de Distribuciones de Frecuencia. Para la manipulación de los datos y la obtención de las Medidas de Tendencia Central y Medidas de Dispersión las cuales van a ser nombradas con letras griegas si se trabaja con la población y con letras latinas si se trabaja con una muestra de la población, además se hará la representación Gráfica de los Datos. Se sugiere seguir los siguientes pasos. 1. Toma o recopilación de Datos: Refiere a la obtención de una colección de datos
que no han sido ordenados numéricamente, que representa la población de estudio o en su defecto, es la selección de una muestra aleatoria de la población de interés.
Para este ejemplo, se recopilaron 50 datos que corresponden a igual número de calificaciones obtenidas por alumnos de la especialidad de Ingeniería en Sistemas en la materia de Estructura de Datos durante el semestre Enero-Junio 2004, por lo tanto, n = 50.
98 100 100 45 100 97 98 90 91 100 90 90 100 100 92 80 85 70 97 100
100 50 100 97 50 53 70 84 81 64 70 70 91 81 88 70 64 64 92 50 78 84 100 92 70 86 75 85 55 45
2. Ordenación de Datos: Es la colocación de los números tomados en orden creciente o decreciente de magnitud. (leer la siguiente tabla de arriba hacia abajo y de izquierda a derecha )
45 53 70 70 81 86 91 97 100 100 45 55 70 75 84 88 91 97 100 100 50 64 70 78 84 90 92 97 100 100 50 64 70 80 85 90 92 98 100 100 50 64 70 81 85 90 92 98 100 100

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 26
3. Determinación del Rango (R): Una vez ordenados los datos, es fácil identificar cual es el valor más pequeño de la muestra (45) al que llamaremos Vmínimo y el valor mas grande (100) al que llamaremos, Vmáximo.
A partir de los valores máximo y mínimo obtenemos el rango a través de la siguiente fórmula.
Por lo tanto:
4. Obtención del número de clases o categorías (k): Representa el número de clases que vamos a tener.
( )( )nk log3.31 ×+=
Donde: n = 50
Dado que el número de clases o categorías (k) de una distribución no puede ser fraccionario, se recomienda efectuar un proceso de aproximación o redondeo al entero superior contiguo. Como puede verse en el siguiente cálculo.
( )( )
( )
606601.6606601.51
69897.13.3150log3.31
=+=
×+=×+=k
7606601.6 ≈=k
5. Cálculo de la amplitud o anchura del intervalo de clase ( a ): Indica el número de valores que va a comprender cada clase, se recomienda que se use en las mismas unidades en que están dados los datos recopilados. Es decir, si los datos originales son enteros, el valor de la amplitud deberá ser el entero superior al resultado del cociente del rango entre el número de clases. Por otra parte, si los datos fueran en centésimas, milésimas, etc., el valor de (a) deberá ser un valor coincidente al número de fracciones.
kRa ÷=
Donde, de acuerdo a los cálculos anteriores: R = 55 y k = 7
R = Vmáximo - V mínimo
R = 100 – 45 = 55

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 27
885714.7755
≈=÷=a
6. Elaboración de la Tabla de Distribución de Frecuencia Es la tabla que se forma por 3 columnas, la primera de ellas, representa el número de clase (k) ; la segunda, indica los limites inferiores (l.i.)y superiores (l.s.) que comprende la clase, generalmente inicia en el menor mas pequeño de la muestra (Vinferior) y a partir de este, se cuentan (a) valores para terminar el limite superior, en la siguiente clase, el límite inferior deberá ser uno mas que el limite superior de la clase anterior; mientras que en la tercer columna, se registra cuantos valores caen dentro de el rango que comprende cada clase, a esto se le llama frecuencia de clase (f).
Tabla de Distribución de Frecuencia
Intervalo k Li Ls f1 45 52 52 53 60 23 61 68 34 69 76 75 77 84 66 85 92 12 7 93 100 15
Σf = 50
Como se puede ver, el valor mas pequeño que se encuentra en la muestra es el 45, por lo tanto, este es el primer valor que se toma, la amplitud de clase (a) es = 8, entonces a partir del 45, se cuentan 8 valores (45, 46, 47, 48, 49, 50, 51 y 52) y el último se toma como límite superior para esa clase. En la segunda clase se empieza desde el 53 y se repite la operación hasta completar las 7 clases, obviamente, si se trabaja con números que manejaran hasta centésimas, milésimas, etc., la siguiente clase deberá iniciar en el siguiente valor coincidente al número de fracciones, ejemplo: Si una clase va desde 1.12 hasta 1.24, la siguiente clase iniciará en 1.25. La sumatoria de f debe ser igual a n.
= n

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 28
7. Cálculo de las Medidas de Tendencia Central: Más adelante, se dedica un apartado para estudiar las más comunes son: Media Aritmética, Mediana y Moda.
8. Cálculo de las Medidas de Dispersión: se les conoce también como medidas de variación y se estudiarán la Desviación Media, la Desviación Estándar y la Varianza.
9. Representación de un conjunto dado de datos, mediante un histograma,
polígono de frecuencia, ojivas, etc.
11..33..11 MMeeddiiddaass ddee TTeennddeenncciiaa CCeennttrraall ppaarraa DDaattooss AAggrruuppaaddooss
“Se les conoce también como medidas de centralización, se emplean para indicar un valor que tiende a ser el más representativo de un conjunto de números. Las medidas de mayor importancia son: La Media Aritmética, la Mediana y la Moda, aunque se emplean con menor incidencia también, la media geométrica y la Media Armónica”(De la Barrera Frayre, 2004). Y antes se requiere incorporar los componentes complementarios a la tabla de distribuciones de frecuencia que son necesarios para el cálculo de las medidas de tendencia central.
a) Límites Reales de Clase. Es importante incorporarlos debido a que van a ser
utilizados para el cálculo de la mediana y la moda para datos agrupados. El límite real inferior (LRI), se obtiene restando ½ punto al límite inferior de la clase y el límite real superior (LRS), se obtiene sumando ½ punto al límite superior, en este ejemplo se trabaja con números enteros por lo tanto, se debe restar o sumar 0.5 al límite inferior o superior según sea el caso.
No debemos perder de vista que si se trabaja con números que utilicen décimas, entonces se restará o sumará 0.05; para centésimas se resta o se suma 0.005; en números con milésimas 0.0005 y así sucesivamente.
Para este ejemplo, los límites reales se obtienen de la siguiente forma:
Para la primera clase los límites reales toman los siguientes valores:
LRIk = Lik - 0.5 LRSk = Lsk + 0.5
LRIk = 45 - 0.5 = 44.5 LRSk = 52 + 0.5 = 52.5

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 29
Tabla de Distribución de Frecuencia Intervalo
k Li Ls f LRI LRS 1 45 52 5 44.5 52.5 2 53 60 2 52.5 60.5 3 61 68 3 60.5 68.5 4 69 76 7 68.5 76.5 5 77 84 6 76.5 84.5 6 85 92 12 84.5 92.5 7 93 100 15 92.5 100.5
Σ= 50
b) Marca de Clase o Punto Medio (MC). Se obtiene sumando los límites inferior y superior de una clase y dividiendo entre dos. Es fácil observar que esto es el punto medio del intervalo de clase y por ello se le conoce también como punto medio.
2kk
kLsLiMC +=
Para la clase número 1, la Marca de Clase se obtiene de la siguiente forma:
5.482
972
52452
111 ==+=+= LsLiMC
Tabla de Distribución de Frecuencia
Intervalo k Li Ls f LRI LRS MC 1 45 52 5 44.5 52.5 48.5 2 53 60 2 52.5 60.5 56.5 3 61 68 3 60.5 68.5 64.5 4 69 76 7 68.5 76.5 72.5 5 77 84 6 76.5 84.5 80.5 6 85 92 12 84.5 92.5 88.5 7 93 100 15 92.5 100.5 96.5

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 30
Σf = 50
1.3.1.1 Media Aritmética (µ o X )
Representa el valor promedio de un conjunto de datos, si estos datos están representados a través de una tabla de distribución de frecuencia, la media aritmética se obtiene a partir de la siguiente ecuación:
n
MCfm
kkk∑
== 1)(
µ
Donde: fk = frecuencia de clase MCk = marca de clase, en ocasiones se representa a través de la
variable xn = total de datos de la muestra
Estos datos son tomados de la Tabla de Distribución de frecuencia que se presenta a continuación; en esta misma tabla se agregarán las columnas necesarias para facilitar la comprensión y el cálculo de la media aritmética.
Tabla de Distribución de Frecuencia
Intervalo
k Li Ls f LRI LRS MC fkMCk1 45 52 5 44.5 52.5 48.5 242.502 53 60 2 52.5 60.5 56.5 113.003 61 68 3 60.5 68.5 64.5 193.504 69 76 7 68.5 76.5 72.5 507.505 77 84 6 76.5 84.5 80.5 483.006 85 92 12 84.5 92.5 88.5 1,062.00
7 93 100 15 92.5 100.5 96.5 1,447.50Σf = 50 = n ΣfkMCk = 4.049.00

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 31
8198.8050
4049)(
1 ≈===∑
=
n
MCfm
kkk
µ
1.3.1.2 Mediana (Med)Representa el valor central de los datos ya ordenados de acuerdo a su magnitud. Para datos agrupados la mediana se calcula a través de la siguiente expresión:
cf
fnLRIMedmed
kmed
Σ−÷+= 1)()2(
Donde: LRI kmed = Límite real inferior de la clase mediana Kmed = Clase mediana n = total de datos de la muestra (Σf)1 = Sumatoria de frecuencias de clases inferiores (anteriores) de la
clase mediana (kmed)f med = frecuencia de la clase mediana
c = tamaño del intervalo de la clase mediana y se obtiene de la siguiente manera: LS kmed - LI kmed + 1
LRS kmed = Límite real superior de la clase mediana
Antes de calcular la mediana, tenemos que conocer la clase mediana (kmed), ésta se obtiene al realizar el siguiente procedimiento: a) Dividir n/2; para este ejemplo n = 50 por lo tanto el resultado es igual a 25, éste
resultado representa la posición que ocupa el dato que se encuentra en medio de la muestra ordenada.
b) Desde la primera clase se acumulan las frecuencias una a una hasta encontrar el primer resultado que sea mayor o igual a n/2 (25). Esto nos permite conocer en qué clase se encuentra el dato que está en medio de la muestra (posición 25).
Para este ejemplo, 5+2+3+7+6 representa la frecuencia acumulada de las primeras 5 clases y como el resultado es 23, entonces se tiene que acumular también el 12, resultando 35; éste valor es el primero mayor o igual a 25 por lo tanto kmed = 6 dado que nosotros estamos buscando la clase en la que queda el dato en la posición número 25 y éste fue encontrado en la clase número 6.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 32
Tabla de Distribución de Frecuencia
Intervalo k Li Ls f LRI LRS MC fkMCk1 45 52 5 44.5 52.5 48.5 242.50 2 53 60 2 52.5 60.5 56.5 113.00 3 61 68 3 60.5 68.5 64.5 193.50 4 69 76 7 68.5 76.5 72.5 507.50 5 77 84 6 76.5 84.5 80.5 483.00 6 85 92 12 84.5 92.5 88.5 1,062.00 kmed7 93 100 15 92.5 100.5 96.5 1,447.50
Σf = 50 = n ΣfkMCk = 4,049.00
Ahora si, a partir de kmed podemos conocer otros datos por ejemplo: si kmed=6, entonces las clases inferiores (anteriores) a kmed son las clases 1, 2, 3, 4 y 5, por lo tanto ( Σf )1 se obtiene de sumar todas las frecuencias que están en estas clase (5+2+3+7+6) entonces ( Σf )1 = 23. Para obtener el tamaño del intervalo de la clase mediana ( c ), se resta al limite superior de la clase mediana, el límite real de la clase mediana y se suma 1 (92-85+1 = 8), este dato representa el número de valores que existen en el intervalo 85-92, al enumerarlos; 85, 86, 87, 88, 89, 90, 91 y 92, podemos comprobar que son 8; por lo tanto; c = 8.
8.8533.15.84
8*166.05.84
81225.84
812
23255.84
812
23)250(5.84
)()2(
6
16
=+=+=
+=
−+=
−÷+=
Σ−÷+= cf
fnLRIMed
868.85 ≈=Med

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 33
1.3.1.3 Moda (Mo)
Representa el valor que más veces se repite en la muestra, por lo que, para identificar la clase modal, se recurre a la clase cuya frecuencia sea mayor (kmodal), la moda para datos agrupados, se obtiene mediante la siguiente fórmula:
cLRIMo
∆+∆
∆+=21
1kmodal
Donde: LRIkmodal = Límite Real Inferior de la clase modal. ∆1 = Frecuencia de la clase modal menos la frecuencia de
la clase anterior. ∆2 = Frecuencia de la clase modal menos la frecuencia de
la clase siguiente. c = tamaño del intervalo de la clase modal se obtiene de
restar al Límite superior de la clase modal, el Límite inferior de la clase modal y sumando 1 (Lsmodal – Limodal +1).
Tabla de Distribución de Frecuencia
Intervalo k Li Ls f LRI LRS MC fkMCk1 45 52 5 44.5 52.5 48.5 242.50 2 53 60 2 52.5 60.5 56.5 113.00 3 61 68 3 60.5 68.5 64.5 193.50 4 69 76 7 68.5 76.5 72.5 507.50 5 77 84 6 76.5 84.5 80.5 483.00 6 85 92 12 84.5 92.5 88.5 1,062.007 93 100 15 92.5 100.5 96.5 1,447.50 kmodal
Σ = 50 = n Σ = 4,049.00
Puesto que la clase 7 es la que tiene mayor frecuencia; kmodal = 7, a partir de este dato obtenemos que: f = 15; c = 100-93+1 = 8; ∆1 = 15-12 = 3 y puesto que la 7ª clase es la última, no hay clase posterior, por lo tanto: ∆2=15-0=15

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 34
83.9333.15.928*166.05.92
81835.92
8153
35.92
21
1mod
=+=+=
+=
++=
∆+∆
∆+= cLRIMo alk
9483.93 ≈=Mo
11..33..22 MMeeddiiddaass ddee DDiissppeerrssiióónn ppaarraa DDaattooss AAggrruuppaaddooss
Se les conoce también como medidas de variación y nos permite conocer si los valores de la variable de estudio están relativamente cercanos o si se encuentran dispersos tomando como punto de referencia la media (µ).
1.3.2.1 Desviación Media o Promedio de Desviación (DM)Nos indica en promedio, que tan lejos se encuentran los datos de la muestra con respecto a la media y se define mediante:
n
xfDM
n
kkk∑
=
−= 1
µ
Donde: f = frecuencia de la clase x = marca de clase = media = 81 para este ejercicio
µ−kx = Valor absoluto de la marca de clase menos la media n = total de elementos en la muestra

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 35
Tabla de Distribución de Frecuencia
1392.1250
6461 ≈==−
=∑
=
n
xfDM
m
kkk µ
1.3.2.2 Desviación Típica o Estándar (σ)Es una de las medidas más importantes dentro de la estadística mide la dispersión en unidades idénticas a aquellas en las que las xi están dadas y se obtiene a través de la siguiente fórmula:
1
)(1
2
−
−=∑
=
n
MCfm
kkk µ
σ
Donde: µ = media = 81 para este ejercicio MCk = Marca de clase o valor de la variable x en la clase k
( MCk-µ )2 = Diferencia de la marca de clase con respeto a su media aritmética elevada al cuadrado
fk = Frecuencia de la Marca de clase n = Tamaño de la muestra = 50 para este ejercicio m = Número de clases (7 para este ejemplo)
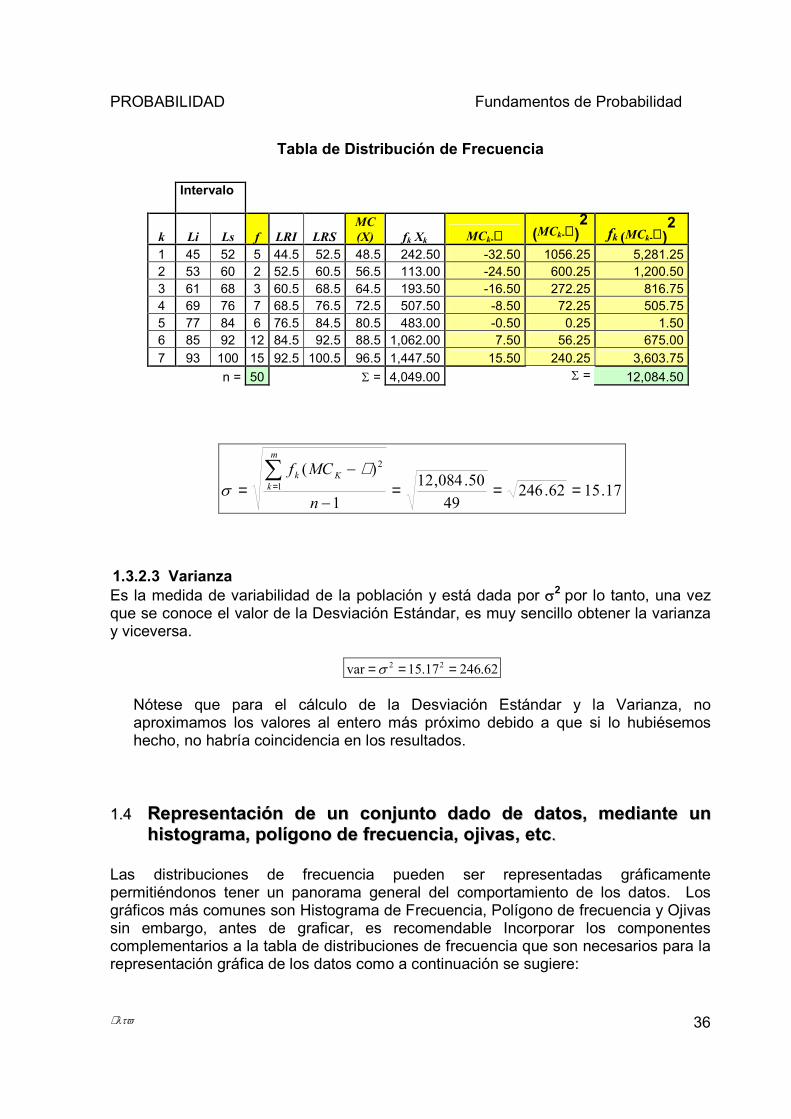
Recurrimos nuevamente a la Tabla de Distribuciones de Frecuencia y agregamos las columnas que sean necesarias para facilitar los cálculos.
Intervalo
k Li Ls f LRI LRS MC (X) fk Xk l MCk-µ l fk l MCk-µ l
1 45 52 5 44.5 52.5 48.5 242.50 32.50 162.50 2 53 60 2 52.5 60.5 56.5 113.00 24.50 49.00 3 61 68 3 60.5 68.5 64.5 193.50 16.50 49.50 4 69 76 7 68.5 76.5 72.5 507.50 8.50 59.50 5 77 84 6 76.5 84.5 80.5 483.00 0.50 3.00 6 85 92 12 84.5 92.5 88.5 1,062.00 7.50 90.00 7 93 100 15 92.5 100.5 96.5 1,447.50 15.50 232.50
n = 50 Σ = 4,049.00 Σ = 646.00
PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 36
Tabla de Distribución de Frecuencia
17.1562.24649
50.084,121
)(1
2
===−
−=∑
=
n
MCfm
kKk µ
σ
1.3.2.3 Varianza Es la medida de variabilidad de la población y está dada por σ2 por lo tanto, una vez que se conoce el valor de la Desviación Estándar, es muy sencillo obtener la varianza y viceversa.
62.24617.15var 22 ===σ
Nótese que para el cálculo de la Desviación Estándar y la Varianza, no aproximamos los valores al entero más próximo debido a que si lo hubiésemos hecho, no habría coincidencia en los resultados.
11..44 RReepprreesseennttaacciióónn ddee uunn ccoonnjjuunnttoo ddaaddoo ddee ddaattooss,, mmeeddiiaannttee uunnhhiissttooggrraammaa,, ppoollííggoonnoo ddee ffrreeccuueenncciiaa,, oojjiivvaass,, eettcc..
Las distribuciones de frecuencia pueden ser representadas gráficamente permitiéndonos tener un panorama general del comportamiento de los datos. Los gráficos más comunes son Histograma de Frecuencia, Polígono de frecuencia y Ojivas sin embargo, antes de graficar, es recomendable Incorporar los componentes complementarios a la tabla de distribuciones de frecuencia que son necesarios para la representación gráfica de los datos como a continuación se sugiere:
Intervalo
k Li Ls f LRI LRS MC (X) fk Xk MCk-µ (MCk-µ )
2fk (MCk-µ )
2
1 45 52 5 44.5 52.5 48.5 242.50 -32.50 1056.25 5,281.252 53 60 2 52.5 60.5 56.5 113.00 -24.50 600.25 1,200.503 61 68 3 60.5 68.5 64.5 193.50 -16.50 272.25 816.754 69 76 7 68.5 76.5 72.5 507.50 -8.50 72.25 505.755 77 84 6 76.5 84.5 80.5 483.00 -0.50 0.25 1.506 85 92 12 84.5 92.5 88.5 1,062.00 7.50 56.25 675.007 93 100 15 92.5 100.5 96.5 1,447.50 15.50 240.25 3,603.75
n = 50 Σ = 4,049.00 Σ = 12,084.50

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 37
a) Frecuencia Relativa (FR). Se expresa generalmente en porcentaje y se obtiene de dividir la frecuencia de la clase entre la sumatoria de frecuencia (Σf =n). La suma de la frecuencia relativa de todas las clases es igual a 1 o 100%.
nfFR k
k =
Para la clase número 1, la Frecuencia Relativa se obtiene de la siguiente forma:
10.05051
1 ===nfFR
Tabla de Distribución de Frecuencia Intervalo
k Li Ls f LRI LRS MC FR 1 45 52 5 44.5 52.5 48.5 0.10 2 53 60 2 52.5 60.5 56.5 0.04 3 61 68 3 60.5 68.5 64.5 0.06 4 69 76 7 68.5 76.5 72.5 0.14 5 77 84 6 76.5 84.5 80.5 0.12 6 85 92 12 84.5 92.5 88.5 0.24 7 93 100 15 92.5 100.5 96.5 0.30
Σ = 50 Σ = 1.0
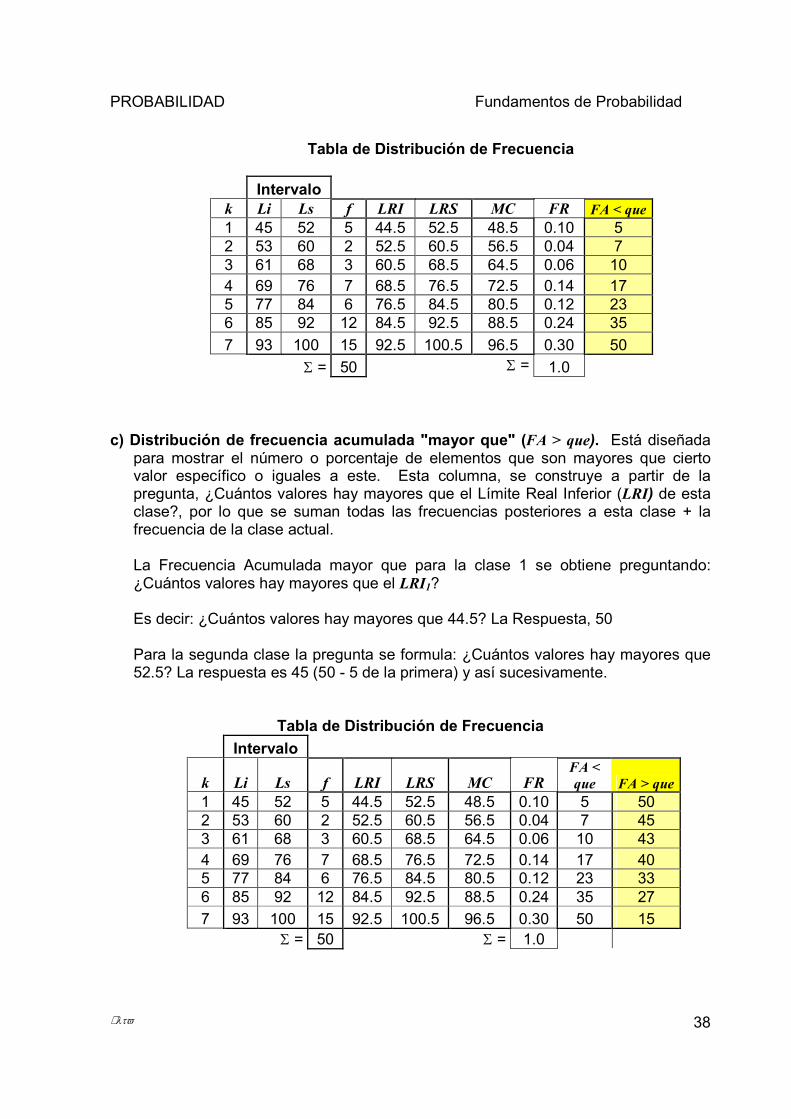
b) Distribución de frecuencia acumulada "menor que" (FA < que). Está diseñada para mostrar el número o porcentaje de elementos que son menores que cierto valor específico o iguales a este. Esta columna, se construye a partir de la pregunta, ¿Cuántos valores hay menores que el Límite Real Superior (LRS) de esta clase?, por lo que se suman todas las frecuencias anteriores a esta clase + la frecuencia de la clase actual.
La Frecuencia Acumulada menor que para la clase 1 se obtiene preguntando: ¿Cuántos valores hay menores que el LRS1?
Es decir: ¿Cuántos valores hay menores que 52.5? La respuesta es 5.
Para la segunda clase la pregunta se formula: ¿Cuántos valores hay menores que 60.5? La respuesta es 7 (5 de la primera clase + 2 de la segunda clase) y así sucesivamente
PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 38
Tabla de Distribución de Frecuencia
Intervalo k Li Ls f LRI LRS MC FR FA < que1 45 52 5 44.5 52.5 48.5 0.10 52 53 60 2 52.5 60.5 56.5 0.04 73 61 68 3 60.5 68.5 64.5 0.06 10 4 69 76 7 68.5 76.5 72.5 0.14 17 5 77 84 6 76.5 84.5 80.5 0.12 23 6 85 92 12 84.5 92.5 88.5 0.24 35 7 93 100 15 92.5 100.5 96.5 0.30 50
Σ = 50 Σ = 1.0
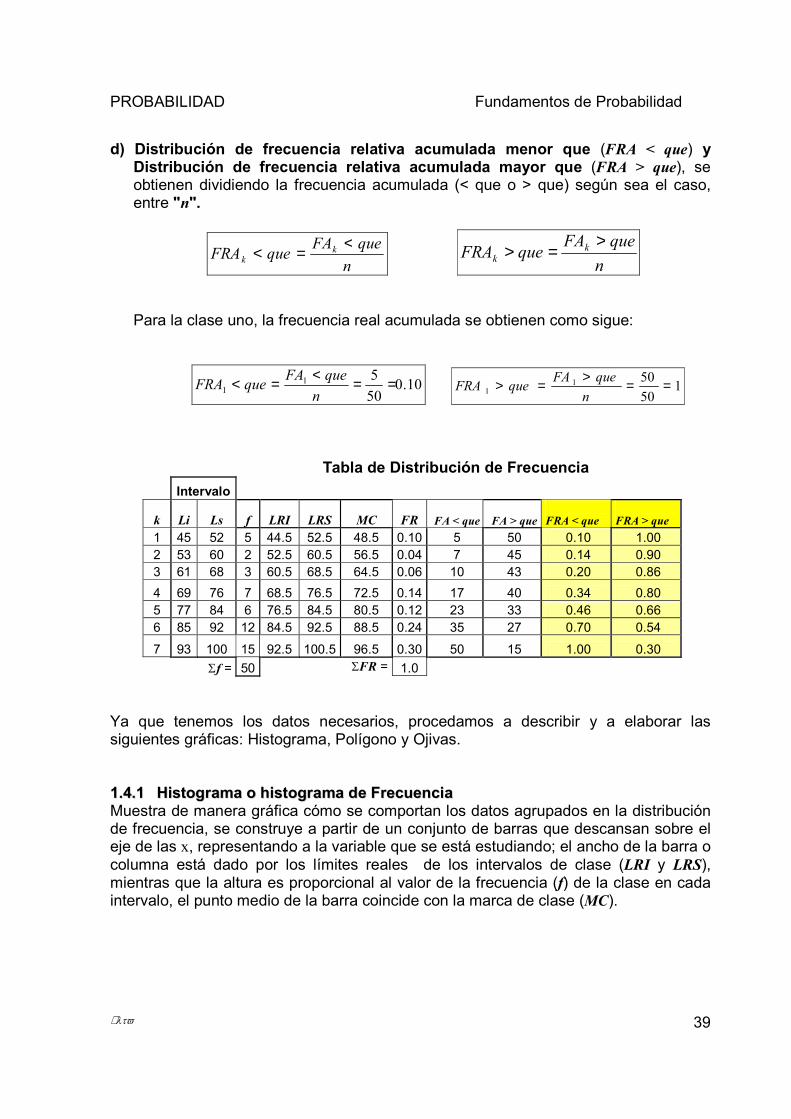
c) Distribución de frecuencia acumulada "mayor que" (FA > que). Está diseñada para mostrar el número o porcentaje de elementos que son mayores que cierto valor específico o iguales a este. Esta columna, se construye a partir de la pregunta, ¿Cuántos valores hay mayores que el Límite Real Inferior (LRI) de esta clase?, por lo que se suman todas las frecuencias posteriores a esta clase + la frecuencia de la clase actual.
La Frecuencia Acumulada mayor que para la clase 1 se obtiene preguntando: ¿Cuántos valores hay mayores que el LRI1?
Es decir: ¿Cuántos valores hay mayores que 44.5? La Respuesta, 50 Para la segunda clase la pregunta se formula: ¿Cuántos valores hay mayores que 52.5? La respuesta es 45 (50 - 5 de la primera) y así sucesivamente.
Tabla de Distribución de Frecuencia Intervalo
k Li Ls f LRI LRS MC FR FA < que FA > que
1 45 52 5 44.5 52.5 48.5 0.10 5 50 2 53 60 2 52.5 60.5 56.5 0.04 7 45 3 61 68 3 60.5 68.5 64.5 0.06 10 43 4 69 76 7 68.5 76.5 72.5 0.14 17 40 5 77 84 6 76.5 84.5 80.5 0.12 23 33 6 85 92 12 84.5 92.5 88.5 0.24 35 27 7 93 100 15 92.5 100.5 96.5 0.30 50 15
Σ = 50 Σ = 1.0
PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 39
d) Distribución de frecuencia relativa acumulada menor que (FRA < que) yDistribución de frecuencia relativa acumulada mayor que (FRA > que), se obtienen dividiendo la frecuencia acumulada (< que o > que) según sea el caso, entre "n".
nqueFAqueFRA k
k<=<
nqueFAqueFRA k
k>=>
Para la clase uno, la frecuencia real acumulada se obtienen como sigue:
10.05051
1 ==<=<n
queFAqueFRA 150501
1 ==>=>n
queFAqueFRA
Tabla de Distribución de Frecuencia Intervalo
k Li Ls f LRI LRS MC FR FA < que FA > que FRA < que FRA > que 1 45 52 5 44.5 52.5 48.5 0.10 5 50 0.10 1.00 2 53 60 2 52.5 60.5 56.5 0.04 7 45 0.14 0.90 3 61 68 3 60.5 68.5 64.5 0.06 10 43 0.20 0.86 4 69 76 7 68.5 76.5 72.5 0.14 17 40 0.34 0.80 5 77 84 6 76.5 84.5 80.5 0.12 23 33 0.46 0.66 6 85 92 12 84.5 92.5 88.5 0.24 35 27 0.70 0.54
7 93 100 15 92.5 100.5 96.5 0.30 50 15 1.00 0.30 Σf = 50 ΣFR = 1.0
Ya que tenemos los datos necesarios, procedamos a describir y a elaborar las siguientes gráficas: Histograma, Polígono y Ojivas.
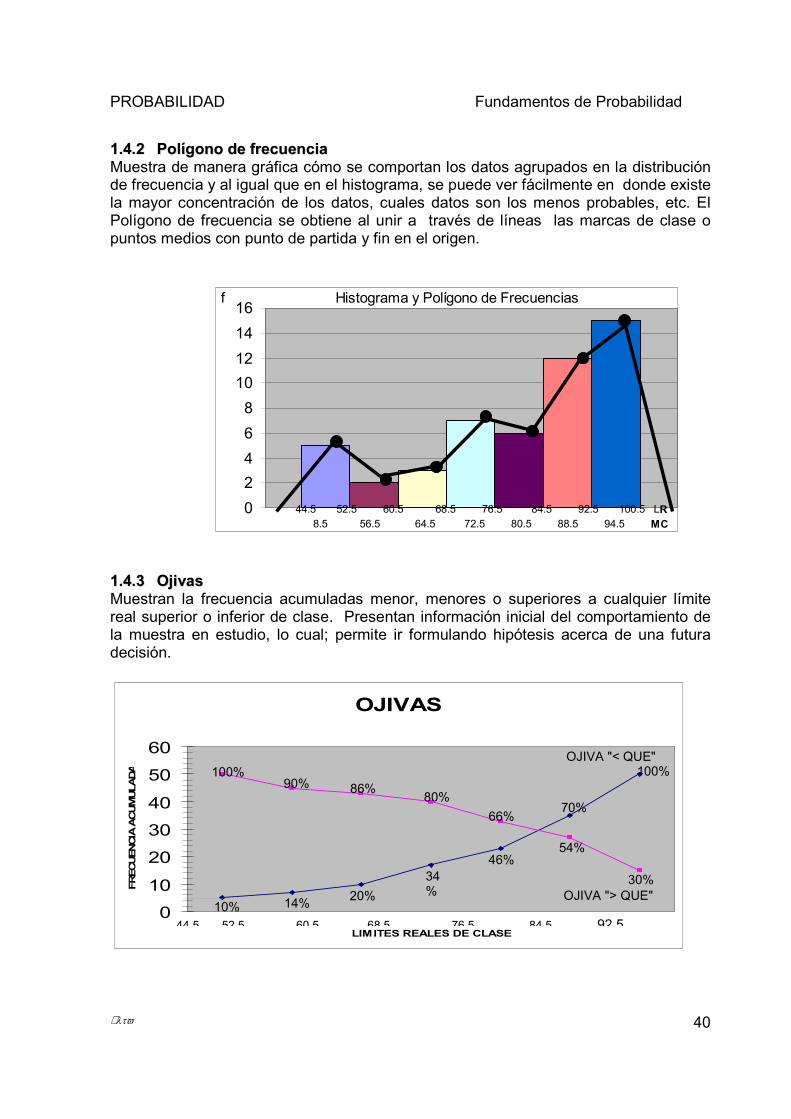
11..44..11 HHiissttooggrraammaa oo hhiissttooggrraammaa ddee FFrreeccuueenncciiaaMuestra de manera gráfica cómo se comportan los datos agrupados en la distribución de frecuencia, se construye a partir de un conjunto de barras que descansan sobre el eje de las x, representando a la variable que se está estudiando; el ancho de la barra o columna está dado por los límites reales de los intervalos de clase (LRI y LRS), mientras que la altura es proporcional al valor de la frecuencia (f) de la clase en cada intervalo, el punto medio de la barra coincide con la marca de clase (MC).
PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 40
11..44..22 PPoollííggoonnoo ddee ffrreeccuueenncciiaaMuestra de manera gráfica cómo se comportan los datos agrupados en la distribución de frecuencia y al igual que en el histograma, se puede ver fácilmente en donde existe la mayor concentración de los datos, cuales datos son los menos probables, etc. El Polígono de frecuencia se obtiene al unir a través de líneas las marcas de clase o puntos medios con punto de partida y fin en el origen.
02468
10121416
44.5 52.5 60.5 68.5 76.5 84.5 92.5 100.5 LR8.5 56.5 64.5 72.5 80.5 88.5 94.5 MC
Histograma y Polígono de Frecuenciasf
11..44..33 OOjjiivvaassMuestran la frecuencia acumuladas menor, menores o superiores a cualquier límite real superior o inferior de clase. Presentan información inicial del comportamiento de la muestra en estudio, lo cual; permite ir formulando hipótesis acerca de una futura decisión.
OJIVAS
0
10
20
30
40
50
60
LIMITES REALES DE CLASE
FREC
UEN
CIA
ACUM
ULA
DA
44.5 52.5 60.5 68.5 76.5 84.5 92.5 10% 14% 20%
34%
46%
70%
100% 100%90% 86% 80%
66%
54%
30% OJIVA "> QUE"
OJIVA "< QUE"

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 41
F O R M U L A R I O
Media Aritmética para Datos No Agrupados
n
xn
ii∑
== 1µ
Media Aritmética para Datos Agrupados
n
xfm
kkk∑
== 1µ
Media Geométrica nnxxxxG ⋅⋅⋅⋅= ...321
Media Armónica ∑
=
= n
i ix
nH
1
1
Promedio Ponderado
∑
∑
=
== n
ii
n
iii
w
wxPONDP
1
1..
Mediana (Med) Datos Agrupados c
ffnLRIMed
medkmed
Σ−÷+= 1)()2(
Moda para Datos Agrupados cLRIMo alk
∆+∆
∆+=21
1mod
Desviación Media o Promedio de Desviación (DM). n
xfMD
n
iii∑
=
−= 1
µ
Desviación Típica o Estándar )
1
)(1
2
−
−=∑
=
n
xfm
kkk µ
σ
Varianza
1
)(1
2
2
−
−=∑
=
n
xfm
kkk µ
σ
Rango R = Vmáximo - V mínimo
Número de clases o categorías ( )( )nk log3.31 ×+=Amplitud o anchura del intervalo kRa ÷=Límite Real Inferior LRIk = Lik - 0.5 Límite Real Superior LRSk = Lsk + 0.5 Marca de Clase o Punto Medio(MC)
2kk
kLsLiMC +=
Frecuencia Relativa (FR) nfFR k
k =

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 42
FFuunnddaammeennttoossddee
PPrroobbaabbiilliiddaadd2.1 Conjuntos y técnicas de conteo. 2.2 Concepto clásico y como frecuencia relativa. 2.3 Espacio muestral y eventos. 2.4 Axiomas y teoremas. 2.5 Espacio finito equiprobable. 2.6 Probabilidad condicional e independencia. 2.7 Teorema de Bayes.
2 FUNDAMENTOS DE PROBABILIDAD 22..11 CCoonnjjuunnttooss yy TTééccnniiccaass ddee CCoonntteeoo..
22..11..11 TTeeoorrííaa ddee CCoonnjjuunnttooss
El objetivo de estudiar la teoría de conjuntos antes de entrar de lleno a la teoría de la probabilidad es que una vez que se haya aprendido a construir los conjuntos, a partir de ellos se establezcan relaciones con otros conjuntos haciendo uso de las definiciones, operaciones y leyes de conjuntos para facilitar la comprensión y manejo de las probabilidades. 2.1.1.1 Definición Un conjunto se define como una colección de objetos con características definidas en forma clara y precisa.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 43
2.1.1.2 Características En cuanto a su notación, los conjuntos se simbolizan a través de letras mayúsculas y se iguala con el grupo de elementos encerrados entre llaves; mientras que sus elementos se representan a través de letras minúsculas separados por coma, y en caso de que existan dos o mas elementos iguales en el conjunto, solo debe ponerse en la lista una vez como se ejemplifica a continuación:
A = a, e, i, 1, 2 B = 1, 2, 3, 4, 5 Los conjuntos están dentro de un súper conjunto que contiene todos los elementos y al cual se le llama Conjunto Universo, este se representa a través de la letra U.
U = a, e, i, 1, 2, 3, 4, 5
Cuando un conjunto carece de elementos se puede indicar a través de el símbolo φ obien a través de y se le conoce como Conjunto Vacío.
B = C = φ
Ambos conjuntos están vacíos. No se debe cometer el error de poner B = φ para indicar que está vacío porque en realidad lo que se está indicando es que B contiene un elemento que es un conjunto vacío. De acuerdo al número de elementos, los conjuntos pueden ser de dos tipos: contablemente finitos o contablemente infinitos. En los conjuntos contablemente finitos se pueden conocer los elementos y determinar con precisión el número de ellos que existen en el conjunto por ejemplo, el conjunto C consta de 15 elementos mientras que el D solo de 8.
C = -4,-3,-2,-1,0,1,2,3,4,5,6,7,8,9,10 D = 1,2…,8
Como puede observarse, en el conjunto D, se utilizan puntos suspensivos para dar continuidad a la lista de elementos, solo se indican los valores iniciales y los finales, y dado que es una lista numérica entera conocida, se deducen los elementos intermedios, esto no lo podemos hacer con datos desconocidos o con valores de punto flotante.
Por el contrario en los conjuntos contablemente infinitos no se pude conocer con exactitud los elementos que lo forman ejemplo:
A = 1,2,3,… o bien B = números enteros positivos
Para nuestros fines, en este libro trataremos solo con conjuntos contablemente finitos.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 44
2.1.1.3 Representación Cuando se enumera la totalidad de los elementos en el conjunto, se dice que su representación es por extensión, (también se le conoce por tabulación o enumeración) he aquí algunos ejemplos:
A = a,e,i,o,u W = pedro, juan, maria Y = a,f,w,x
En la representación por comprensión (también conocida como descripción o construcción), se especifican claramente las características de los elementos que componen el conjunto por ejemplo: A = las vocales del alfabeto M = los números positivos del 1 al 10 También es posible representar a los conjuntos en forma gráfica, a través de Diagramas de Ven, utilizando rectángulos para representar el universo y círculos para representar los conjuntos.
En este ejemplo podemos ver que los elementos i, u pertenecen a los conjunto A y B;para respetar la regla de no repetir elementos en los conjuntos, se hace un traslape de ambos conjuntos y aquí se colocan los elementos en común. Cabe mencionar que cuando se desea indicar que un elemento pertenece a un conjunto, se utiliza el símbolo ∈ por ejemplo para indicar que el elemento a perteneceal conjunto A, se indica a través de la siguiente expresión: a ∈ A.
Si por el contrario, se desea indicar que un elemento no pertenece a un conjunto se utiliza el símbolo ∉ como en el siguiente ejemplo: 7 ∉ A.
2.1.1.4 Relaciones Las relaciones de los conjuntos se pueden dar por igualdad o por inclusión.
aiue
o
7
8
AB
UA = a, e, i, o, u B = i, u, 7, 8 U = a, e, i, o, u, 7, 8

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 45
2.1.1.4.1 Igualdad Se dice que dos conjuntos son iguales (=) cuando ambos tienen exactamente los mismos elementos y desiguales (≠) cuando existe al menos un elemento diferente en alguno de los conjuntos. Si A = 1,2,3,4, B = 1,2,4 y C = 1,2,3,4 entonces A ≠ B y A = C.
2.1.1.4.2 Inclusión Cuando todos los elementos de un conjunto A están incluidos (o pertenecen) a un conjunto B, se dice que A es subconjunto de B y se representa a través del símbolo ⊂. En el caso de que los conjuntos A y B sean iguales se les denomina subconjuntos impropios y se representa a través del símbolo ⊆.
Si A = 1,2,3,4, B = 1,2,4 y C = 1,2,3,4 entonces B ⊂ A y A ⊆ C.
.2.1.1.5 Operaciones Las operaciones que se pueden realizar entre conjuntos son:
• Unión ( ∪ ): Representa la totalidad de los elementos que pertenecen al
conjunto A o al conjunto B, si un elemento existe en ambos conjuntos, solo se pone una vez.
A = a,e,i,o,u
B = i,u,7,8
A ∪ B = a,e,i,o,u,7,8
• Intersección ( ∩ ): Representa solo los elementos que pertenecen tanto al conjunto A como al conjunto B.
A = a,e,i,o,u
B = i,u,7,8
A ∩ B = i,u
ai
ue
o
7
8
AB
U
a
e
o
7
8
AB
U
i
u

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 46
ae
o
7
8
AB
U
i
u
• Diferencia (–): Si se realiza la operación A menos B, el resultado será: los elementos del conjunto A excepto los que sean iguales en el conjunto B.
A = a,e,i,o,u
B = i,u,7,8
A – B = a,e,o
Mientras que
B – A = 7, 8
• Complemento ( ’ ): Representa todos los elementos del universo menos los del conjunto al cual se le aplique el complemento.
A = a,e,i,o,u
B = i,u,7,8
U = a,e,i,o,u,7,8 A’ = 7,8
mientras que
B’ = a,e,o
ae
o
7
8
AB
U
i
u
ae
o
7
8
AB
U
i
u
ae
o
7
8
AB
U
i
u

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 47
Otras operaciones que se pueden realizar entre conjuntos son:
• Producto ( X ): Es el conjunto de pares ordenados entre los elementos del conjunto A y el conjunto B, es decir, a cada elemento de A, le corresponde un elemento del conjunto B.
A = 1,2,3 B = a,b A X B = (1,a),(1,b),(2,a),(2,b),(3,a),(3,b) El número de pares ordenados, debe ser igual del resultado de multiplicar el número de elementos del conjunto A por el número de elementos del conjunto B, para este ejemplo, A tiene 3 elementos y B tiene 2 por lo tanto, debemos obtener 6 pares ordenados, esto se nos hará más fácil si recurrimos al diagrama de árbol para obtener la totalidad de pares ordenados. Para construir el diagrama de árbol, desde el origen, debemos sacar tantas ramas como elementos tenga el primer conjunto, en este caso el primer conjunto es A y tiene 3 elementos, por lo tanto, se dibujan 3 ramas y al final de estas, se coloca cada uno de los elementos (1,2,3), ahora, el punto de partida es cada uno de los elementos del conjunto A y de cada uno de ellos, se sacan tantas ramas como elementos tenga el conjunto B en este caso 2 y en el extremo se colocan los elementos de B (a, b), si hubiese un tercer conjunto, se procedería a hacer lo mismo hasta finalizar. Para conocer cada uno de los pares ordenados, se recorre desde el origen hasta el final cada una de las ramas existentes y se colocan entre paréntesis y separados por coma, cada uno de los elementos que se encontró al recorrerla rama.
A B A X B
a (1,a) 1 b (1,b)
a (2,a) 2 b (2,b)
a (3,a) 3 b (3,b)
Si deseamos tener el producto de 3 conjuntos ejemplo A X B X C, entonces debemos obtener la totalidad de las tercias ordenadas y así sucesivamente. A = 1, 2, 3 B = a, b C = (x,y)

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 48
A B C A X B X C
a x (1, a, x) 1 y (1, a, y) b x (1, b, x) y (1, b, y)
a x (2, a, x) y (2, a, y)
2b x (2, b, x)
y (2, b, y)
a x (3, a, x) 3 y (3, a, y) b x (3, b, x) y (3, b, y)
• Potencia (2A): Es la totalidad de subconjuntos que se pueden generar a partir de un conjunto, si un conjunto tiene 3 elementos, el total de subconjuntos será dos al cubo y siempre se deben considerar como subconjuntos, el conjunto vacío y el mismo conjunto.
A = 1, 2, 3 2A = 1, 2, 3, 1,2, 1,3, 2,3, 1, 2, 3, B = a, b, c, d El conjunto potencia de B tendrá 24 = 16 subconjuntos 2B =a,b,c,d, a,b,a,c,a,d,b,c,b,d,c,d, a,b,c,a,c,d,b,c,d, a,b,c,d,φ
2.1.1.6 Leyes de Conjuntos
• Idempotencia: La unión o la intersección del conjunto A con el conjunto A es igual al mismo conjunto A. (A ∪ A = A) (A ∩ A = A).
• Distributivas: Obtenemos el mismo resultado al realizar la operación Aintersección con el resultado de B Unión C que si elegimos hacer la operación A intersección B, unión, A intersección C. A ∩ (B ∪ C) = (A ∩ B) ∪ (A ∩ C).
• Conmutativas: El orden de los factores no altera el producto, A unión B es igual a B unión A. (A ∪ B) = (B ∪ A).

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 49
• Asociativa: Si realizamos la misma operación entre 3 o mas conjuntos, no importa el orden en el que se realice. (A ∪ B) ∪ C = A ∪ (B ∪ C) .
• Identidad: Cualquier conjunto que se una al conjunto vacío, nos dará por resultado el mismo conjunto, mientras que si se une al universo, el resultado será el conjunto universo. A ∪ φ = Α y A ∪ U = U.
• Complemento: La unión de un conjunto con su complemento nos da como resultado el conjunto universo, mientras que, la intersección de los mismos da como resultado el conjunto vacío. A ∪ A’ = U y A ∩ A’ = φ.
El complemento del conjunto universo es el conjunto vacío y viceversa. U’= φy φ’= U
• Morgan: El complemento del resultado de la operación A unión B, es igual al resultado de A complemento, intersección, B complemento. (A ∪ B)’ = (A’ ∩ B’)
22..11..22 TTééccnniiccaass CCoonntteeoo
Las Técnicas de conteo nos permiten conocer de cuantas maneras puede ocurrir un suceso en el que se realizan varios eventos y en donde el orden de los eventos que participan en dicho suceso puede o no ser importante partiendo desde el principio fundamental de que si un primer evento se puede realizar n1 maneras y un segundo evento se puede realizar de n2 maneras diferentes y un tercer evento de n3 maneras diferentes … y un mésimo evento se puede realizar de nm maneras diferentes, entonces en conjunto de eventos se pueden realizar de mnnnn ⋅⋅⋅⋅ ...321 maneras diferentes. A este principio se le conoce como principio multiplicativo y debemos tener en cuenta que en este caso, todos los eventos deben ocurrir simultáneamente para poder obtener el resultado. Si podemos elegir entre diferentes opciones para lograr el objetivo, es decir no importa cual camino elijamos, llegamos a donde mismo, entonces debemos hacer una suma de resultados para conocer el total de maneras posibles que tenemos para lograr nuestro objetivo, a esto se le conoce como principio aditivo y se puede resumir de la siguiente manera: Si una actividad que nos lleva al objetivo “X” se puede realizar de “n1” maneras diferentes y otra actividad que también nos lleva al objetivo “X” se puede realizar de “n2” formas distintas, el número de formas en que se pueden realizar una uotra actividades es n1 + n2.
2.1.2.1 Permutaciones Cuando colocamos en orden natural los siguientes números 3, 5, 4, 2, 1 (1,2,3,4,5), cuando colocamos en orden alfabético las letras B, C, A, D, J, W (A, B, C, D, J, W), o

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 50
cuando seguimos algún criterio para acomodar a un conjunto de personas (por edad, por estatura, por nombre, etc.) decimos que estamos ORDENANDO los números, las letras, a las personas etc. y en estos casos, el orden si es importante y se le conoce como Permutación.
De acuerdo a lo anterior, la Permutación es todo arreglo de un conjunto de elementos en el cual interesa el orden en que están colocados dichos elementos. Por ejemplo: Si tenemos el conjunto de dígitos 1, 2, 3, 4, 5, ¿Cuántos y cuáles números diferentes de 2 cifras se pueden formar? Aquí, el orden si es importante porque no obtenemos el mismo resultado si se coloca primero el uno y luego el dos (12) a si se coloca primero el dos y después el uno (21). Cuando sabemos que el orden si es importante, sabemos que se trata de una permutación (seguramente en el enunciado del problema aparecerá la palabra ordenar, colocar, acomodar, o cualquier otra que sea sinónimo de orden), en seguida se tendrá que determinar de que tipo de permutación se trata de acuerdo a las características que se presentan en el enunciado:
2.1.2.1.1 Permutación Ordinaria Si de los n elementos con los que se cuenta, solo se desea tomar r a la vez como en el enunciado del ejemplo anterior, se utiliza la siguiente fórmula:
)!(!rn
nrn
P−
=
Ejemplo: Si tenemos el conjunto de dígitos 1, 2, 3, 4, 5, ¿Cuántos y cuáles números diferentes de 2 cifras se pueden formar? esto es, si de los 5 (n) dígitos solo se desean formar números de 2 (r) dígitos, entonces hagamos la sustitución de estos valores para saber cuántos números diferentes de dos dígitos se pueden formar.
2045!3
!345)!25(
!525
=⋅=⋅⋅=−
=
P
El resultado es 20, nótese que en la primera posición se pueden colocar cualquiera de los 5 dígitos del conjunto y en la segunda posición se pueden colocar cualquiera de los cuatro dígitos restantes que no han sido utilizados. Si el enunciado especifica que se trabaje con los n elementos a la vez, entonces n = ry la fórmula que se deberá utilizar es:
!nnn
P =

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 51
Ejemplo: Si tenemos el conjunto de dígitos 1, 2, 3, 4, 5, ¿Cuántos y cuáles números diferentes se pueden formar? esto es, si tenemos 5 (n) dígitos y se desea trabajar con todos los n dígitos o no se especifica como en este caso, hagamos la sustitución de estos valores para saber cuántos números diferentes se pueden formar.
12012345!555
=⋅⋅⋅⋅==
P
El resultado es 120, nótese que en la primera posición se pueden colocar cualquiera de los 5 dígitos del conjunto y en la segunda posición se pueden colocar cualquiera de los cuatro dígitos restantes, en la tercera posición se pueden colocar cualquiera de los tres dígitos restantes que no han sido utilizados y así sucesivamente.
2.1.2.1.2 Permutación con Sustitución En la permutación ordinaria, el elemento que es utilizado en cualquiera de las posiciones, ya no se vuelve a utilizar por eso en el primer ejemplo decimos que solo se pueden formar 20 números, resultantes de colocar cualquiera de los 5 dígitos del conjunto en la primera posición y cualquiera de los cuatro dígitos restantes que no han sido utilizados en la segunda posición (5 x 4 = 20). Sin embargo, de esta manera estaremos dejando fuera los números 11, 22, 33, 44 y 55 debido a que el dígito que se utiliza una vez ya no puede volver a ser usado. Si nos interesa que la totalidad de los elementos se puedan usar desde 1 hasta rveces, es decir, si el elemento utilizado lo podemos seguir utilizando, entonces decimos que se trata de una Permutación con Sustitución y la fórmula que se usa es la siguiente:
rnrn
PS =
Ejemplo: Si tenemos el conjunto de dígitos 1, 2, 3, 4, 5, ¿Cuántos y cuáles números de dos dígitos se pueden formar si los dígitos utilizados se pueden volver a usar? Esto es, si tenemos 5 (n) dígitos y se desea trabajar con todos para formar números de 2dígitos hagamos la sustitución de estos valores para saber cuántos números diferentes se pueden formar.
2555525 2 =⋅==
PS
Si nos interesara formar números de 5 dígitos entonces el resultado sería:
312555555555 5 =⋅⋅⋅⋅==
PS

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 52
En la permutación con sustitución, nótese que en cualquiera de las posiciones se pueden colocar cualquiera de los 5 dígitos que integran el conjunto de datos.
2.1.2.1.3 Permutación Circular Cuando se trabaja con la totalidad de los datos, tal vez nos interese acomodarlos en forma circular, y en este caso como se necesita tener un punto de referencia, se asume que uno de los elementos debe permanecer estático para que actúe como tal y solo se acomodan los n-1 elementos restantes por lo tanto, se utiliza la siguiente fórmula:
)!1( −=
nnn
PC
Ejemplo: Se va a organizar una cena entre amigos, en total, el número de asistentes es 7. ¿De cuántas maneras se pueden sentar en una mesa redonda?
720123456!6)!17(77
=⋅⋅⋅⋅⋅==−=
= PC
Podemos sentar de 720 maneras diferentes a nuestros invitados.
2.1.2.1.4 Permutación con Repetición Si en este momento nos preguntaran cuantas palabras se pueden formar con todas las letras de la palabra amor, nosotros sabemos que se puede resolver a través de una permutación ordinaria donde n = 4 = r y como respuesta diríamos que se pueden formar 24 palabras diferentes porque en la primera posición podemos usar cualquiera de las letras (a, m, o, r), en la segunda posición cualquiera de las tres restantes y así sucesivamente, pero si nos preguntan lo mismo de la palabra campana, o de la palabra instituto, el criterio ya no es el mismo debido a que en ambas palabra existen elementos que se repite, en el caso de la palabra campana, se repite 3 veces la letra ay en el caso de la palabra instituto, se repite 3 veces la letra t y 2 veces la letra i.
Cuando existen elementos que se repiten como en las palabras anteriores, se resuelve a través de una Permutación con Repetición utilizando para ello la siguiente fórmula:
!...!!!
,..., 2121 mm nnnn
nnnn
PR⋅⋅⋅
=
En donde n = número total de elementos y mnnn ,..., 21 = número de cada uno de los elementos que se repiten Ejemplo 1: ¿Cuántas palabras se pueden formar con todas las letras de la palabra campana?n = 7 (la palabra campana tiene 7 letras)

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 53
1n = 3 (la letra a se repite 3 veces)
8404567!3
!34567!3!7
37
=⋅⋅⋅=⋅⋅⋅⋅==
PR
Resultado: Se pueden formar 840 palabras con todas las letras de la palabra campana.
Ejemplo 2: ¿Cuántas palabras se pueden formar con todas las letras de la palabra instituto?n = 9 (la palabra instituto tiene 9 letras)
1n = 2 (la letra i se repite 2 veces)
2n = 3 (la letra t se repite 3 veces)
302402
6048012
456789!312
!3456789!3!2
!93,2
9==
⋅⋅⋅⋅⋅⋅=
⋅⋅⋅⋅⋅⋅⋅⋅=
⋅=
PR
Resultado: Se pueden formar 30240 palabras con todas las letras de la palabra instituto
2.1.2.2 Combinaciones Habrá ocasiones en las que el orden no es importante, por ejemplo si tenemos un conjunto de 3 personas (Juan, María, Pedro), y nos interesa seleccionar a una pareja para que expongan un tema en clase, la pareja puede estar formada por:
Juan y Maria Juan y Pedro Pedro y María
Si se elige primero a María, las parejas se pueden formar de la siguiente forma:
María y Juan Juan y Pedro María y Pedro Si se elige primero a Pedro, las parejas se pueden formar de la siguiente forma:
Juan y Maria Pedro y Juan Pedro y María
Nótese que no importa el orden en el que se elige a las personas, solo se pueden formar 3 posibles parejas en este caso, el equipo formado por Maria y Juan es exactamente el mismo que el de Juan y María, el orden no altera el resultado, caso contrario que en la permutación cuando hablamos de combinaciones, seguramente en el enunciado del problema a resolver seguramente se hará referencia a el número de equipos, conjuntos, comités, o cualquier palabra que nos de idea de agrupar y la formula que usaremos es:
)!(!!
rnrn
rn
C−
=

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 54
En donde: n = total de elementos r = tamaño del grupo que se desea formar
Ejemplo: Tenemos a 5 jugadores de básquetbol, para identificarlos, en sus camisetas traen los siguientes números: 1, 2, 3, 4, 5; se van a formar retas de 2 jugadores. ¿Cuántos y cuáles retas diferentes podemos formar con ellos?
10220
1245
!3!2!345
)!25(!2!5
25
==⋅⋅=
⋅⋅⋅=
−=
C
Resultado: Se pueden formar 10 equipos (retas) diferentes. Y son: (1,2), (1,3), (1,4), (1,5), (2,3), (2,4), (2,5), (3,4), (3,5), (4,5)
A través de la fórmula de combinaciones respondimos ¿cuántas?, en seguida diremos como obtuvimos ¿cuáles?
2.1.2.3 Diagrama de Árbol El diagrama de árbol (utilizado con anterioridad en el tema Producto de Conjuntos), es una herramienta importante que nos permite conocer no solo ¿cuantos? sino ¿cuáles? Estos resultados los podemos obtener través del siguiente diagrama de árbol, donde cada rama del árbol representa un equipo (reta) diferente.
1ª. Pos.
1
2ª. Pos. 2345
Reta
1,2 1,3 1,4 1,5
2345
2,3 2,4 2,5
345
34 35
4 5 4,5
El primer jugador, puede hacer equipo con el jugador 2 o 3 o 4 o 5, por lo tanto, puede hacer equipo con cualquiera de las 4 personas, es decir, de aquí resultan 4 equipos diferentes; el segundo jugador puede hacer equipo solo con los jugadores 3 o 4 o 5; resultando solo tres equipos. El tercer jugador puede hacer equipo solo con los jugadores 4 o 5; resultando solo dos equipos y el cuarto jugador solo puede hacer

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 55
equipo con el quinto jugador; resultando solo un equipos haciendo un total de (4+3+2+1) 10 equipos diferentes. 2.1.2.4 Particiones Ordenadas Cuando el Orden no es importante y se desea repartir el todo en partes, siempre y cuando la suma de las partes es igual al todo, estamos trabajando con particiones ordenadas Ejemplo: Encuentre el número de formas como se pueden distribuir 9 juguetes entre 4 niños, si el más pequeño debe recibir 3 juguetes y cada uno de los otros, 2 juguetes. En el enunciado anterior se especifica claramente que el todo (los 9 juguetes que se tienen en total), se van a repartir en 4 partes (4 niños) una de esas partes es de tamaño 3 (al niño más pequeño se le darán 3 juguetes) y los seis juguetes restantes se deben repartir entre las 3 partes restantes por lo tanto, el tamaño de cada una de estas partes será de tamaño 2, veámoslo gráficamente:
La fórmula que se va a utilizar es:
!...!!!
,..., 2121 mm nnnn
nnnn
PO⋅⋅⋅
=
En donde n = número total de elementos y mnnn ,..., 21 = tamaño de cada una de las partes Para este ejemplo: n = 9 (total de juguetes)
1n = 3 (número de juguetes que se le dan al niño más pequeño –niño 1-)
2n = 2 (número de juguetes que se le dan al niño 2)
3n = 2 (número de juguetes que se le dan al niño 3)
4n = 2 (número de juguetes que se le dan al niño 4)
75608
604808
456789!3121212!3456789
!2!2!2!3!9
2,2,2,39
==⋅⋅⋅⋅⋅=⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅=
⋅⋅⋅=
PO
3 2
22
3+2+2+2 = 9 La suma de las partes es igual al todo

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 56
Resultado: Existen 7560 maneras de repartir 9 juguetes entre 4 niños dándole al más pequeño 3 juguetes.
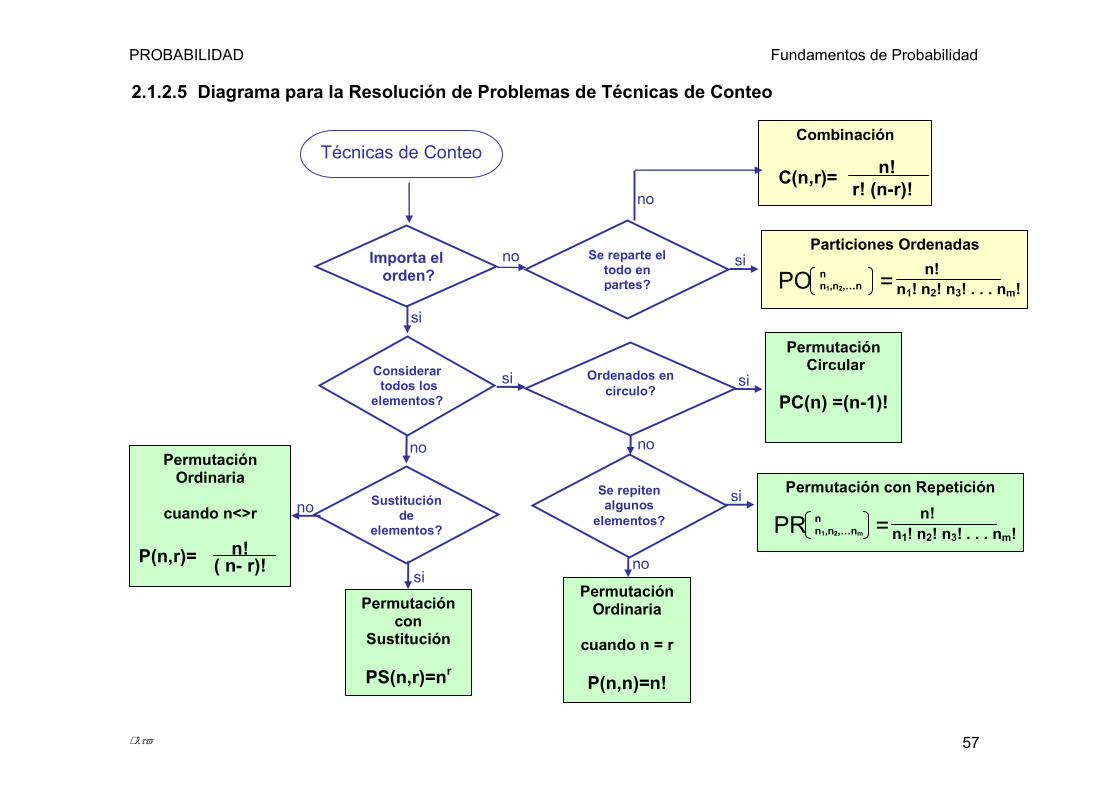
PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 57
2.1.2.5 Diagrama para la Resolución de Problemas de Técnicas de Conteo
Permutación con Repeticiónn!
n1! n2! n3! . . . nm!nn1,n2,…nmPR =
Combinación
n!r! (n-r)!C(n,r)=
Importa elorden?
Considerartodos los
elementos?
Se repitenalgunos
elementos?
si
si
nono
Sustituciónde
elementos?
Ordenados encírculo?
si
PermutaciónCircular
PC(n) =(n-1)!
no
PermutaciónOrdinaria
cuando n<>r
n!( n- r)!P(n,r)=
si
Se reparte eltodo enpartes?
no si
Técnicas de Conteo
no
nosi
Permutacióncon
Sustitución
PS(n,r)=nr
PermutaciónOrdinaria
cuando n = r
P(n,n)=n!
Particiones Ordenadasn!
n1! n2! n3! . . . nm!nn1,n2,…nPO =

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 58
22..22 CCoonncceeppttoo cclláássiiccoo yy ccoommoo ffrreeccuueenncciiaa rreellaattiivvaa
La Teoría de la Probabilidad, se desarrolló para entender los juegos de azar, y es la rama de las matemáticas que se ocupa de medir o determinar cuantitativamente la posibilidad de que ocurra un determinado suceso.
“Sea E el resultado de un experimento, llamado evento, hay dos formas de obtener la probabilidad p de E:
a) Definición clásica (A priori): suponiendo que un evento E puede ocurrir de sformas de un total de n formas igualmente posibles. Entonces p = s/n.
b) Definición de frecuencia (A posteriori): Suponiendo que después de nrepeticiones, para valores muy grandes de n, un evento E ocurre s veces. Entonces p = s/n.
Las dos definiciones anteriores tienen grandes fallas. La definición clásica es esencialmente circular, puesto que la idea de igualmente posibles es la misma de aquella de con igual posibilidad que no ha sido definida. La definición de frecuencia no está claramente definida puesto que valores muy grandes no han sido definidos”(Lipschutz, 2001, p 62).
22..33 EEssppaacciioo mmuueessttrraall yy eevveennttooss
El uso de conjuntos representados por diagramas de Venn, facilita la compresión de espacio muestral y evento, ya que el espacio muestral S, se puede equiparar con el conjunto universo, debido a que S contiene la totalidad de los resultados posibles de un experimento, mientras que los eventos E contienen solo un conjunto de resultados posibles del experimento, mientras que los puntos muestrales se equiparan con los elementos. Vamos a suponer que el experimento que se realiza es el lanzamiento de un dado y queremos conocer ¿cuál es la probabilidad de que caiga un 3 o un 5? Si S contiene la totalidad de los resultados posibles, entonces S = 1, 2, 3, 4, 5, 6 puesto que el dado tiene 6 caras y si buscamos la probabilidad P de que caiga 3 o 5, esto constituye un evento entonces, E = 3, 5, la representación gráfica queda de la siguiente manera: S
E3 5
1 2
46
Puntos Muestrales

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 59
El espacio muestral S, está representado por un rectángulo, este contiene eventos Erepresentados a través de círculos y puntos muestrales. Dado que en E existen dos elementos y en S seis, la probabilidad P de que ocurra E es 2 de 6 y se obtiene al dividir el número de elementos en E sobre el número de elementos en S.
)()(
Senelemenos denúmeroEenelementos denúmero)(
SnEnEP ==
También se puede leer:
)()(
Smuestral espacio elocurrir puede queenformas denúmeroEevento elocurrir puede queenformas denúmero)(
SnEnEP ==
Se obtiene como resultado:
31
62
)()()( ===
SnEnEP
22..44 AAxxiioommaass yy tteeoorreemmaass
22..44..11 AAxxiioommaass ddee PPrroobbaabbiilliiddaaddDe acuerdo al Diccionario de la Lengua Española un axioma “es una proposición tan clara y evidente que se admite sin necesidad de demostración”, por tanto existen tres axiomas de probabilidad que se describen a continuación, partiendo del hecho de que S representa el espacio muestral, A representa cualquier evento y P la utilizaremos para llamar a la función de probabilidad, por consiguiente P(A) se denomina la probabilidad del evento A.
Axioma 1 Para cualquier evento A, se tiene que la probabilidad del evento A se encuentra entre 0 y 1.
0 ≤ P(A) ≥ 1
Axioma 2 Para el espacio muestral S, se tiene que la probabilidad es igual a 1. P(S) = 1
Axioma 3 Para dos eventos mutuamente excluyentes A y B, se tiene que la probabilidad de la unión de estos eventos es igual a la suma de la probabilidad del evento A + la suma de la probabilidad del evento B.
P (A∪ B) = P(A) + P(B)
Si se tiene una secuencia infinita de eventos mutuamente excluyentes A1,A2, A3,…, An se tiene que:

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 60
P(A1∪ A2∪ A3∪,…, A n) = P(A1)+ P(A2) + P(A3) +…+ P(A n)
22..44..22 TTeeoorreemmaass ddee PPrroobbaabbiilliiddaaddDe acuerdo al Diccionario de la Lengua Española, “Teorema es una proposición demostrable lógicamente, partiendo de axiomas o de otros teoremas ya demostrados mediante reglas de inferencia aceptadas” Teorema 1 La probabilidad del conjunto vacío φ, tiene probabilidad cero, esto
también es conocido como evento imposible.
P (φ) = 0
Teorema 2 A este teorema se le llama regla del complemento y se refiere a que la probabilidad del complemento del evento A es igual a 1 menos la probabilidad del evento A.
P (A’) = 1- P (A)Teorema 3 Si la probabilidad del evento A está entre 0 y 1 inclusive, y la probabilidad
de A’ se obtiene de restar 1 – P(A), se deduce que la suma de la probabilidad del evento A + la probabilidad del evento A’ es igual a:
1 = P(S) = P(A∪ A’) = P(A) + P(A')
Teorema 4 Si el evento A ⊂B, entonces la probabilidad del evento A es menor que la probabilidad del evento B
P (B) = P(A) + P(B -A)
Teorema 5 Para dos eventos A y B, la probabilidad del evento A menos el evento Bes igual a la probabilidad del evento A menos la probabilidad Aintersección B.
P(A \ B) = P(A) − P (A∩ B)
Teorema 6 A este teorema se le conoce como regla de adición y se refiere a que para dos eventos A yGB, la probabilidad de la unión de los dos eventos es igual a la suma de la probabilidad del evento A mas la probabilidad el evento B menos la probabilidad A intersección B.
P(A ∪ B) = P(A) + P(B) − P(A∩ B)

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 61
22..55 EEssppaacciioo ffiinniittoo eeqquuiipprroobbaabblleeUn espacio muestral es finito cuando es posible contar sus puntos muestrales es decir, es un espacio contablemente finito y se convierte en espacio de probabilidad finito cuando a cada punto ai se le asigna una probabilidad pi; si la probabilidad es la misma para todos los puntos muestrales, entonces se dice que es un espacio finito equiprobable y debe satisfacer las siguientes propiedades:
• Cada pi debe ser mayor o igual a cero, es decir, pi ≥ 0
• La suma de todos las pi debe ser igual a 1, es decir, Σpi = 1
Un dado tiene seis caras, por lo tanto, su espacio muestral está formado de la siguiente manera:
S = 1, 2, 3, 4, 5, 6
si es tratado como un espacio finito equiprobable, tenemos que la probabilidad que caiga un 1, es la misma probabilidad de que caiga 2 o 3 o 4 o 5 o 6.
p(1) = 1/6, p(2) = 1/6, p(3) = 1/6, p(4) = 1/6, p(5) = 1/6, p(6) = 1/6
Algunas veces, la asignación de las probabilidades a los puntos muestrales, se dan en forma de tabla como se muestra a continuación:
Resultado a1 a2 . . . anProbabilidad p1 p2 . . . pn
A esta tabla se le conoce como una distribución de probabilidad.
Continuando con el ejemplo del dado, a continuación se presenta su distribución de probabilidad.
Resultado 1 2 3 4 5 6Probabilidad 1/6 1/6 1/6 1/6 1/6 1/6
Obsérvese que se cumplen las dos propiedades de los espacios finitos de probabilidad:
• Cada pi debe ser mayor o igual a cero, es decir, pi≥ 0
En este caso pi = 1/6, por lo tanto se cumple que, pi≥ 0
• La suma de todos las pi debe ser igual a 1, es decir, Σpi = 1

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 62
1/6 + 1/6 + 1/6 + 1/6 + 1/6 + 1/6 = 6/6 = 1, cumpliendo que; Σpi = 1
22..66 PPrroobbaabbiilliiddaadd ccoonnddiicciioonnaall ee iinnddeeppeennddeenncciiaa
22..66..11 PPrroobbaabbiilliiddaadd CCoonnddiicciioonnaall
A partir de un espacio muestral se pueden generar diferentes eventos por ejemplo, en el lanzamiento de un dado con S = 1, 2, 3, 4, 5, 6 queremos conocer la probabilidad de que caiga un número par y la probabilidad de que caiga un número primo. Primero se construyen los eventos: A = 2, 4, 6 y B = 1, 2, 3, 5, para poder obtener el resultado de P(A) y P(B); podemos utilizar la tabla de distribución de probabilidades.
Resultado 1 2 3 4 5 6Probabilidad 1/6 1/6 1/6 1/6 1/6 1/6
P(A) = p(2) + p(4) +p(6) = 1/6 + 1/6 + 1/6 = 3/6 = 1/2
P(B) = p(1) + p(2) +p(3) + p(5) = 1/6 + 1/6 + 1/6 + 1/6= 4/6 = 2/3
También podemos auxiliarnos de los diagramas de Venn y hacer una representación gráfica del S, A y B.
Obtenemos que:
21
63
)()()( ===
SnAnAP y
32
64
)()()( ===
SnBnBP
Nótese que en diagrama se ve claramente que hay puntos muestrales que contienen tanto el evento A como el evento B, es decir, se da una intersección entre A y B.
S
B2 3
1 5
46
A
A ∩ B = 2 S
B2 3
1 5
46
A

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 63
Los elementos que se encuentran en la intersección pueden representar dos cosas:
• Los números pares siempre y cuando sean primos o bien,
• Los números primos siempre y cuando sean pares Obsérvese que en ambos casos, se condiciona a que ocurra un evento A, cuando haya ocurrido un evento E.
En el primer caso se condiciona a que ocurra:
A = números pares del 1 al 6 cuando haya ocurrido E = números primos del 1 al 6 En el segundo caso se condiciona a que ocurra:
A = números primos del 1 al 6 cuando haya ocurrido E = números pares del 1 al 6
A la probabilidad de que ocurra un evento A una vez que E ha ocurrido, se le conoce como probabilidad condicional de A dado E, se escribe P(AE), y se define así:
)()()(
EnBAPEAP ∩=
Si S es un espacio equiprobable:
)()()(
SnEAnEAP ∩=∩ y
)()()(
SnEnEP =
entonces:
)()(
)()()()(
)()()(
)(
)()()(
EnEAn
EnSnEAnSn
SnEnSn
EAn
EnEAPEAP ∩=
×∩×=
∩
=∩=

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 64
por lo tanto:
)()()(
EnEAnEAP ∩
=
Ejemplo: Se lanza un dado y se desea conocer cual es la probabilidad de que caiga un número par siempre y cuando sea primo.
Si A = 2, 4, 6 , B = 1, 2, 3, 5 y A ∩ B = 2
Entonces: 41
)()()( =∩=
BnBAnBAP
Pero si se busca la probabilidad de que caiga un número primo siempre y cuando sea par:
Entonces: 31
)()()( =∩=
AnBAnABP
22..77 TTeeoorreemmaa ddee BBaayyeess
Recibe su nombre por el matemático inglés Thomas Bayes y se desarrolló a partir de la suposición de que los eventos A1, A2,…, An mutuamente excluyentes, forman una partición del espacio muestral S y son causas posibles del evento E, quien también está contenido en S. “La fórmula de Bayes nos permite determinar la probabilidad de ocurrencia de un A particular, dada la ocurrencia de E”(Lipschutz. 2001, p. 92) y se define como:
)()(...)()()()()()(
)(2211 AnEPAnPAEPAPAEPAPAEPAP
EAP kkk ⋅++⋅+⋅
⋅=
Ejemplo: En una fábrica que produce escritorios, se trabajan 3 turnos, A, B y C,supongamos que en el turno A, se produce el 50% de todos los escritorios, y de ellos,
A ∩ B = 2 S
B2 3
1 5
46
A

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 65
el 3% salen con algún defecto. En el turno B, se producen el 30% de los escritorios y el resto, se producen en el turno C, el turno B obtiene un 4% de escritorios defectuosos mientras que el C el 5%. Se elige un escritorio al azar y se resulta defectuoso, se desea conocer cual es la probabilidad de que haya sido fabricado en el turno A.
De acuerdo a la información proporcionada:
P(A) = 50% y P(DA) = 3% P(B) = 30% y P(DB) = 4% P(C) = 20% y P(DC) = 5%
Utilizando el teorema de Bayes:
)()()()()()()()(
)(CDPCPBDPBPADPAP
ADPAPDAP
⋅+⋅+⋅
⋅=
%5.40405.0037.0015.0
01.0012.0015.0015.0
05.020.004.030.003.050.003.050.0)( ===
++=
×+×+×⋅×=DAP
En el teorema, el divisor representa la probabilidad que se tiene de que un artículo salga defectuoso considerando la producción total por lo tanto:
P(D) = 0.037 = 3.7%
Conocer este dato, facilita el calculo de la probabilidad de que el artículo defectuoso haya sido fabricado en el turno B.
%4.32324.0037.0012.0
037.004.03.0
)()()(
)( ===⋅=⋅
=DP
BDPBPDBP
Calcule usted la probabilidad de que el artículo defectuoso haya sido fabricado en el turno C.

PROBABILIDAD Fundamentos de Probabilidad
µλτϖ 66
F O R M U L A R I O
Permutación Ordinaria )!(!rn
nrn
P−
=
Permutación con sustitución
rnrn
PS =
Permutación Circular
)!1( −=
nnn
PC
Permutación con Repetición
!...!!!
,..., 2121 mm nnnn
nnnn
PR⋅⋅⋅
=
Combinaciones )!(!
!rnr
nrn
C−
=
Particiones Ordenadas !...!!
!,..., 2121 mm nnn
nnnn
nPO
⋅⋅⋅=
Probabilidad de que ocurra el evento E )(
)(Senelemenos denúmeroEenelementos denúmero)(
SnEnEP ==
Independencia Si )()()( BAPBPAP ∩=⋅ entonces A y B son independientes Si )()()( BAPBPAP ∩≠⋅ entonces A y B son dependientes
Probabilidad Condicional
)()()(
EnBAPEAP ∩=
Teorema de Bayes )()()()()()(
)()()(
CDPCPBDPBPADPAPADPAP
DAP⋅+⋅+⋅
⋅=

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 67
MMooddeelloossAAnnaallííttiiccooss ddeeFFeennóómmeennooss
AAlleeaattoorriioossDDiissccrreettooss
3.1 Definición de variable aleatoria discreta. 3.2 Función de probabilidad y de distribución, valor esperado,
varianza y desviación estándar. 3.3 Distribución Binomial. 3.4 Distribución Hipergeométrica.
3.4.1Aproximación de la hipergeométrica por la Binomial. 3.5 Distribución Geométrica. 3.6 Distribución Multinonial. 3.7 Distribución de Poisson.
3.7.1 Aproximación de la Binomial por la de Poisson.
3 MODELOS ANALÍTICOS DE FENÓMENOS ALEATORIOS DISCRETOS
33..11 DDeeffiinniicciióónn ddee vvaarriiaabbllee aalleeaattoorriiaa ddiissccrreettaa..
Variable aleatoria: Es la correspondencia que se establece entre el conjunto de los resultados de experimento aleatorio y el conjunto de los números reales.

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 68
Variable Aleatoria Discreta (V.A.D.): Es la correspondencia que se establece entre el conjunto de los resultados de un experimento aleatorio y el conjunto de los números reales cuando el conjunto de resultados del experimento es contable.
33..22 FFuunncciióónn ddee pprroobbaabbiilliiddaadd yy ddee ddiissttrriibbuucciióónn,, vvaalloorr eessppeerraaddoo,,vvaarriiaannzzaa yy ddeessvviiaacciióónn eessttáánnddaarr
33..22..11 FFuunncciióónn ddee PPrroobbaabbiilliiddaaddPermite asignar a cada valor de la variable su probabilidad y se expresa de la siguiente manera:
( ) 1=∑∈∀ Xx
xp
33..22..22 FFuunncciióónn ddee DDiissttrriibbuucciióónnLa Función de Distribución, es la probabilidad de que una variable aleatoria tome valores menores o iguales que un cierto valor real t; también se le conoce como probabilidad acumulada. La Función de distribución se representa como:
( ) 1=∑∈∀ Xx
xp
33..22..33 MMeeddiiddaass ddee TTeennddeenncciiaa CCeennttrraall
Muestran el comportamiento medio o promedio de los valores que puede tomar la variable aleatoria, las más comunes son: Valor esperado o media, mediana y moda. 3.2.3.1 Valor esperado o media El valor esperado, es la sumatoria de los valores de la variable aleatoria xmultiplicados por su probabilidad p.
( )∑∈∀ Xx
xpx
3.2.3.2 Moda La Moda de una Variable Aleatoria Discreta (V. A. D.), es el valor más probable, o más frecuente, de una variable aleatoria: es decir, se define como el valor de la variable aleatoria tal que ( ) ( )xpMop ≥ para toda x∈X.

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 69
3.2.3.3 Mediana La Mediana de una V. A. D, es el número real para el que se cumple que la probabilidad acumulada de una variable aleatoria es menor o igual que 0.5 y su expresión matemática es:
( )21=
∈≤∑
XxMedxp
33..22..44 MMeeddiiddaass ddee VVaarriiaacciióónn
Permiten estudiar la dispersión que tienen los diferentes valores de la variable aleatoria, las más comunes son la Varianza y la Desviación Típica o Estándar. 3.2.4.1 Varianza La varianza es una medida de dispersión alrededor de su valor medio, si su valor es pequeño, indica una concentración o poca dispersión de los datos, alrededor de su valor medio y, por el contrario, su valor es alto, indica una dispersión considerable de los datos respecto al valor central.
( ) ( ) 222)( µµ −∑∈∀
=−=Xx
xpxXEXV
3.2.4.2 Desviación Típica o Estándar Es la raíz cuadrada de la varianza y se expresa de la siguiente manera:
( ) ( )XVX +=σ
33..33 DDiissttrriibbuucciióónn BBeerrnnoouullllii
Describe el comportamiento de una variable aleatoria x: “número de éxitos en una extracción o prueba”, cuando solo hay dos posibles resultados “éxito” o “fracaso”; Las extracciones son independientes y la probabilidad de éxito permanece constante e igual a p. El espacio muestral de una prueba de Bernoulli es: S = éxito, fracaso; al éxito se le asigna el valor de 1 y al fracaso el valor 0, por lo que el espacio muestral también puede representarse como : S = 1,0.
La Media (µ) de Distribución Bernoulli es igual a la probabilidad de éxito.

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 70
( ) ( ) ( ) ( ) pppixfixXE =+−=∑== 110µ
La Varianza (var o σ2) de la Distribución Bernoulli se obtiene de multiplicar la probabilid de éxito por la probabilidad de fracaso.
( ) ( ) ( )[ ] ( )
( ) qppppp
pppXEixfixXV
=−=−
=−
+−=−∑==
12
221120222σ
La Desviación Estándar de la Distribución Bernoulli se calcula de la raíz cuadrada de la varianza.
qp=σ
33..44 DDiissttrriibbuucciióónn BBiinnoommiiaall..
Describe el comportamiento de una variable aleatoria x: “número de éxitos en nextracciones o pruebas” cuando solo hay dos posibles resultados “éxito” o “fracaso”; Las extracciones son independientes y la probabilidad de éxito permanece constante e igual a p. Función de Probabilidad Binomial:
( )( )
=+=−
=valoresotrosparaqp
nxparaxnqxpnx
xp0
1,,2,1,0 Λ
La Media (µ) de la Distribución Binomial se obtiene de multiplicar el número de extracciones o pruebas n por la probabilidad de éxito p.
( ) npXE ==µ

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 71
La Varianza (var o σ2) de la Distribución Binomial se calcula multiplicando en número de extracciones o pruebas n por la probabilidad de éxito p por la probabilidad de fracaso q.
( ) npqXV ==2σ
Ejercicios de Distribución Binomial
Ejercicio 1 La probabilidad de que cierta clase de componente resista a una prueba de choque dada es de 3/4. Encuentre la probabilidad de que resistan exactamente dos de los cuatro componentes que se prueban: Solución: Suponga que las pruebas son independientes, n = 4, x = 2 y como p = ¾
para cada una de las cuatro pruebas, obtenemos: Formula a utilizar:
( )( )
=+=−
=valoresotrosparaqp
nxparaxnqxpnx
xp0
1,,2,1,0 Λ
Sustitución de valores:
( )2=xp =12827
41
43
!2!2!4
41
43
24 22242
=
=
−
Ejercicio 2 ¿Cuál es la probabilidad de obtener exactamente dos sello en 6 lanzamientos de una
moneda balanceada? Solución: Suponga que los lanzamientos son independientes, n = 6, x = 2 y como p =
1/2 para cada una de los seis lanzamientos, obtenemos: Fórmula a utilizar:
( )( )
=+=−
=valoresotrosparaqp
nxparaxnqxpnx
xp0
1,,2,1,0 Λ

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 72
Sustitución de valores:
( )2=xp =6415
21
21
!4!2!6
21
21
26 42262
=
=
−
Ejercicio 3 Encuentre la probabilidad de que en una familia de cuatro hijos haya al menos un niño. Suponga que la probabilidad de nacimiento de un varón es de ½. Solución: Suponga que los nacimientos son independientes; n = 4, x =1, 2, 3, 4 y
como p = 1/2 para cada valor de x, obtenemos: Fórmula a utilizar:
( )( )
=+=−
=valores otros para0
1,,2,1,0
qpnxparaxnqxpn
xxp
Λ
Sustitución de valores:
( )1=xp =41
21
21
!3!1!4
21
21
14 31141
=
=
−
( )2=xp =83
21
21
!2!2!4
21
21
24 22242
=
=
−
( )3=xp =41
21
21
!1!3!4
21
21
34 13343
=
=
−
( )4=xp =161
21
21
!0!4!4
21
21
44 04444
=
=
−
Entonces:
p(al menos 1 niño) = p(x=1) + p(x=2)+p(x=3)+p(x=4 ) = 1615
161
41
83
41 =+++
Otro forma de hacerlo es obtener el resultado para cuando no haya ningún niño, es decir x = 0
( )0=xp =161
21
21
!4!0!4
21
21
04 40040
=
=
−

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 73
Entonces:
p(al menos 1 niño) = 1 - p(x=0) = 1615
161
1616
1611 =−=−
33..55 DDiissttrriibbuucciióónn HHiippeerrggeeoommééttrriiccaaDescribe el comportamiento de una variable aleatoria x: “número de éxitos en nextracciones o pruebas” consecutivas y sin reemplazo, de una “caja” o “urna” que contiene en total N “objetos” de los cuales D son “objetos blancos” ; cuando solo hay dos posibles resultados: “objeto blanco =éxito” u “objeto que no sea blanco = fracaso”.
Función de Probabilidad Hipergeométrica:
( )
( )( )( )
=
−−
=
valoresotros para0
,,2,1 NnparaNn
DNxn
Dx
xp
Λ
Media de la Distribución Hipergeométrica:
( )NnDXE ==µ
Varianza de la Distribución Hipergeométrica:
( )
−−==
12
NnNnpqXVσ
Desviación Estándar de la Distribución Hipergeométrica:
−−=
1NnNnpqσ

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 74
Ejercicios de Distribución Hipergeométrica Ejercicio 1: Una caja contiene 6 canicas azules y 4 canicas rojas. Se lleva a cabo un experimento en el cual se escoge al azar una canica y se observa su color. Pero la canica no se devuelve a la caja. Encuentre la probabilidad de que después de 5 pruebas del experimento, se hayan escogido 3 canicas azules. Solución: En total tenemos 10 canicas dentro de la caja por lo tanto: N = 10, si nos
interesan las canicas azules entonces D = 6; al realizar 5 pruebas del experimento, n = 5 y x= 3 representa el número de canicas azules que se desea obtener.
Formula a utilizar:
( )( )( )
( )
=
−−
=
valoresotrospara
NnparaNn
DNxn
Dx
xp
0
,,2,1 Λ
Sustitución de valores:
( )( )( )
( )( )( )( ) 21
10
)!510(!5!10
)!24(!2!4
)!36(!3!6
105
42
63
105
61035
633 =
−
−
−
==−−==xp
Ejercicio 2: Un comité de 4 personas, se selecciona aleatoriamente de una clase con 12 estudiantes de los cuales 7 son hombres. Encuentre la probabilidad de que el comité contenga exactamente 2 hombres. Solución: El total de estudiantes es 12 por lo tanto: N = 12, si nos interesan que el
comité contenga hombres entonces D = 7; n = 4 representa el número de personas en el comité y x = 2 el número de hombres que se desea integrar al comité.
Formula a utilizar:
( )( )( )
( )
=
−−
=
valoresotrospara
NnparaNn
DNxn
Dx
xp
0
,,2,1 Λ

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 75
Sustitución de valores:
( ) 424.0495210
)!412(!4!12
)!25(!2!5
)!27(!2!7
412
25
27
412
24712
27
2 ==
−
−
−
==
=
−−
==xp
Ejercicio 3 Un comité de 4 personas, se selecciona en forma aleatoria de una clase con 12 estudiantes de los cuales 7 son hombres. Encuentre la probabilidad de que el comité contenga al menos 2 hombres Solución: El total de estudiantes es 12 por lo tanto: N = 12, si nos interesan que el
comité contenga hombres entonces D = 7; n = 4 representa el número de personas en el comité y x= 2, 3, 4, el número de hombres que pueden integrar el comité.
Formula a utilizar:
( )( )( )
( )
=
−−
=
valoresotrospara
NnparaNn
DNxn
Dx
xp
0
,,2,1 Λ
Sustitución de valores:
( ) 424.0495210
)!412(!4!12
)!25(!2!5
)!27(!2!7
412
25
27
412
24712
27
2 ==
−
−
−
=
=
−−
==xp
( ) 354.0495175
)!412(!4!12
)!15(!1!5
)!37(!3!7
412
15
37
412
34712
37
3 ==
−
−
−
=
=
−−
==xp
( ) 070.049535
)!412(!4!12
)!05(!0!5
)!47(!4!7
412
05
47
412
44712
47
4 ==
−
−
−
=
=
−−
==xp
Entonces:
p(al menos 2 hombres) = p(x=2)+p(x=3)+p(x=4 ) = 848.0495420
49535
495175
495210 ==++

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 76
Otro forma de resolverlo es, obtener los resultados para cuando haya uno o ningún hombre, es decir x = 0, 1 y la suma de estos, restarlos a la unidad.
p(al menos 2 hombres)= 1 - 848.0152.01495751
412
14712
17
412
04712
07
=−=−=
−−
+
−−
33..55..11 AApprrooxxiimmaacciióónn ddee llaa hhiippeerrggeeoommééttrriiccaa ppoorr llaa BBiinnoommiiaallCuando n es mucho menor que D < N, se puede usar la distribución binomial considerando p = D/N.
Función de aproximación de la hipergeométrica a la Binomial:
( ) ( ) xnqxpnxxp
N−=
→αlím
33..66 DDiissttrriibbuucciióónn GGeeoommééttrriiccaa..
Determina la probabilidad de que en x extracciones consecutivas aparezcan las primeras (x-1)-ésimas extracciones como “fracaso” y la x-ésima extracción como “éxito”; cuando las extracciones son con reemplazo y la probabilidad de éxito es constante e igual a p.
Función de Probabilidad Geométrica:
( ) pxqpqqqqxp 1−== Λ
Media de la Distribución Geométrica:
( )p
XE 1==µ
Varianza de la Distribución Geométrica:

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 77
( ) 22
pqXV ==σ
Desviación Estándar de la Distribución Geométrica:
2pq=σ
Ejercicios de Distribución Geométrica: Ejercicio 1 Supongamos de que la probabilidad de que un cohete alcance un objetivo es p=0.2 y el cohete se dispara repetidamente hasta alcanzar el objetivo. Encuentre la probabilidad de que 4 o más cohetes serán requeridos para alcanzar finalmente el objetivo. Solución: x=4, representa el número mínimo de cohetes. Si p =0.2, entonces q = 1-p
=0.8
Formula a utilizar: ( ) 1−== xqqqqqxp Λ
Sustitución de valores: ( ) 512.038.0148.04 ⋅==−=>=xp
Ejercicio 2 Se sabe que en un cierto proceso de fabricación, en promedio, uno de cada 100 artículos está defectuoso. ¿Cuál es la probabilidad de que el quinto artículo que se inspecciona, sea el primer defectuoso que se encuentra?
Solución: x=5, representa la posición del primer artículo defectuoso y si en promedio
1 de cada 100 artículos está defectuoso, entonces p =0.01, y por lo tanto q= 1-p =0.99
Formula a utilizar: ( ) pxqpqqqqxp 1−== Λ
Sustitución de valores:
( ) 0096.001.096.001.0499.001.01599.05 ⋅=⋅=
=
−==xp

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 78
Ejercicio 3 En “tiempo ocupado” un conmutador telefónico está muy cerca de su capacidad, por lo que los usuarios tienen dificultades al hacer sus llamadas. Puede ser de interés conocer el número de intentos necesarios a fin de conseguir un enlace telefónico. Suponga que p = 0.05 es la probabilidad de conseguir un enlace durante el tiempo ocupado. Nos interesa conocer la probabilidad de que se necesiten seis intentos para una llamada exitosa.
Solución: X=6, representa el número de intentos para obtener una llamada exitosa. Si p =0.05, q = 1-p =0.95
Formula a utilizar:
( ) pxqpqqqqxp 1−== Λ
Sustitución de valores:
( ) 00385.0)05.0)(77.0(05.0595.005.01695.06 ⋅==
=
−==xp
33..77 DDiissttrriibbuucciióónn MMuullttiinnoommiiaall..
Determina la probabilidad de que se obtengan “x1 objetos blancos” , “x2 objetos negros”, … “xk objetos azules” cuando se tienen n extracciones consecutivas con reemplazo de una “caja” que contiene “n1 objetos blancos” , “n2 objetos negros”, … “nk objetos azules” y donde p1 = n1/N, p2 = n2/N,…pk = nk/N; n1+n2+…+nk= N .
Función de Probabilidad Multinomial:
( ) knkp
np
np
knnnn
knnnf ΛΛ
Λ 22
11!!2!1
!,,2,1 =

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 79
33..88 DDiissttrriibbuucciióónn ddee PPooiissssoonn
Se puede utilizar como una aproximación para calcular la probabilidad de una variable aleatoria binomial x; donde λ = np para n grandes y p pequeñas Función de Probabilidad Poisson:
( )
=
−
=valoresotrospara
xparaxex
xp0
,,2,1!
Λλλ
Media de la Distribución Poisson:
( ) λµ == XE
Varianza de Distribución Poisson:
( ) λσ == XV2
Desviación Estándar de Distribución Poisson:
λσ =
Ejercicios de Distribución Poisson: Ejercicio 1 Durante un experimento de laboratorio el número promedio de partículas radioactivas que pasan a través de un contador en un milisegundo es cuatro. ¿Cuál es la posibilidad de que seis partículas entren al contador en un milisegundo dado?
Solución: λ=4, representa el número de partículas que entran en un milisegundo y
x=6, es el número de partículas de las cuales se busca la probabilidad que entren.

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 80
Formula a utilizar:
( )
=
−
=0
,,2,1!
Λxparaxex
xpλλ
Sustitución de valores:
( ) 1042.0720
0210587.75720
)018315.0)(4096(!6
4646 ===−
== exp
Ejercicio 2 Supóngase que el 2% de los artículos producidos por una fábrica están defectuosos. Encuentre la probabilidad P de que haya 3 artículos defectuosos en una muestra de 100 artículos. Solución: λ=2, se obtiene de multiplicar (n)(p) en donde n = 100 y p = 0.2; x=3, es el
número de artículos de las cuales se busca la probabilidad de que sean defectuosos.
Formula a utilizar:
( )
=
−
=0
,,2,1!
nxparaxex
xp Λλλ
Sustitución de valores:
( ) 180.06
08268372.16
)13535.0)(8(!3
2323 ===−
== exp
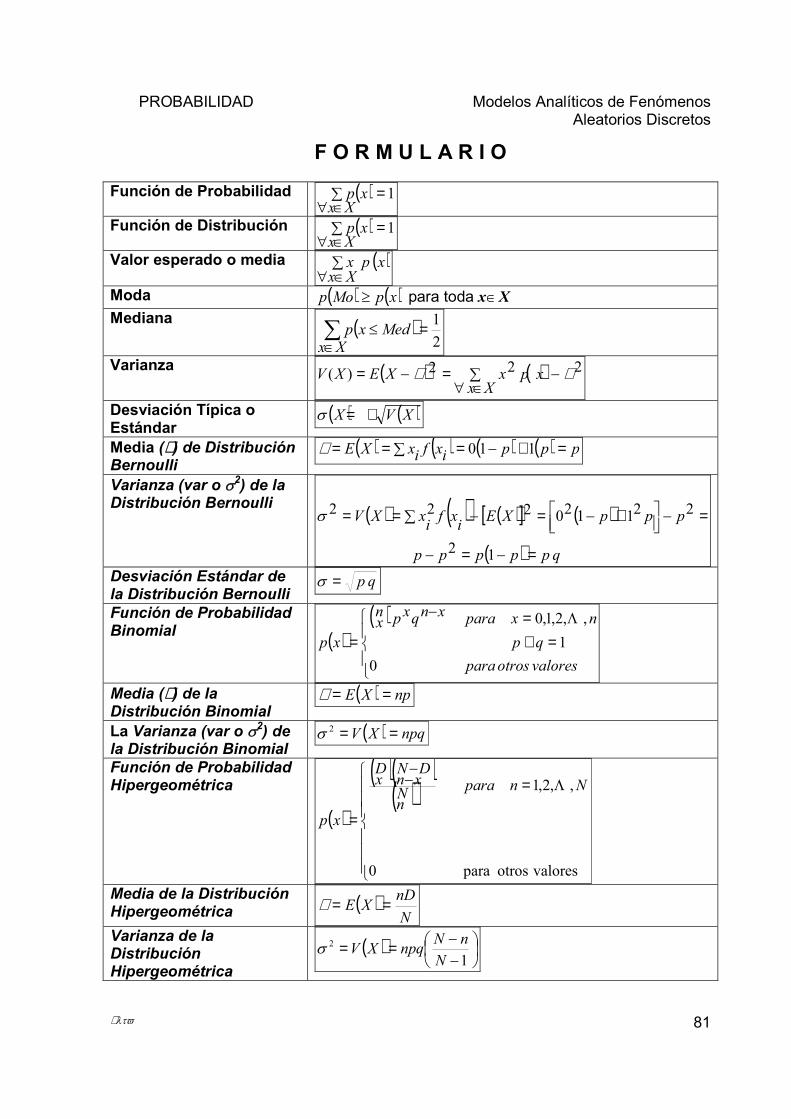
PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 81
F O R M U L A R I O
Función de Probabilidad ( ) 1=∑∈∀ Xx
xp
Función de Distribución ( ) 1=∑∈∀ Xx
xp
Valor esperado o media ( )∑∈∀ Xx
xpx
Moda ( ) ( )xpMop ≥ para toda x∈XMediana ( )
21=
∈≤∑
XxMedxp
Varianza ( ) ( ) 222)( µµ −∑∈∀
=−=Xx
xpxXEXV
Desviación Típica o Estándar
( ) ( )XVX +=σ
Media (µ) de Distribución Bernoulli
( ) ( ) ( ) ( ) pppixfixXE =+−=∑== 110µ
Varianza (var o σ2) de la Distribución Bernoulli ( ) ( ) ( )[ ] ( )
( ) qppppp
pppXEixfixXV
=−=−
=−
+−=−∑==
12
221120222σ
Desviación Estándar de la Distribución Bernoulli
qp=σ
Función de Probabilidad Binomial ( )
( )
=+=−
=valoresotrosparaqp
nxparaxnqxpnx
xp0
1,,2,1,0 Λ
Media (µ) de la Distribución Binomial
( ) npXE ==µ
La Varianza (var o σ2) de la Distribución Binomial
( ) npqXV ==2σ
Función de Probabilidad Hipergeométrica
( )
( )( )( )
=
−−
=
valoresotros para0
,,2,1 NnparaNn
DNxn
Dx
xp
Λ
Media de la Distribución Hipergeométrica ( )
NnDXE ==µ
Varianza de la Distribución Hipergeométrica
( )
−−==
12
NnNnpqXVσ
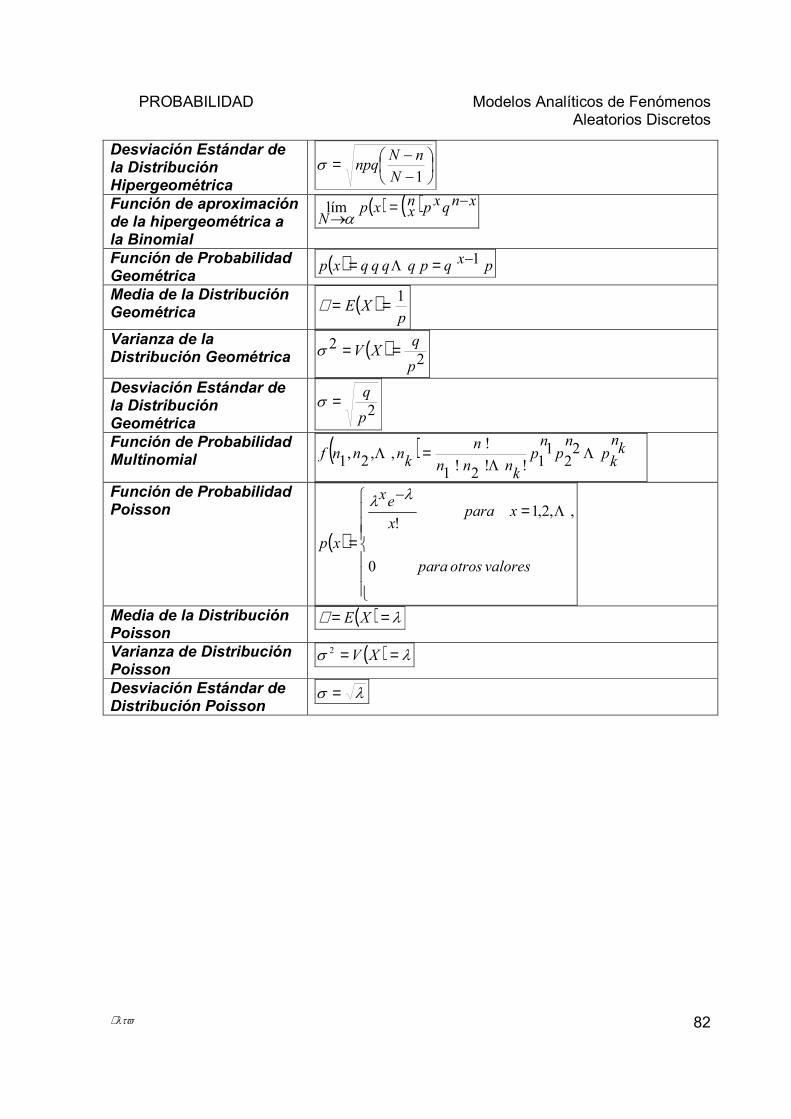
PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Discretos
µλτϖ 82
Desviación Estándar de la Distribución Hipergeométrica
−−=
1NnNnpqσ
Función de aproximación de la hipergeométrica a la Binomial
( ) ( ) xnqxpnxxp
N−=
→αlím
Función de Probabilidad Geométrica ( ) pxqpqqqqxp 1−== Λ
Media de la Distribución Geométrica ( )
pXE 1==µ
Varianza de la Distribución Geométrica ( ) 2
2pqXV ==σ
Desviación Estándar de la Distribución Geométrica
2pq=σ
Función de Probabilidad Multinomial ( ) kn
kpn
pn
pknnn
nknnnf Λ
ΛΛ 2
21
1!!2!1
!,,2,1 =
Función de Probabilidad Poisson
( )
=
−
=valoresotrospara
xparaxex
xp0
,,2,1!
Λλλ
Media de la Distribución Poisson
( ) λµ == XE
Varianza de Distribución Poisson
( ) λσ == XV2
Desviación Estándar de Distribución Poisson
λσ =

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 83
MMooddeelloossAAnnaallííttiiccooss ddeeFFeennóómmeennooss
AAlleeaattoorriioossCCoonnttiinnuuooss
4.1 Definición de variable aleatoria contínua. 4.2 Función de densidad y acumulativa. 4.3 Valor esperado, varianza y desviación estándar. 4.4 Distribución Uniforme y Exponencial. 4.5 Distribución Normal.
4.5.1 Aproximación de la Binomial a la Normal. 4.6 Teorema de Chebyshev.
4 MODELOS ANALÍTICOS DE FENÓMENOS ALEATORIOS CONTINUOS
44..11 DDeeffiinniicciióónn ddee vvaarriiaabbllee aalleeaattoorriiaa ccoonnttíínnuuaa..
Variable aleatoria: Es la correspondencia que se establece entre el conjunto de los resultados de experimento aleatorio y el conjunto de los números reales.

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 84
Variable aleatoria contínua (V.A.C): Es la correspondencia que se establece entre el conjunto de los resultados de un experimento aleatorio y el conjunto de los números reales; puede tomar cualquier valor dentro de un determinado intervalo.
44..22 FFuunncciióónn ddee ddeennssiiddaadd yy aaccuummuullaattiivvaa..
La Función de densidad de probabilidad, permite asignar a los valores de una variable aleatoria comprendidos en un intervalo su correspondiente probabilidad. La Función de distribución, es la probabilidad de que una variable aleatoria continua, tome valores menores o iguales que un cierto valor real t; también se le conoce como probabilidad acumulada. Función de Distribución Acumulada:
( ) ( ) ( )∫∞−
=≤=t
dxxftXPtF
44..33 VVaalloorr eessppeerraaddoo,, vvaarriiaannzzaa yy ddeessvviiaacciióónn eessttáánnddaarr..
44..33..11 MMeeddiiddaass ddee TTeennddeenncciiaa CCeennttrraall::
Muestran el comportamiento medio o promedio de los valores que puede tomar la variable aleatoria.
4.3.1.1 Valor esperado o media de una V.A.C Es la integral en todo el dominio de los valores de la variable aleatoria, multiplicados por su función de densidad de probabilidad.
( ) ( )∫∞+
∞−== dxxfxXEµ
4.3.1.2 Moda de una V. A. C. Es el valor de la variable aleatoria para la cual se cumple que la función de densidad de probabilidades adquiere el máximo valor.
( ) ( ) MoacercanoxtodoparaxfMof ≥

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 85
4.3.1.3 Mediana de una V. A. C. Es el número real para el que se cumple que la probabilidad acumulada de una variable aleatoria es menor o igual que 0.5.
( ) ( )MedFMedF XX −== 150.0
44..33..22 MMeeddiiddaass ddee VVaarriiaacciióónn::
Permiten estudiar la dispersión o variabilidad que tienen los diferentes valores de la variable aleatoria. 4.3.2.1 Varianza de una V. A. C. Es la integral en todo el dominio de los valores de la diferencia entre la variable aleatoria y la media elevada al cuadrado, multiplicada por la función de densidad de probabilidad. Si su valor es pequeño, indica una concentración o poca dispersión de los datos, alrededor de su valor medio y, por el contrario, si valor es alto, indica una dispersión considerable de los datos respecto al valor central.
( ) ( ) ( )∫∞+
∞−=== dxxfxXEXV 222δ
4.3.2.2 Desviación Típica o Estándar de una V.A.C. Es la raíz cuadrada de la varianza.
( ) ( )XVX +=δ
44..44 DDiissttrriibbuucciióónn UUnniiffoorrmmee yy EExxppoonneenncciiaall..
44..44..11 DDiissttrriibbuucciióónn UUnniiffoorrmmee..
Describe el comportamiento probabilístico de una variable aleatoria que toma cualquier valor en el intervalo cerrado continuo [ ]ba, ; de tal modo que su valor en ese intervalo es una constante.

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 86
Función de Distribución Uniforme:
( ) ∫−=
t
a
dxab
tF 1
Función de Densidad de la Distribución Uniforme:
( )
≤≤−
=valoresotrospara
bxaparaab
xf0
1
Media de distribución Uniforme:
( )2
baXE +==µ
Varianza de la distribución Uniforme:
( ) ( )12
22 abXV −==σ
44..44..22 DDiissttrriibbuucciióónn EExxppoonneenncciiaall..
Es una función de densidad de probabilidades que en el contexto de los procesos de “llegadas” aleatorias, describe el comportamiento probabilístico de los tiempos entre dos “llegadas” consecutivas.
Función de Distribución Exponencial:
( ) λλλ /
0
1 tt
x edxetF −− −== ∫

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 87
Función de Densidad Exponencial:
( )
≥=
−
valoresotrospara
tparaetf
t
__0
0λλ
Media de distribución Exponencial:
( )θ
µ 1== XE
Varianza de la distribución Exponencial:
( ) 22 1
θσ == XV
Desviación típica de la distribución Exponencial:
( )θ
µσ 1=== XE
Ejercicios de Distribución Exponencial Ejercicio 1: Suponiendo que la duración de X (en días) de cierto componente C es exponencial, donde λ = 120. Encuentre la probabilidad de que el componente C dure menos de 60 días.
Solución: La probabilidad de que C dure menos de 60 días, nos indica entonces que el valor de t = 60, los valores de e y λ son ya conocidos, λ=120 y e es constante≈ 2.81
Formula a utilizar:
( ) λλλ /
0
1)( tt
x edxetFtXP −− −===< ∫Sustitución de valores:
393.081.2111)60()60( 2/1120/60/ =−=−=−==< −−− eeFXP t λ

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 88
Resultado: La probabilidad de que C dure menos de 60 días = P(X<60) = 0.393 = 39.3%
Ejercicio 2: Suponiendo que la duración de X (en días) de cierto componente C es exponencial, donde λ = 120, Encuentre la probabilidad de que el componente C dure más de 240 días.
Solución: La probabilidad de que C dure más de 240 días, nos indica entonces que el valor de t = 240, los valores de e y λ son ya conocidos, λ=120 y e es constante≈ 2.81
Formula a utilizar:
( ) λλλλ //
0
)1(111)( ttt
x eedxetFtXP −−− =−−=−=−=> ∫
Sustitución de valores:
135.081.2)1(1)240(1)240( 2120/240/ ===−−=−=> −−− eeFXP t λ
Resultado: La probabilidad de que C dure más de 240 días = P(X>240) = 0.135 = 13.5%
44..55 DDiissttrriibbuucciióónn NNoorrmmaall..
Tiene un papel particularmente importante en las aplicaciones prácticas de la teoría de la probabilidad. Una característica importante es que es posible especificarla de manera amplia por medio de dos parámetros: la media µ y la desviación estándar σ .
La curva que se forma es simétrica con respecto a la media µ de la distribución, tiene forma de campana y se extiende de ∞− a ∞+ . El área total bajo la curva es 100% o 1.00.

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 89
Función de Densidad de Probabilidad Normal:
( )2
21
21
−
−
= σµ
πσ
x
exf
Función de la Distribución Normal:
( ) dxetFt
x
∫ ∞−
−
−=
2
21
21 σ
µ
πσ
Función de Densidad de Probabilidad Normal Estandarizada:
( )2
21
21 z
ezf−
=π
Donde: σ
µ−= xz
Función de la Distribución Normal Estandarizada:
( ) zdetzt
2
21
21 −
∞−∫=π
φ Donde: σ
µ−= xz
Media de la distribución Normal:
( ) µ=xE
Varianza de la distribución Normal:
( ) 2222 σµµσ =−+=XV

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 90
Ejercicios de Distribución Normal Ejercicio 1: Supongamos que X es la distribución normal N(70,4). Encuentre la probabilidad de que X sea menor o igual a 74. P(X<=74)
Solución: X tiene media µ = 70 y desviación estándar σ= 4 =2. Se transforma x2=74 en unidades estándar de la siguiente manera:
Formula a utilizar:
( ) )(21
21
2
21
2
21
2
22 zdzexdexXP
zzx
xφ
ππσσ
µ
===<=−
∞−
−−
∞− ∫∫
Donde: σ
µ−= 2xz
Sustitución de valores:
22
7074 =−=z
( ) 9772.0)2(21
22174
2
21
22
27074
21
74====<=
−
∞−
−
−
∞− ∫∫ φππ
dzedxeXPz
φ (2) = 0.9772 se obtiene de las tablas de áreas bajo la curva normal estandarizada representada en la siguiente curva:
Resultado: La probabilidad de que X sea menor o igual a 74. P(X<=74) = 0.9772 = 97.72%
Ejercicio 2: Supongamos que X es la distribución normal N(70,4). Encuentre la probabilidad de que X sea mayor a 74. P(X>74). Solución: X tiene media µ = 70 y desviación estándar σ= 4 =2. Se transforma x2=74
en unidades estándar de la siguiente manera:
0.9772

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 91
Formula a utilizar:
( ) )(1211
2111 2
2
212
21
222
22 zdzexdexXP
zzx
xφ
ππσσ
µ
−=−=−=<=−−
∞−
−
−
∞− ∫∫
Donde: σ
µ−= 2
2xz
Sustitución de valores:
22
70742 =−=z
( ) 0228.09772.01)2(1211
2211741
2
21
22
27074
21
74 2 =−=−=−=−=<=−−
∞−
−
−
∞− ∫∫ φππ
dzedxeXPz
φ (2) = 0.9772 se obtuvo de las tablas de áreas bajo la curva normal estandarizada, representada en la siguiente curva
Resultado: La probabilidad de que X sea mayor a 74. P(X>74). = 0.0228 = 2.28%
Ejercicio 3: Supongamos que X es la distribución normal N(70,4). Encuentre la probabilidad de que X sea mayor o igual a 68 y X sea menor o igual a 74. P(68<=X<=74). Solución: X tiene media µ = 70 y desviación estándar σ= 4 =2. Se transforma x1=68
y x2=74 en unidades estándar de la siguiente manera:
Formula a utilizar:
( ) )()(21
21
1
2
12
2
21
2
1
2
21
21 zzdzexdexxxPzz
z
xx
xφφ
ππσσ
µ
−===<=<=−
−
−
∫∫
0.9772
00.0228

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 92
Donde: σ
µ−= xz
Sustitución de valores:
12
70681 −=−=z y 2
27074
2 =−=z
( ) 8185.01587.09772.0)1()2(21
217468
2
21
2
1
2
21
74
68=−=−−===<=<=
−
−
−
−
∫∫ φφππσ
σµ
dzexdexPz
x
Donde: φ (2) = 0.9772 φ (-1) = 0.1587 Se obtuvieron de las tablas de áreas bajo la curva normal estandarizada, representada en la curva anexa y se obtiene de la resta de φ (2) - φ (-1) debido a que se busca la probabilidad de que X se encuentre entre estos dos valores.
Resultado: La probabilidad de que X sea mayor o igual a 68 y X sea menor o igual a 74. P(68<=X<=74). = φ (2) - φ (-1) = 0.9772 - 0.1587 = 0.8185 = 81.85%
44..55..11 AApprrooxxiimmaacciióónn ddee llaa BBiinnoommiiaall aa llaa NNoorrmmaall..
Cuando el número de pruebas es grande y la probabilidad de éxito muy pequeña, se puede usar la función de densidad de probabilidades normal con parámetros µ y σpara calcular probabilidades binomiales, usando las equivalencias µ = np y σ = qpnque son respectivamente la media y la desviación estándar de la binomial. Dado que cuando se emplea la distribución binomial para calcular la probabilidad de que “x” tome por ejemplo entre 1 y 3, se hace el cálculo para x = 1, x = 2 y x = 3 y posteriormente se suman todos los resultados para conocer p(1 x 3).
Para hacer la aproximación de la Binomial a la Normal, tenemos solo dos valores para x, el que representa el límite inferior y el que representa el límite superior y estos se
0.1587 0.9772
0.8185

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 93
modifican en ½ punto restándoselo al límite inferior y sumándolo al límite superior de tal manera que si deseamos conocer p(1 x 3) x1=1 -0.5 , x2 =3 +0.5 por tanto x1=0.5 , x2 =3.5 y estos datos se sustituyen en la ecuación para obtener el valor de z.
σµ−= xz
Ejercicio 1: Suponga que el 4% de la población mayor de 65 años tiene la enfermedad de Alzheimer. Suponga que se toma una muestra aleatoria de 3500 personas mayores de 65. Encuentre la probabilidad de que: a) 150 o más de ellos tengan la enfermedad. b) Entre 100 y 120 inclusive tengan la enfermedad. Solución De acuerdo a los datos que se proporcionan, se hace una aproximación por la binomial y a partir del tamaño de la muestra n, de la probabilidad de éxito p y la probabilidad de fracaso q se calcula la media µ y la desviación estándar σ antes del cálculo de z.
n = 3500 p = 0.04 q = 0.96 14004.03500 =×== npµ
59.115931.114.13496.004.03500 ≈==××== npqσ
a) ¿Cuál es la Probabilidad de que 150 o más de ellos tengan la enfermedad? Dado que también se debe considerar el 150, se disminuye medio punto a la variable x por tanto: x = 150-0.5 = 149.5
82.08194.059.115.9
59.111405.149
≈==−=−=σ
µxz
7939.0)82.0( ==zφ
7939.0)82.0( ==zφ , se obtuvo de las tablas de áreas bajo la curva normal estandarizada, dado que la tabla proporciona la probabilidad menor o igual a z, a la unidad se le resta el valor obtenido de la tabla para conocer el resultado.
%212061.07939.01)150( ≈=−=≥xp
la )150( ≥xp se representa en la siguiente curva
0.7939
0
0.2061

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 94
b) ¿Cuál es la Probabilidad de que entre 100 y 120 inclusive tengan la enfermedad? Los límites se modifican en ½ punto, se le resta al límite inferior y se le suma al límite superior
x1 = 100-0.5 = 99.5 x2 = 120+0.5 = 120.5
49.34943.359.11
5.4059.111405.991
1 −≈−=−=−=−=σ
µxz 0002.0)49.3( 1 =−=zφ
68.16824.159.11
5.1959.11
1405.12022 −≈−=−=−=−=
σµxz 0465.0)68.1( 2 =−=zφ
0002.0)49.3( 1 =−=zφ y 0465.0)68.1( 2 =−=zφ se obtuvieron de la tabla de áreas bajo la curva normal estandarizada, y para calcular la probabilidad )120100( ≤≤ xp se obtiene restando a )( 2zφ el valor de )( 1zφ .
0463.00002.00465.0)()()120100( 12 =−=−=≤≤ zzxp φφ
La )120100( ≤≤ xp se representa en la siguiente curva
44..66 TTeeoorreemmaa ddee CChheebbyysshheevv..
Este teorema, a partir de la media µ y la varianza σ2; permite calcular un límite para la probabilidad de que una variable aleatoria esté en un cierto intervalo. Desigualdad o Teorema de Chebyshev:
( )2
11h
hXhP −≥+≤≤− σµσµ
Ejercicio 1 Sea X una variable aleatoria con media µ = 40 y desviación estándar σ = 5. Utilice la desigualdad de Chebyshev para encontrar un valor b para el cual P (40 – b ≤ X ≤ 40 + b) ≥ 0.95
0.0002 0.0465 00.0463

PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 95
Solución Fórmula a utilizar:
2
11)(h
hXhP −≥+≤≤− σµσµ
Sustitución de valores:
Primero resuelva 1 - 2
1h
= 0.95 para h de la siguiente manera:
2
195.01h
=− 2
105.0h
= 2005.012 ==h 47.420 ==h
Por desigualdad de Chebyshev b = hσ = (4.47)(5) = 22.3 Donde:
P (40 – 22.3 ≤ X ≤ 40 + 22.3) ≥ 1 - 2
1h
P (17.7 ≤ X ≤ 62.3) ≥ 0.95
F O R M U L A R I O
Función de Distribución Acumulada ( ) ( ) ( )∫
∞−
=≤=t
dxxftXPtF
Valor esperado o media de una V.A.C ( ) ( )∫
∞+
∞−== dxxfxXEµ
Moda de una V. A. C. ( ) ( ) MoacercanoxtodoparaxfMof ≥Mediana de una V. A. C. ( ) ( )MedFMedF XX −== 150.0Varianza de una V. A. C.
( ) ( ) ( )∫∞+
∞−=== dxxfxXEXV 222δ
Desviación Típica o Estándar de una V.A.C.
( ) ( )XVX +=δ
Función de Distribución Uniforme ( ) ∫−
=t
a
dxab
tF 1
Función de Densidad de la Distribución Uniforme
( )
≤≤−
=valoresotrospara
bxaparaab
xf0
1
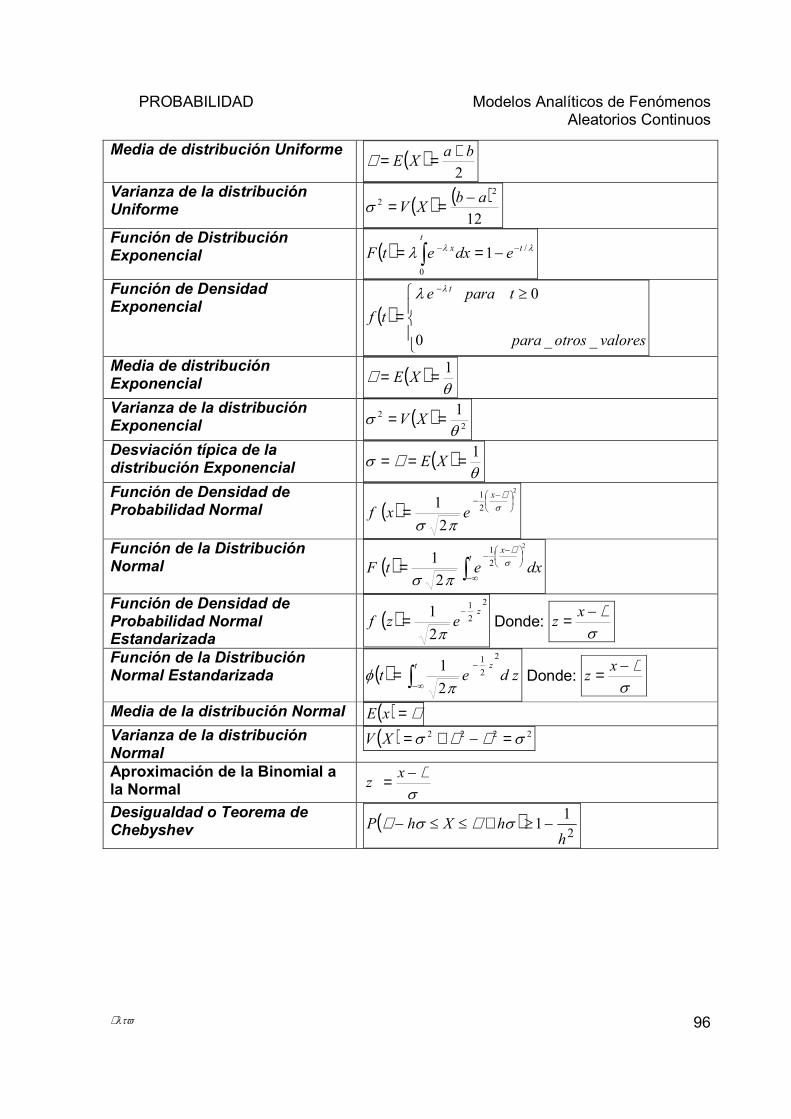
PROBABILIDAD Modelos Analíticos de Fenómenos Aleatorios Continuos
µλτϖ 96
Media de distribución Uniforme ( )2
baXE +==µ
Varianza de la distribución Uniforme ( ) ( )
12
22 abXV −==σ
Función de Distribución Exponencial ( ) λλλ /
0
1 tt
x edxetF −− −== ∫Función de Densidad Exponencial ( )
≥=
−
valoresotrospara
tparaetf
t
__0
0λλ
Media de distribución Exponencial ( )
θµ 1== XE
Varianza de la distribución Exponencial ( ) 2
2 1θ
σ == XV
Desviación típica de la distribución Exponencial ( )
θµσ 1=== XE
Función de Densidad de Probabilidad Normal ( )
2
21
21
−
−
= σµ
πσ
x
exf
Función de la Distribución Normal ( ) dxetF
tx
∫ ∞−
−
−=
2
21
21 σ
µ
πσFunción de Densidad de Probabilidad Normal Estandarizada
( )2
21
21 z
ezf−
=π
Donde: σ
µ−= xz
Función de la Distribución Normal Estandarizada ( ) zdet
zt2
21
21 −
∞−∫=π
φ Donde: σ
µ−= xz
Media de la distribución Normal ( ) µ=xEVarianza de la distribución Normal
( ) 2222 σµµσ =−+=XV
Aproximación de la Binomial a la Normal σ
µ−= xz
Desigualdad o Teorema de Chebyshev ( )
211
hhXhP −≥+≤≤− σµσµ

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 97
RReeggrreessiióónn yyCCoorrrreellaacciióónn
SSiimmppllee5.1 Regresión lineal simple y curvilínea.
5.1.1 Distinguir entre variable dependiente e independiente. 5.1.2 Definir ecuación de regresión y cual es su aplicación. 5.1.3 Aplicar el método de mínimos cuadrados para determinar
la recta, parábola o curva que mejor se ajuste a un conjunto de datos.
5.2 Correlación.
5 REGRESIÓN Y CORRELACIÓN SIMPLE 55..11 IInnttrroodduucccciióónn..
Para el estudio de la primera unidad se recopilaron datos pertenecientes a una sola variable y por consecuencia, de la observación se obtenía una medida, por eso a estas variables se les llama variables unidimensionales Sin embargo, frecuentemente para realizar el estudio estadístico de una observación se requieren un par de variables de las cuáles nos interesa conocer cómo se relacionan, a éstas les llamaremos variable estadística bidimensional. Como ejemplo de variables bidimensionales podemos mencionar el estudio estadístico de: Estatura y peso de un grupo de personas.

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 98
Ingreso y gastos de una familia con determinadas características. Calificaciones en Física y Matemáticas de los alumnos de segundo semestre de la especialidad de Ingeniería Industrial. Pulso y temperatura de los enfermos de un hospital. Si se toman por separado, cada una es una variable unidimensional por ejemplo: la estatura la podemos representar por la variable X y tomará valores x1, x2, x3, ..., xn, mientras que al peso le llamaremos Y que toma los valores y1, y2, y3, ..., yn de tal manera que si estudiamos al mismo tiempo la estatura (X) y el peso (Y) como variables bidimensionales las representamos por el par (Xi,Yi) y los valores se representan en pares ( x1 , y1 ); ( x2 , y2 ); ( x3 , y3 ); ...; ( xn , yn )
La estatura y peso de 12 individuos que practican fútbol:
Individuo Estatura en Mt. (Xi)
Peso en Kg (Yi)
1 1.75 70 2 1.70 70 3 1.80 78 4 1.68 70 5 1.70 75 6 1.80 78 7 1.70 68 8 1.74 73 9 175 70
10 1.70 78 11 1.80 78 12 1.75 70
55..11..11 TTaabbllaa ddee FFrreeccuueenncciiaa AAbbssoolluuttaa ppaarraa VVaarriiaabblleess BBiiddiimmeennssiioonnaalleess..
De los datos recopilados:
(1.75 , 70) ; (1.70 , 70) ; (1.80 , 78) ; (1.68 , 70) ; (1.70 , 75) ; (1.80 , 78); (1.70 , 68) ; (1.74 , 73) ; (1.75 , 70) ; (1.70 , 78) ; (1.80 , 78) ; (1.75 , 70)
Se observa que el par (1.75, 70) aparece 3 veces; es decir, hay 3 jugadores que miden 1.75 mts. de estatura y pesan 70 Kg. Al igual que en las variables unidimensionales, al número de veces que la variable toma un valor; en este caso al número de veces que el par (xi,yi) toman el mismo valor; se le llama frecuencia absoluta fij y podemos construir la tabla de frecuencias de la siguiente manera:

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 99
TABLA DE FRECUENCIAS ABSOLUTAS
(Xi,Yi) fij (1.75 , 70) 3 (1.70 , 70) 1 (1.80 , 78) 3 (1.68 , 70) 1 (1.70 , 75) 1 (1.70 , 68) 1 (1.74 , 73) 1 (1.70 , 78) 1
Σ 12
55..11..22 TTaabbllaa ddee DDoobbllee EEnnttrraaddaa..
La tabla de frecuencias absolutas suele ser muy larga y poco ágil, en su lugar se utiliza la tabla de doble entrada que consiste en distribuir las frecuencias absolutas en una cuadrícula, donde fij representa la frecuencia absoluta del par ( xi, yj ).
TABLA DE DOBLE ENTRADA
XY X1 X2 . . . XnY1 f11 f21 . . . fn1 Y2 f12 f22 . . . fn2 . . . . . . . . . . . . . . .Ym f1m f2m . . . fnm
La tabla de doble entrada de los datos recabados queda de siguiente manera:
TABLA DE DOBLE ENTRADA
XY 1.68 1.70 1.74 1.75 1.8068 -- 1 -- -- -- 70 1 1 -- 3 -- 73 -- -- 1 -- -- 75 -- 1 -- -- -- 78 -- 1 -- -- 3
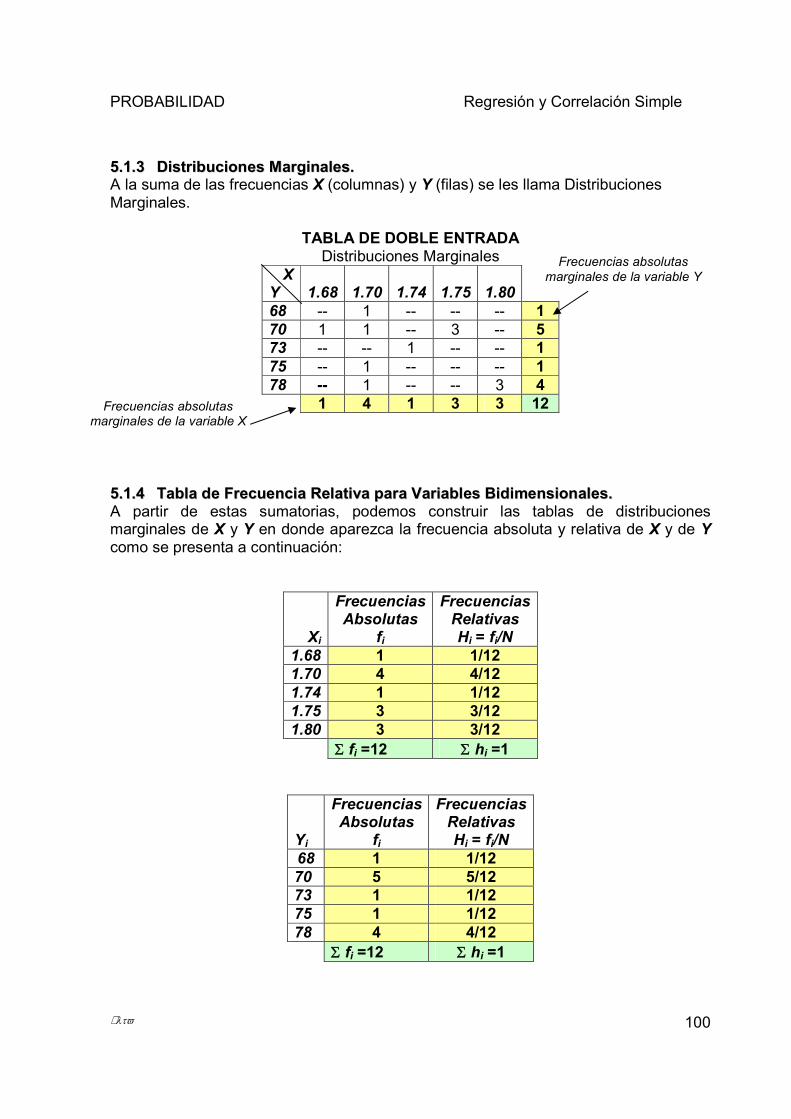
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 100
55..11..33 DDiissttrriibbuucciioonneess MMaarrggiinnaalleess..A la suma de las frecuencias X (columnas) y Y (filas) se les llama Distribuciones Marginales.
TABLA DE DOBLE ENTRADA Distribuciones Marginales
XY 1.68 1.70 1.74 1.75 1.8068 -- 1 -- -- -- 170 1 1 -- 3 -- 573 -- -- 1 -- -- 175 -- 1 -- -- -- 178 -- 1 -- -- 3 4
1 4 1 3 3 12
55..11..44 TTaabbllaa ddee FFrreeccuueenncciiaa RReellaattiivvaa ppaarraa VVaarriiaabblleess BBiiddiimmeennssiioonnaalleess..A partir de estas sumatorias, podemos construir las tablas de distribuciones marginales de X y Y en donde aparezca la frecuencia absoluta y relativa de X y de Ycomo se presenta a continuación:
Xi
Frecuencias Absolutas
fi
Frecuencias Relativas Hi = fi/N
1.68 1 1/12 1.70 4 4/12 1.74 1 1/12 1.75 3 3/12 1.80 3 3/12
Σ fi =12 Σ hi =1
Yi
Frecuencias Absolutas
fi
Frecuencias Relativas Hi = fi/N
68 1 1/12 70 5 5/12 73 1 1/12 75 1 1/12 78 4 4/12
Σ fi =12 Σ hi =1
Frecuencias absolutas marginales de la variable Y
Frecuencias absolutas marginales de la variable X

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 101
55..11..55 FFuunncciioonneess eessttaaddííssttiiccaass:: mmeeddiiaa,, vvaarriiaannzzaa,, ddeessvviiaacciióónn yy ccoovvaarriiaannzzaa..
Estas distribuciones marginales son obviamente distribuciones unidimensionales y, por tanto, se pueden calcular las medias, varianzas, desviaciones típicas, etc., por separado, apliquemos los conocimientos que adquirimos en el capítulo 1 y recordemos cómo se calculan estas funciones estadísticas las cuales nos serán de utilidad para el cálculo de la covarianza y algunos cálculos que se realizarán posteriormente.
Medias:
n
xfx
ii
n
i)(
1∑
==n
yfy
ii
n
i)(
1∑
==
Varianzas:
1
)(1
2
2
−
−=∑
=
n
xxfs
n
iii
x1
)(1
2
2
−
−=∑
=
n
yyfs
n
iii
y
Desviaciones Típicas:
1
)(1
2
−
−=∑
=
n
xxfs
n
iii
x 1
)(1
2
−
−=∑
=
n
yyfs
n
iii
y
Covarianza: La Covarianza Cov(x,y), también se identifica como sxy; mide la correlación que hay entre las variables “X” y “Y”; una covarianza grande y positiva (sxy > 0) está asociada a una fuerte correlación positiva mientras que una covarianza grande y negativa (sxy < 0) está asociada a una correlación negativa fuerte, el signo de la covarianza determina el sentido de la correlación (positivo o negativo), mientras que la fuerza está dada por el valor absoluto de la covarianza a mayor valor mayor correlación y por consiguiente, la nube de puntos será más estrecha. Si X y Y son independientes, sxy = 0. Debemos tener en cuenta que los puntos que están más alejados en la nube influyen más en su valor y signo que los centrales.

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 102
La covarianza se calcula a través de la siguiente fórmula:
n
yyxxs
n
iii
yx
∑=
−−= 1
))((
La cual al ser despejada se sintetiza hasta llegar a:
yxn
yxs
n
iii
yx −=∑
=1
Esta última facilita su cálculo Ejemplo: La siguiente tabla muestra la lluvia caida X (medida en Mm.) en diferentes regiones y los kilos de trigo cosechados por hectárea (Y) en cada una de estas regiones.
mmn
xfx
ii
n
x 7005
3500)(
1 ===∑
=
Kgn
xfy
ii
n
x 800.105
54)(
1 ===∑
=
Una vez que se conocen las medias de las variables “X” y “Y” procederemos a calcular la covarianza con las dos fórmulas proporcionadas anteriormente:
CALCULO DE COVARIANZA CON LA FORMULA ORIGINAL
Observación xi yi1 800 12 2 700 11 3 500 9 4 900 12 5 600 10
Sumas 3,500 54
Observación xi yi xxi − yyi − ( xxi − )( yyi − )1 800 12 100 1,2 120 2 700 11 0 0,2 0 3 500 9 -200 -1,8 360 4 900 12 200 1,2 240 5 600 10 -100 -0,8 80
Sumas 3,500 54 800 700=x 800.10=y

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 103
1605
800))((
1 ==−−
=∑
=
n
yyxxs
n
iii
yx
CALCULO DE COVARIANZA CON FORMULA SINTETIZADA
160756077201 =−=−=∑
= yxn
jxs
n
iii
yx
Obsérvese que con cualquiera de las dos formulas, se llega al mismo resultado y dado que el resultado de la covarianza (sxy = 160) es positivo y alejado del cero, se presume que se tiene una correlación positiva la cual a simple vista, se puede corroborar a través de la representación gráfica de los valores x, y en el plano cartesiano.
55..11..66 DDiiaaggrraammaa ddee DDiissppeerrssiióónn oo NNuubbee ddee PPuunnttooss..
Después de que se haya hecho la recolección y clasificación de los datos a través de las tablas; el siguiente paso a realizar en el estudio de la relación entre dos variables es la representación gráfica de los datos en el plano cartesiano, definiendo cada punto en las coordenadas (x,y), a este gráfico se les conoce como Diagrama de Dispersión o Nube de Puntos y dependiendo de la forma que toma la “nube de puntos” es el nombre que reciben, si la nube no toma ninguna forma definida, se debe a que no existe correlación entre las variables de la observación; por el contrario, si la nube es estirada y sus puntos se pueden encerrar en una elipse, lo cerrado de esa elipse nos indica la fuerza de la correlación lineal. A continuación se presentan algunos ejemplos de Diagramas de Dispersión.
Observación xi yiii yx
1 800 12 9600 2 700 11 7700 3 500 9 4500 4 900 12 10800 5 600 10 6000
Sumas 3,500 54 38600 700=x 800.10=y
7560800.10*700 ==yx 77205
386001 ===∑
=
n
jxs
n
iii
yx
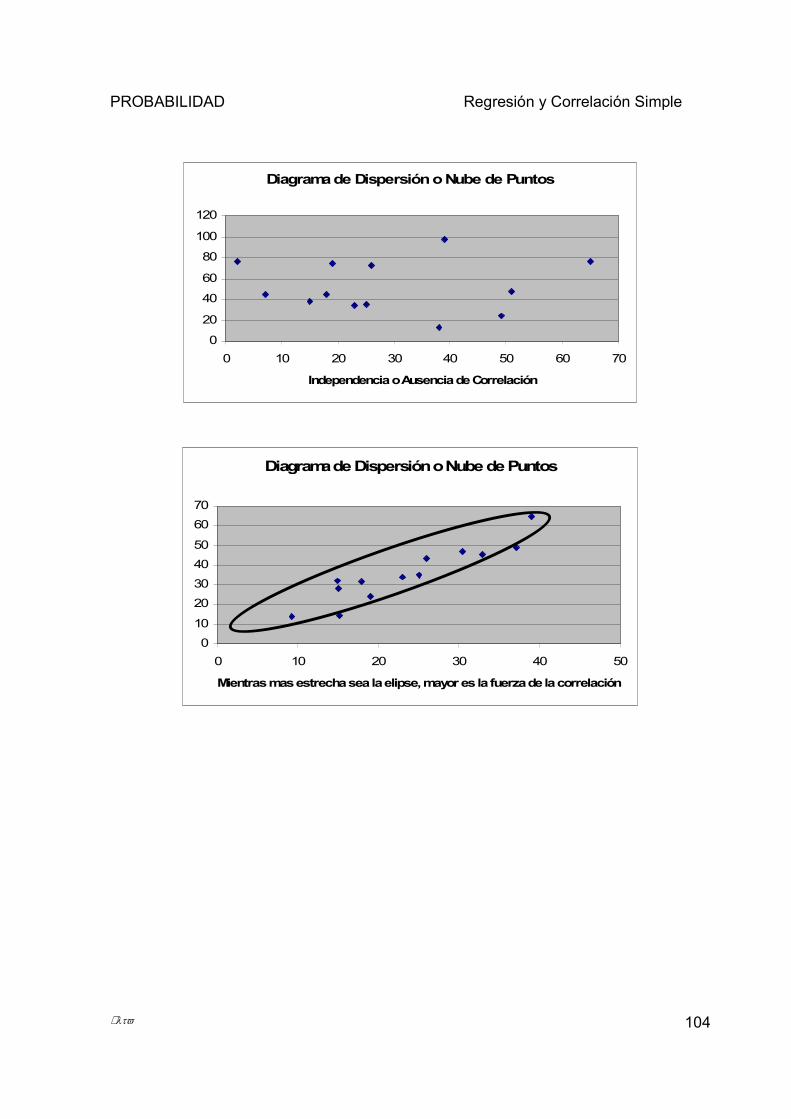
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 104
Diagrama de Dispersión o Nube de Puntos
0
20
40
60
80
100
120
0 10 20 30 40 50 60 70
Independencia o Ausencia de Correlación
Diagrama de Dispersión o Nube de Puntos
0
10
20
30
4050
6070
0 10 20 30 40 50
Mientras mas estrecha sea la elipse, mayor es la fuerza de la correlación
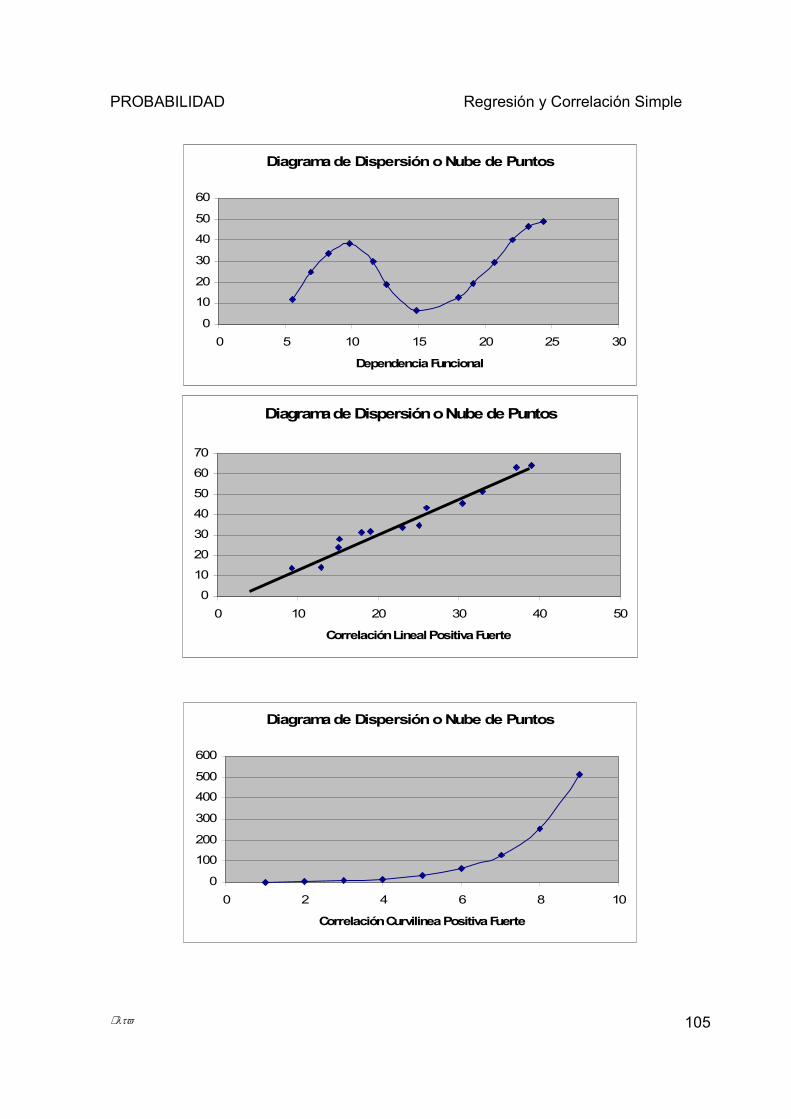
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 105
Diagrama de Dispersión o Nube de Puntos
0
10
20
30
40
50
60
0 5 10 15 20 25 30
Dependencia Funcional
Diagrama de Dispersión o Nube de Puntos
0
10
20
30
40
50
60
70
0 10 20 30 40 50
Correlación Lineal Positiva Fuerte
Diagrama de Dispersión o Nube de Puntos
0
100
200
300
400
500
600
0 2 4 6 8 10
Correlación Curvilinea Positiva Fuerte
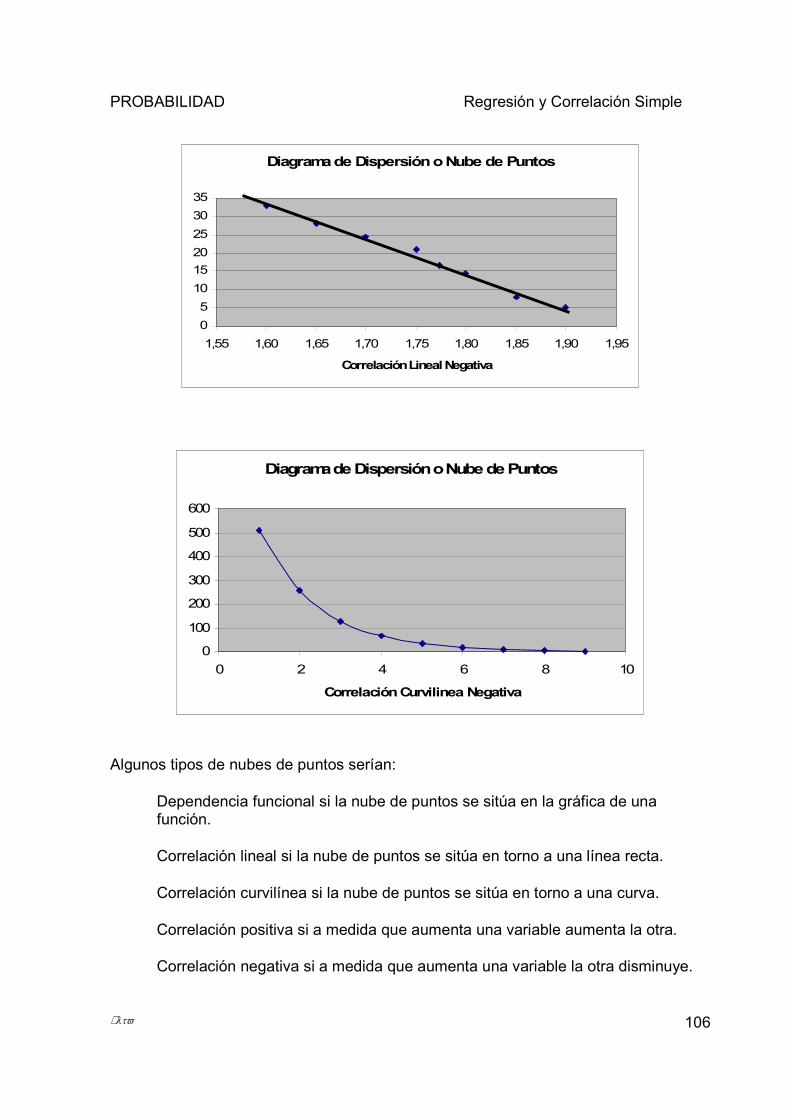
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 106
Diagrama de Dispersión o Nube de Puntos
05
101520253035
1,55 1,60 1,65 1,70 1,75 1,80 1,85 1,90 1,95
Correlación Lineal Negativa
Diagrama de Dispersión o Nube de Puntos
0
100
200
300
400
500
600
0 2 4 6 8 10
Correlación Curvilinea Negativa
Algunos tipos de nubes de puntos serían:
• Dependencia funcional si la nube de puntos se sitúa en la gráfica de una función.
• Correlación lineal si la nube de puntos se sitúa en torno a una línea recta.
• Correlación curvilínea si la nube de puntos se sitúa en torno a una curva.
• Correlación positiva si a medida que aumenta una variable aumenta la otra.
• Correlación negativa si a medida que aumenta una variable la otra disminuye.

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 107
• Independencia o ausencia de correlación.
La naturaleza y grado de relación entre las variables X y Y pueden ser analizadas por dos técnicas: Regresión y Correlación que aunque están relacionadas tienen propósitos diferentes e interpretaciones diferentes y por lo mismo, no debe sustituirse una por la otra. El análisis de regresión puede ser lineal o curvilíneo y también lineal simple y lineal múltiple; el lineal siempre se ocupa de dos variables y el múltiplo de tres o mas, nosotros nos enfocaremos al estudio de la regresión lineal y la correlación entre variables
55..22 RReeggrreessiióónn lliinneeaall ssiimmppllee yy ccuurrvviillíínneeaa..
La palabra regresión surgió a finales del siglo XVII cuando Sir Francis Galton, científico ingles dedicado a investigaciones genéticas, trató de establecer la relación entre las características de padre e hijo. Al comparar la altura de los padres, notó que de padres altos, generalmente sus hijos no alcanzaban su estatura mientras que de padres bajos generalmente los hijos superaban la estatura, lo que lo llevó a concluir que las características genéticas tendían a “regresar” a un valor medio de la población. El análisis de regresión se emplea en situaciones experimentales cuando se desea determinar la forma en la que se relacionan las variables cuando hay un fenómeno de causa – efecto en donde la causa es la variable independiente (x) y el efecto la variable dependiente (y); su objetivo principal es el de estimar el valor de una variable dependiente correspondiente al valor dado de otra variable independiente.
55..22..11 DDiissttiinngguuiirr eennttrree vvaarriiaabbllee ddeeppeennddiieennttee ee iinnddeeppeennddiieennttee..
Cuando se realiza el estudio estadístico de una observación que requieren variables estadística bidimensional, puede ser que sean:
Independientes: Cuando una de las variables no tiene ninguna relación con la otra por ejemplo: la cantidad de lluvia en mm que cae en temporada de lluvias, es independiente de la cosecha que se recoge por lo tanto, la cantidad de lluvia en mm es una variable independiente, otro ejemplo de variables independientes sería la cosecha que levanta una familia y el número de integrantes de la misma, en este caso, no tienen nada que ver entre si las dos variables.
Dependientes: cuando el valor de una de las variables, se relaciona con el valor de la otra variables, retomando el ejemplo de la lluvia y la cosecha, podemos asegurar que la cosecha si es dependiente de los mm de lluvia por lo tanto, la lluvia es la variable independiente y la cosecha la variable dependiente.

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 108
55..22..22 DDiiffeerreenncciiaa eennttrree DDeeppeennddeenncciiaa FFuunncciioonnaall yy DDeeppeennddeenncciiaa EEssttaaddííssttiiccaa..
Cuando la relación entre las variables “x” y “y”se da de manera proporcional y para conocer el valor de una de ellas se debe obtener a partir de una fórmula matemática que contenga el valor de la otra variable se dice que existe dependencia funcional por ejemplo:
“La reproducción de la bacteria "salmonella typhimurium" se realiza dividiéndose cada bacteria en otras dos cada hora. Partiendo de una bacteria, existe una fórmula matemática que nos permite calcular el número de bacterias en función del tiempo que pasa:
y = 2x
Esta dependencia entre el tiempo y el número de bacterias es una dependencia funcional.”2
Observación Tiempo en horas (Xi)
Número de bacterias(Yi=2x
i )1 1 22 2 43 3 84 4 16 5 5 32 6 6 64 7 7 128 8 8 256 9 9 512
En cambio, habrá casos en los que el valor de una variable tenga relación con el valor de la otra pero no de manera proporcional como por ejemplo, sabemos que una persona entre más estatura tiene, mayor es el número de calzado que usa, sin embargo, no podemos establecer una regla que nos diga que el número de calzado que usa la persona representa el 15% de su estatura ni nada por el estilo, simplemente sabemos que por lo general, entre más alta es la persona, el número de calzado es mayor. Esto se conoce como dependencia estadística.
La dependencia o correlación es positiva cuando a mayor valor de una, le corresponde también mayor valor de la otra.
2 Lectus Vergara, Estadística Nivel II
x tiempo en horas y número de bacterias
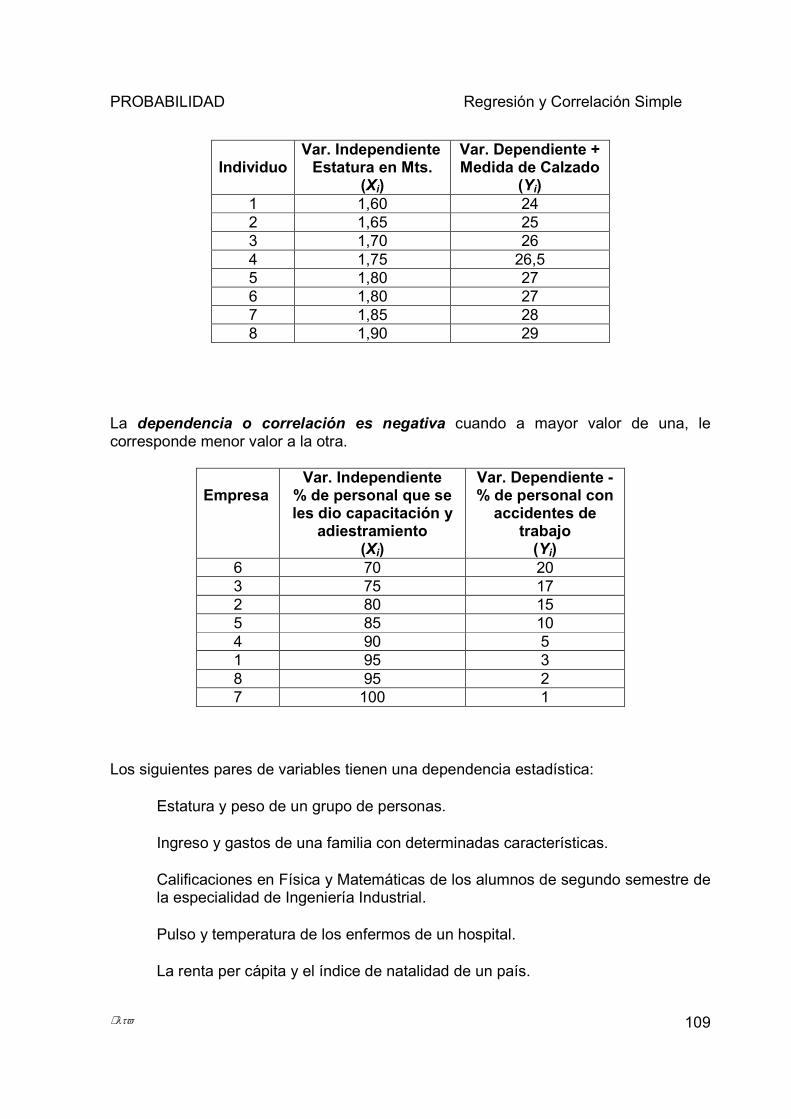
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 109
IndividuoVar. Independiente
Estatura en Mts. (Xi)
Var. Dependiente + Medida de Calzado
(Yi)1 1,60 24 2 1,65 25 3 1,70 26 4 1,75 26,5 5 1,80 27 6 1,80 27 7 1,85 28 8 1,90 29
La dependencia o correlación es negativa cuando a mayor valor de una, le corresponde menor valor a la otra.
Empresa Var. Independiente
% de personal que se les dio capacitación y
adiestramiento (Xi)
Var. Dependiente - % de personal con
accidentes de trabajo
(Yi)6 70 20 3 75 17 2 80 15 5 85 10 4 90 5 1 95 3 8 95 2 7 100 1
Los siguientes pares de variables tienen una dependencia estadística:
• Estatura y peso de un grupo de personas.
• Ingreso y gastos de una familia con determinadas características.
• Calificaciones en Física y Matemáticas de los alumnos de segundo semestre de la especialidad de Ingeniería Industrial.
• Pulso y temperatura de los enfermos de un hospital.
• La renta per cápita y el índice de natalidad de un país.
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 110
• La cantidad de dinero que una empresa se gasta en publicidad y las ventas que obtiene.
• La temperatura media anual y la latitud de las capitales de los países de la
Comunidad Económica Europea.
55..22..33 DDeeffiinniirr eeccuuaacciióónn ddee rreeggrreessiióónn yy ccuuááll eess ssuu aapplliiccaacciióónn..
A la función que describe lo mejor posible la relación existente entre dos variables se la denomina ecuación de regresión, y a su gráfica, línea de regresión. En ocasiones, entre dos variables existe un cierto grado de dependencia, es decir, una relación. Así, por ejemplo, la estatura y el peso de los individuos, la natalidad y el grado de desarrollo de un país, la edad y la propensión a adquirir una determinada enfermedad, etc. De una manera general, llamaremos regresión a la teoría que trata de exponer, mediante una ecuación matemática, la relación que existe entre las dos variables X y Y; de esta forma podemos obtener con cierta aproximación el valor de una de las variables conociendo el de la otra.
Diagrama de Dispersión o Nube de Puntos
010
2030
4050
6070
0 10 20 30 40 50
Correlación Lineal Positiva Fuerte
La ecuación que relacione los dos variables puede ser de diversos tipos; La lineal: baxy += Parabólica: cbxaxy ++= 2
Cúbica: dcxbxaxy +++= 23 Exponencial: xcay =
A la línea que mejor se ajuste al diagrama de dispersión (nube de puntos). Se llama línea de regresión. Si los puntos de la nube están alineados o casi alineados como en esta gráfica, el trazado de la línea de regresión se puede hacer a “ojo”, a esto se le llama Método Intuitivo, pero cuando la nube está muy dispersa es mejor buscar un método más científico.
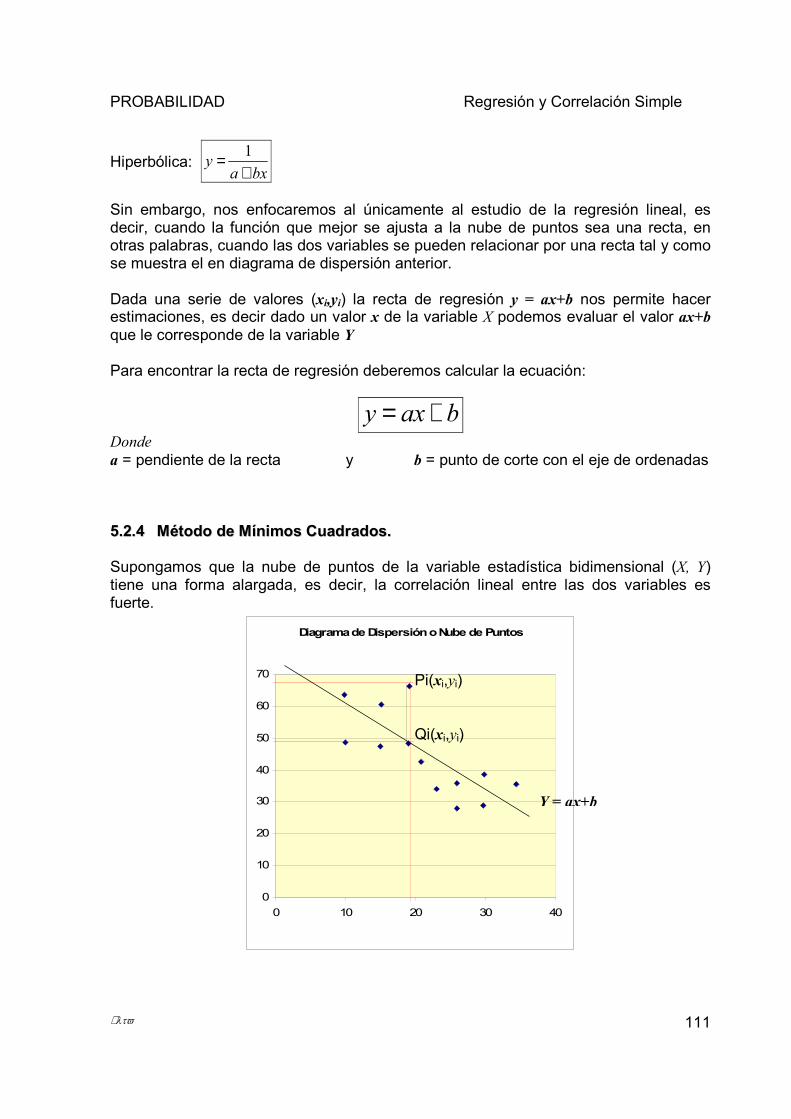
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 111
Hiperbólica: bxa
y+
= 1
Sin embargo, nos enfocaremos al únicamente al estudio de la regresión lineal, es decir, cuando la función que mejor se ajusta a la nube de puntos sea una recta, en otras palabras, cuando las dos variables se pueden relacionar por una recta tal y como se muestra el en diagrama de dispersión anterior. Dada una serie de valores (xi,yi) la recta de regresión y = ax+b nos permite hacer estimaciones, es decir dado un valor x de la variable X podemos evaluar el valor ax+b que le corresponde de la variable Y
Para encontrar la recta de regresión deberemos calcular la ecuación:
baxy +=Donde a = pendiente de la recta y b = punto de corte con el eje de ordenadas
55..22..44 MMééttooddoo ddee MMíínniimmooss CCuuaaddrraaddooss..
Supongamos que la nube de puntos de la variable estadística bidimensional (X, Y)tiene una forma alargada, es decir, la correlación lineal entre las dos variables es fuerte.
Diagrama de Dispersión o Nube de Puntos
0
10
20
30
40
50
60
70
0 10 20 30 40
Pi(xi,yi)
Qi(xi,yi)
Y = ax+b
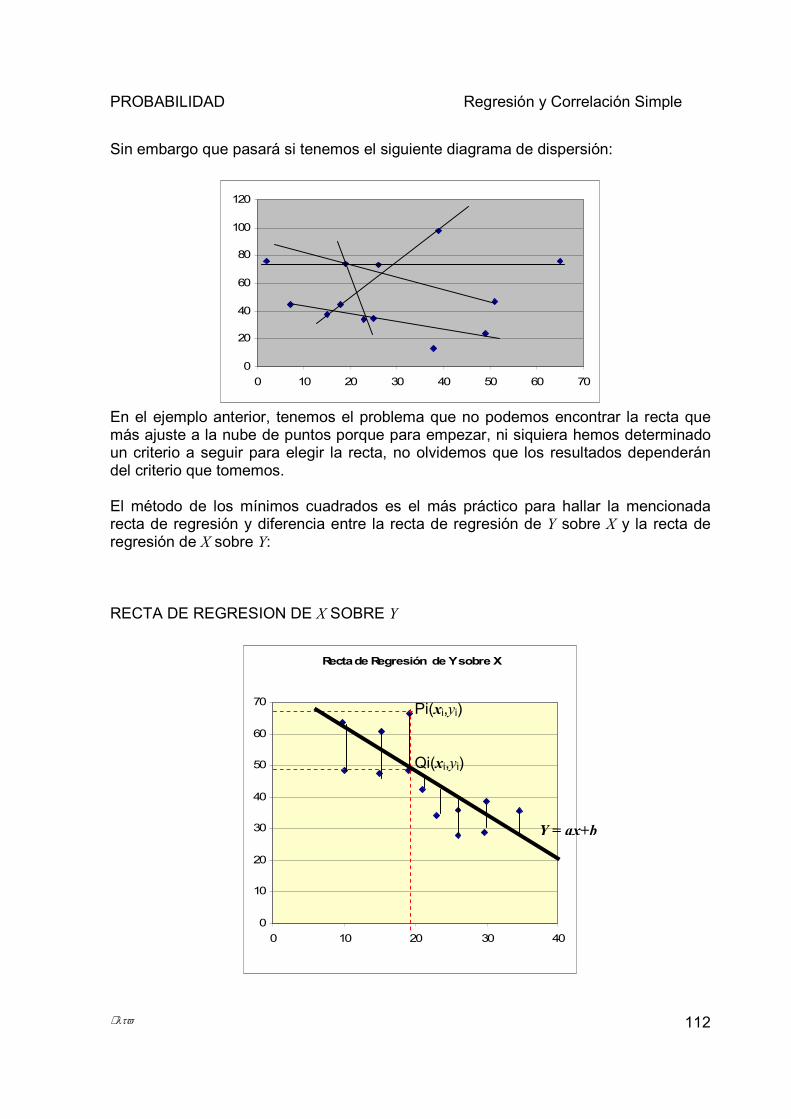
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 112
Sin embargo que pasará si tenemos el siguiente diagrama de dispersión:
0
20
40
60
80
100
120
0 10 20 30 40 50 60 70
En el ejemplo anterior, tenemos el problema que no podemos encontrar la recta que más ajuste a la nube de puntos porque para empezar, ni siquiera hemos determinado un criterio a seguir para elegir la recta, no olvidemos que los resultados dependerán del criterio que tomemos. El método de los mínimos cuadrados es el más práctico para hallar la mencionada recta de regresión y diferencia entre la recta de regresión de Y sobre X y la recta de regresión de X sobre Y:
RECTA DE REGRESION DE X SOBRE Y
Recta de Regresión de Y sobre X
0
10
20
30
40
50
60
70
0 10 20 30 40
Pi(xi,yi)
Qi(xi,yi)
Y = ax+b
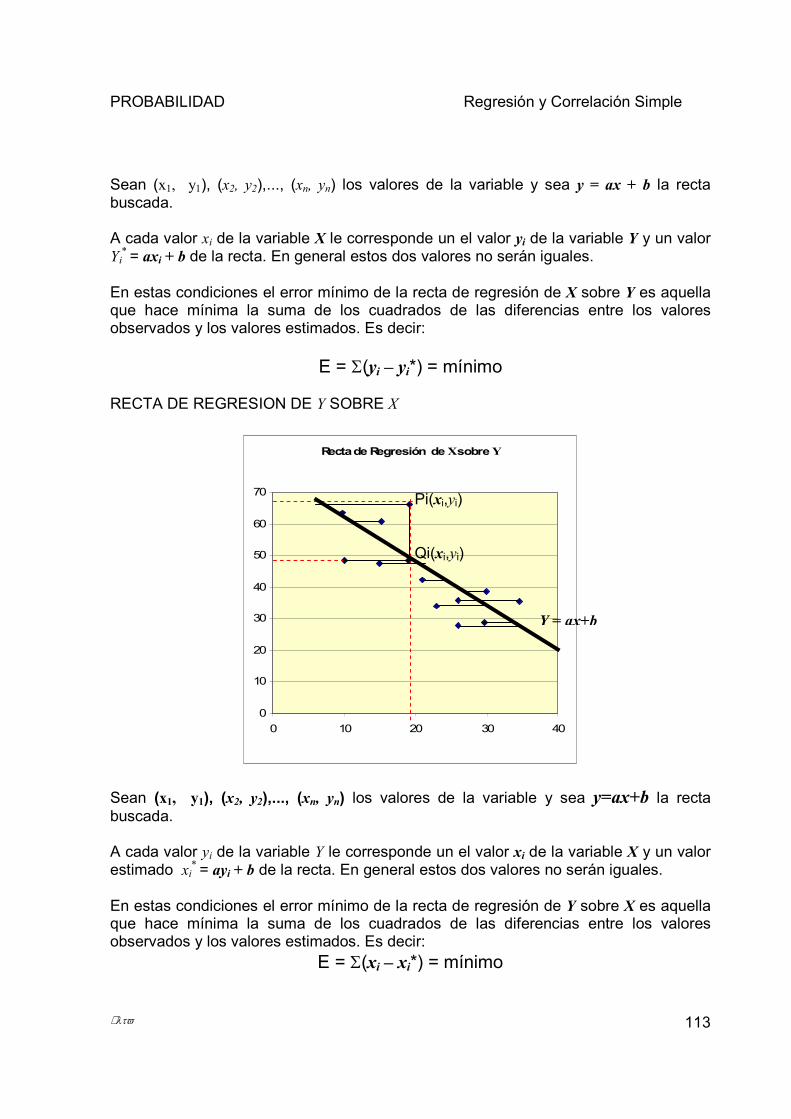
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 113
Sean (x1, y1), (x2, y2),..., (xn, yn) los valores de la variable y sea y = ax + b la recta buscada. A cada valor xi de la variable X le corresponde un el valor yi de la variable Y y un valor Yi
* = axi + b de la recta. En general estos dos valores no serán iguales. En estas condiciones el error mínimo de la recta de regresión de X sobre Y es aquella que hace mínima la suma de los cuadrados de las diferencias entre los valores observados y los valores estimados. Es decir:
E = Σ(yi – yi*) = mínimo RECTA DE REGRESION DE Y SOBRE X
Recta de Regresión de Xsobre Y
0
10
20
30
40
50
60
70
0 10 20 30 40
Sean (x1, y1), (x2, y2),..., (xn, yn) los valores de la variable y sea y=ax+b la recta buscada. A cada valor yi de la variable Y le corresponde un el valor xi de la variable X y un valor estimado xi
* = ayi + b de la recta. En general estos dos valores no serán iguales. En estas condiciones el error mínimo de la recta de regresión de Y sobre X es aquella que hace mínima la suma de los cuadrados de las diferencias entre los valores observados y los valores estimados. Es decir:
E = Σ(xi – xi*) = mínimo
Pi(xi,yi)
Qi(xi,yi)
Y = ax+b

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 114
Sea y = ax + b la recta de regresión de Y sobre X, por el método de los mínimos cuadrados se obtienen unas condiciones sobre a y b.
Σxiyi = a Σxi2 + bΣxi Σyi = aΣxi + nb
De las que resulta:
x
xy
ss
a 2=
−−= yx
ss
bx
xy2
En definitiva la recta de regresión de Y sobre X es:
( )xxss
yyx
xy −=− 2 o
−−= yx
ss
xss
yx
xy
x
xy22
Esta ecuación nos proporciona aproximadamente los valores de Y conocidos los de X.
Análogamente, se obtiene la recta de regresión de X sobre Y, que permite hallar aproximadamente los valores de X conocidos los de Y:
( )yyss
xxy
xy −=− 2 o
−−= xy
ss
yss
xy
xy
y
xy22
Los coeficientes obtenidos del cociente de la covarianza sobre la varianza:
x
xy
ss
2 yy
xy
ss
2 se llaman coeficientes de regresión.
Ejemplo: La tabla muestra la lluvia caida X (medida en mm.) en diferentes regiones y los kilos de trigo cosechados por hectárea (Y) en cada una de estas regiones. Si en una región han caido 550 mm de lluvia, ¿cuántos Kg./Ha. Se pueden recoger?

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 115
16075607720
1
=−=
−=∑
= yxn
jxs
n
iii
yx
113883.15825000
4100000
1
)(1
2
==
=
−
−=∑
=
n
xxfs
n
iii
x
3038.17.148.6
1
)(1
2
==
=
−
−=∑
=
n
yyfs
n
iii
y
El valor que conocemos es el valor de X, debemos predecir Y por lo tanto se debe obtener la recta de regresión de Y sobre X
006.025000160
2
=
=
=x
xy
ss
a
32.6)32.6(
)800.1048.4()800.10700005.0(
800.1070025000160
2
=−−=
−−=−∗−=
−−=
−−= yx
ss
bx
xy
A partir de a y b, la recta de regresión de Y sobre X se obtiene el valor de y
baxy +=
Observación xi 2)( xxi − yi 2)( yyi − ii yx
1 800 10,000 12 1.44 9600 2 700 0 11 0.04 7700 3 500 40,000 9 3.24 4500 4 900 40,000 12 1.44 10800 5 600 10,000 10 0.64 6000
Sumas 3,600 100,000 54 6.8 38600 700=x 800.10=y
7560800.10*700 ==yx 77205
386001 ==∑
=
n
jxn
iii

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 116
Si en una región han caído 550 mm. de lluvia, ¿cuántos Kg./Ha. Se pueden recoger? x = 550 a = 0.006 b = 6.32
84.932.652.3
32.65500064.0
=+=
+∗=+= baxy
Resultado: Si en una región han caido 550 mm de lluvia se espera recoger 9.84 Kg./Ha. 55..22..55 CCoonnssiiddeerraacciioonneess ssoobbrree llaa rreeccttaa ddee rreeggrreessiióónn..
Las dos rectas de regresión siempre pasan por el punto (x, y). Al calcular la recta de regresión hay que tener absolutamente clara la noción de cuál es la variable independiente (x) y cuál la dependiente (y). No son intercambiables; una cosecha puede depender de la lluvia caída, pero la lluvia no depende de la cosecha. Cuando utilizamos la recta de regresión para predecir un resultado y a partir de un valor x, corremos un riesgo; este riesgo es mayor en la medida que nos alejamos del valor central x.
La pendiente de la recta de regresión (de y sobre x), tiene el mismo signo que el coeficiente de correlación: si la correlación es directa a debe ser positiva; si es inversa, negativa. (Que a sea más o menos grande no es indicativo de que la correlación sea más o menos fuerte). El coeficiente de correlación se relaciona con las pendientes de la recta de regresión de la siguiente manera: mY = pendiente de la recta de regresión de y sobre x.
mX = pendiente de la recta de regresión de x sobre y.
55..33 CCoorrrreellaacciióónn..
El análisis de correlación nos permite medir el grado de intensidad de la asociación entre dos variables, sin importar cual es la independiente y cual es la dependiente, en este análisis las variables X y Y son vistas simplemente como variables aleatorias.

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 117
A la medida del grado de correlación entre dos variables se le llama coeficiente de correlación y se representa por ρ para la población y r para la muestra. En el modelo de correlación se asume que las variables X y Y varían conjuntamente, si la distribución es normal se llamará distribución normal bivariable; las suposiciones que constituyen un modelo de correlación lineal de variables bidimensionales son: X y Y son variables aleatorias. No deben ser designadas como dependiente e independiente puesto que esto no modifica el resultado. La población bivariable es normal si X y Y están normalmente distribuidas. La relación entre X y Y es en cierto sentido lineal, esto es que todas las medias de Yasociadas a un valor X caen sobre una línea recta que es la línea de regresión de Ysobre X e igualmente las medias de X asociadas a un valor Y caen sobre una línea recta que es la línea de regresión de X sobre Y.
55..33..11 CCooeeffiicciieennttee ddee CCoorrrreellaacciióónn ddee PPeeaarrssoonn..
A través de este coeficiente (r), es posible medir en forma objetiva el grado de la correlación lineal entre dos variables, su valor oscila entre -1 y +1 y a medida que el valor de r se acerca a 1 o -1, la correlación es más fuerte. Si el valor del coeficiente de Pearson es cercano a cero, no vale la pena hacer predicciones ni calcular la recta de regresión ya que las estimaciones que se realicen no son fiables debido a que la correlación es mas débil mientras mas cercana esté de cero.
El coeficiente de correlación lineal o coeficiente de Pearson (r), se obtiene del cociente entre la covarianza y el producto de las desviaciones típicas de las dos variables:
-1 0 1
Correlación negativa perfecta
Correlación positiva perfecta
No existe correlación
Toma mayor fuerza Toma mayor fuerza
Se debilita Se debilita
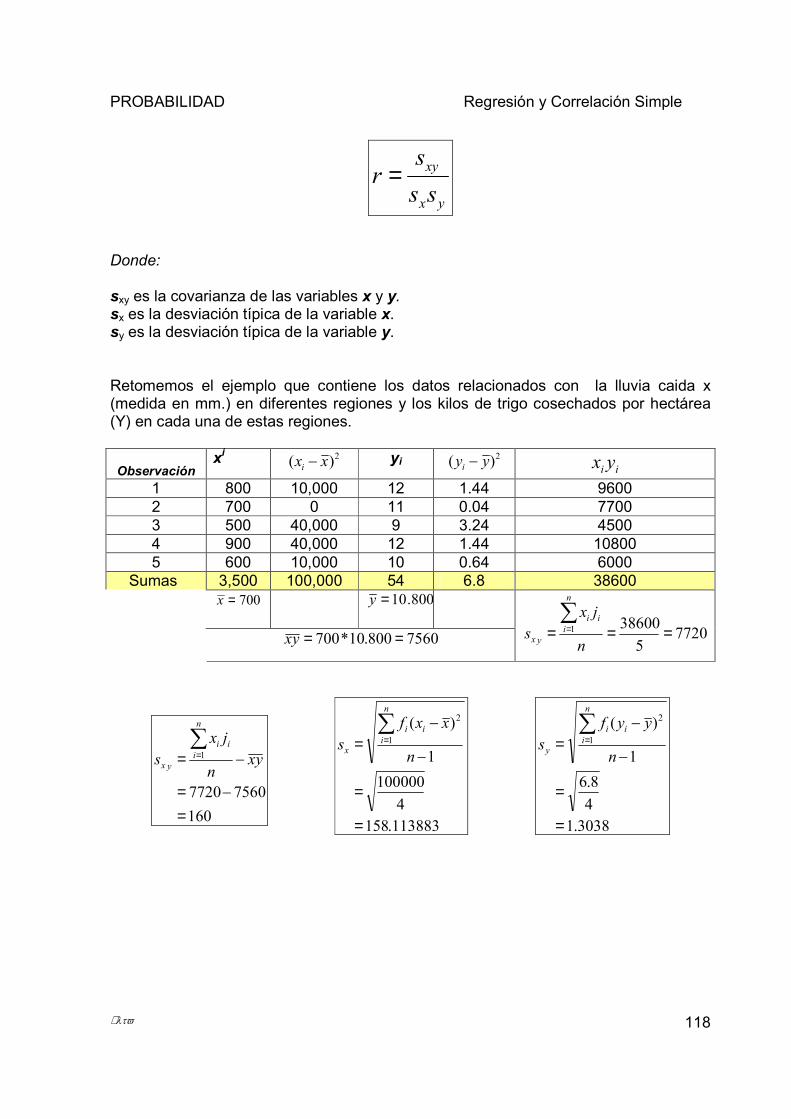
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 118
yx
xy
sss
r =
Donde: sxy es la covarianza de las variables x y y.sx es la desviación típica de la variable x.sy es la desviación típica de la variable y.
Retomemos el ejemplo que contiene los datos relacionados con la lluvia caida x (medida en mm.) en diferentes regiones y los kilos de trigo cosechados por hectárea (Y) en cada una de estas regiones.
16075607720
1
=−=
−=∑
= yxn
jxs
n
iii
yx
113883.1584
1000001
)(1
2
=
=
−
−=∑
=
n
xxfs
n
iii
x
3038.148.6
1
)(1
2
=
=
−
−=∑
=
n
yyfs
n
iii
y
Observación xi 2)( xxi − yi 2)( yyi − ii yx
1 800 10,000 12 1.44 9600 2 700 0 11 0.04 7700 3 500 40,000 9 3.24 4500 4 900 40,000 12 1.44 10800 5 600 10,000 10 0.64 6000
Sumas 3,500 100,000 54 6.8 38600 700=x 800.10=y
7560800.10*700 ==yx 77205
386001 ===∑
=
n
jxs
n
iii
yx
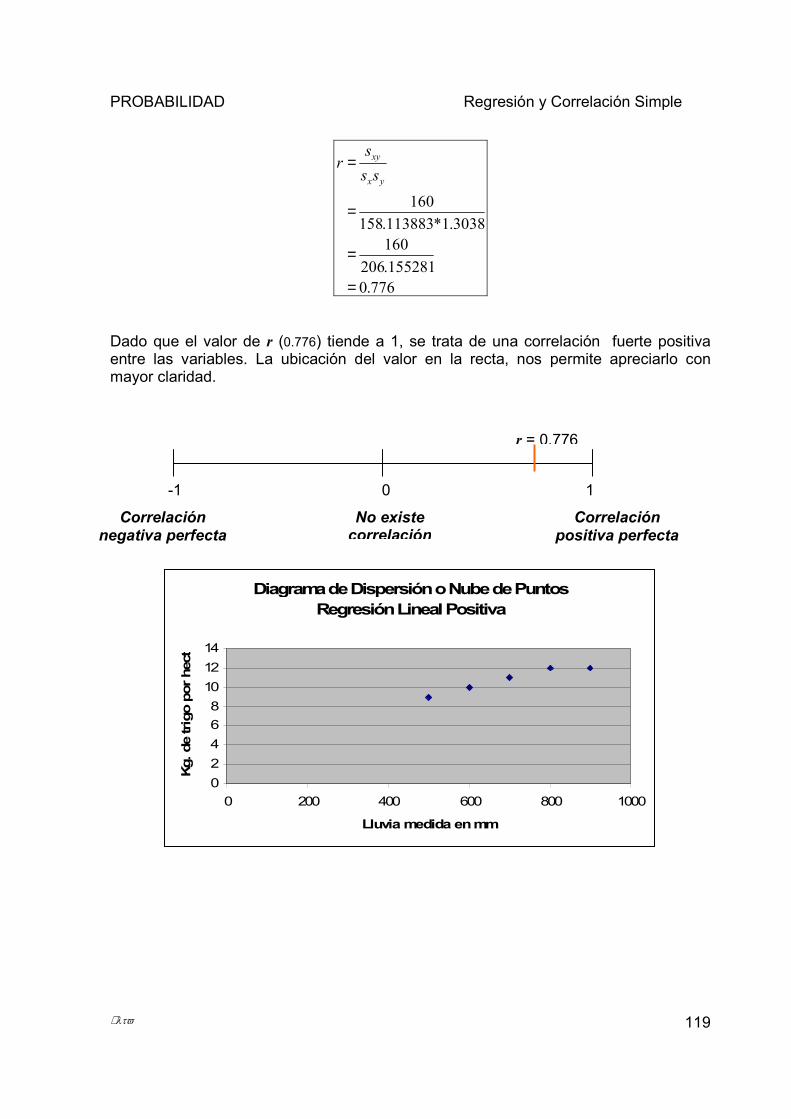
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 119
776.0155281.206160
3038.1*113883.158160
=
=
=
=yx
xy
sss
r
Dado que el valor de r (0.776) tiende a 1, se trata de una correlación fuerte positiva entre las variables. La ubicación del valor en la recta, nos permite apreciarlo con mayor claridad.
Diagrama de Dispersión o Nube de Puntos Regresión Lineal Positiva
02468
101214
0 200 400 600 800 1000
Lluvia medida en mm
Kg.
detr
igo
porh
ect
-1 0 1
Correlación negativa perfecta
Correlación positiva perfecta
No existe correlación
r = 0.776

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 120
55..44 EEjjeerrcciicciioo IInntteeggrraall
En la tabla esta reflejada la pérdida de actividad de un preparado farmacéutico en el curso del tiempo. Tiempo en meses 1 2 3 4 5 % de actividad restante 90 75 42 30 21
Paso 1. Identificación de Variables dependiente e independiente a partir de la siguiente interrogante ¿Cuál es la causa y cuál el efecto? La pérdida de actividad de un preparado farmacéutico, se debe al paso del tiempo y no al revés por lo tanto, la causa es el tiempo y el efecto es la pérdida de actividad es decir, la variable dependiente es la pérdida de actividad (y) y la independiente el tiempo (x)
Paso 2. Construcción de Tabla de Frecuencias (bidimensional), en este ejemplo no se repiten los valores por lo tanto, todas las observaciones van a tener una frecuencia = 1.
Tabla de Frecuencias
(Xi,Yi) fij(1,90) 1(2,75) 1(3,42) 1(4,30) 1(5,21) 1
Paso 3. Construcción de Tabla de Doble Entrada.
TABLA DE DOBLE ENTRADA
X
Y 1 2 3 4 590 1 -- -- -- -- 75 -- 1 -- -- -- 42 -- -- 1 -- -- 30 -- -- -- 1 -- 21 -- -- -- -- 1
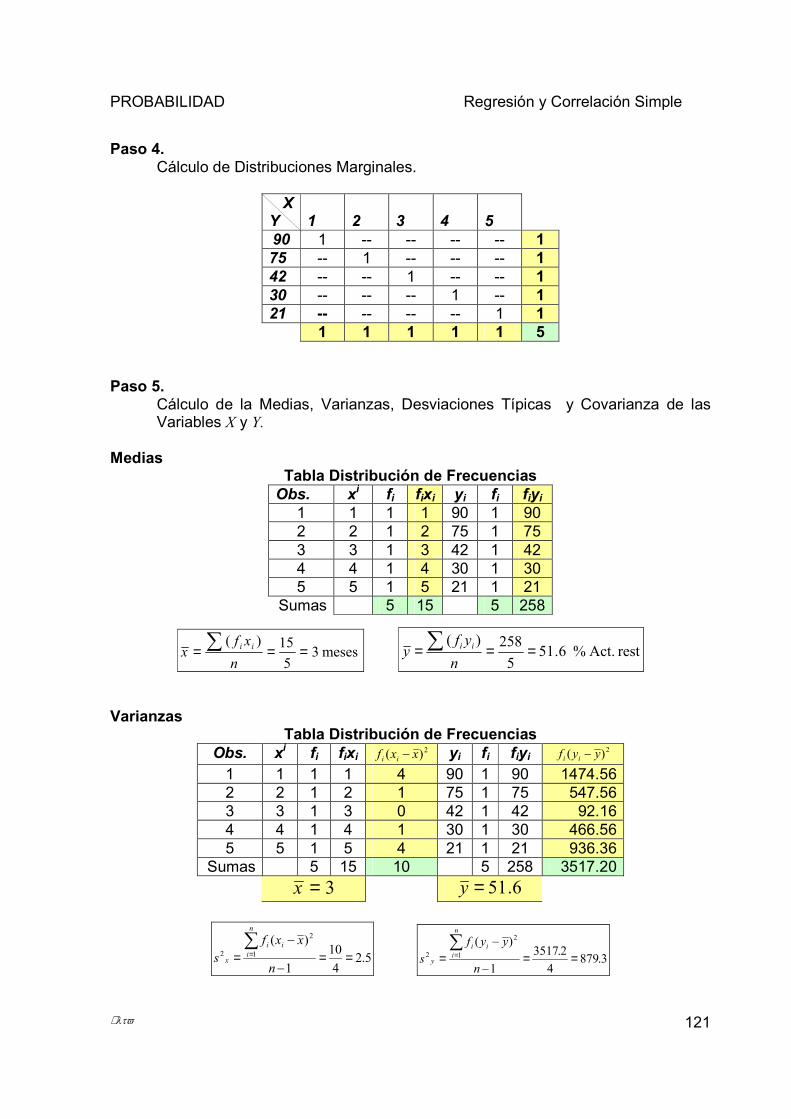
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 121
Paso 4. Cálculo de Distribuciones Marginales.
X
Y 1 2 3 4 590 1 -- -- -- -- 175 -- 1 -- -- -- 142 -- -- 1 -- -- 130 -- -- -- 1 -- 121 -- -- -- -- 1 1
1 1 1 1 1 5
Paso 5. Cálculo de la Medias, Varianzas, Desviaciones Típicas y Covarianza de las Variables X y Y.
Medias Tabla Distribución de Frecuencias
meses 35
15)(=== ∑
nxf
x ii rest Act. %6.515
258)(=== ∑
nyf
y ii
Varianzas Tabla Distribución de Frecuencias
5.24
101
)(1
2
2 ==−
−=∑
=
n
xxfs
n
iii
x 3.8794
2.35171
)(1
2
2 ==−
−=∑
=
n
yyfs
n
iii
y
Obs. xi fi fixi yi fi fiyi1 1 1 1 90 1 90 2 2 1 2 75 1 75 3 3 1 3 42 1 42 4 4 1 4 30 1 30 5 5 1 5 21 1 21
Sumas 5 15 5 258
Obs. xi fi fixi2)( xxf ii − yi fi fiyi
2)( yyf ii −
1 1 1 1 4 90 1 90 1474.562 2 1 2 1 75 1 75 547.563 3 1 3 0 42 1 42 92.164 4 1 4 1 30 1 30 466.565 5 1 5 4 21 1 21 936.36
Sumas 5 15 10 5 258 3517.203=x 6.51=y
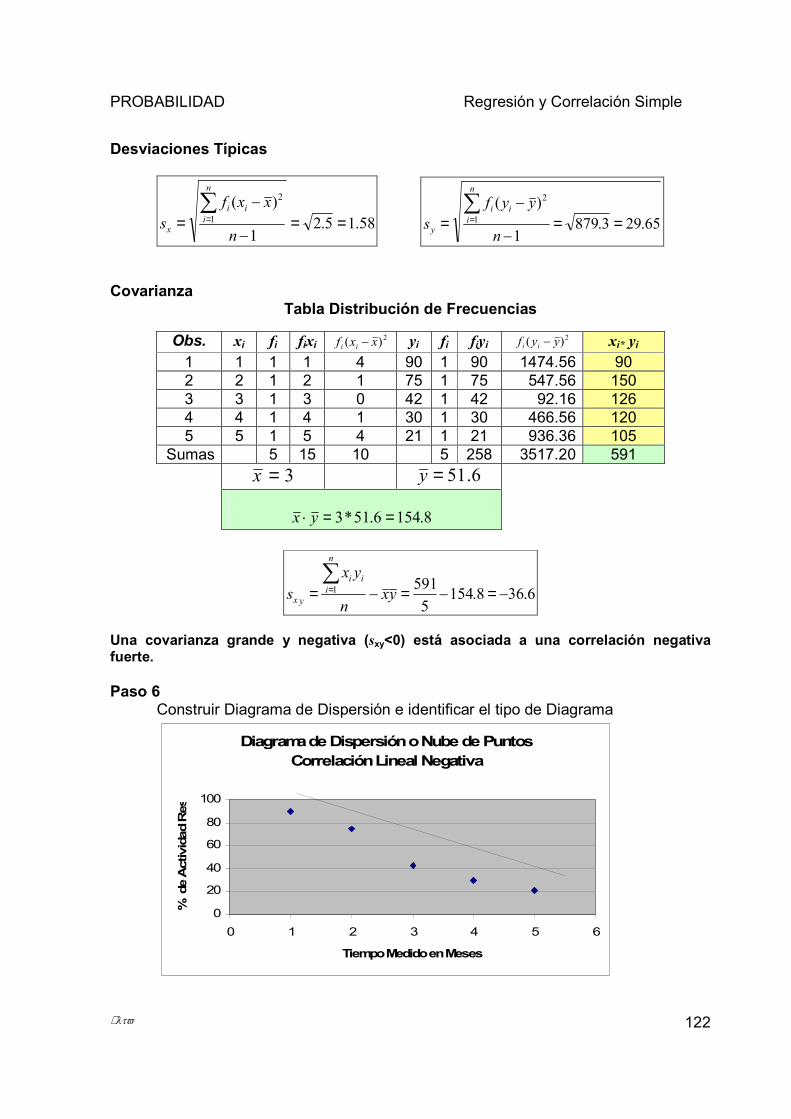
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 122
Desviaciones Típicas
58.15.21
)(1
2
==−
−=∑
=
n
xxfs
n
iii
x 65.293.8791
)(1
2
==−
−=∑
=
n
yyfs
n
iii
y
Covarianza Tabla Distribución de Frecuencias
6.368.1545
5911 −=−=−=∑
= yxn
yxs
n
iii
yx
Una covarianza grande y negativa (sxy<0) está asociada a una correlación negativa fuerte. Paso 6
Construir Diagrama de Dispersión e identificar el tipo de Diagrama
Diagrama de Dispersión o Nube de Puntos Correlación Lineal Negativa
0
20
40
60
80
100
0 1 2 3 4 5 6
Tiempo Medido en Meses
%de
Act
ivid
adR
es
Obs. xi fi fixi2)( xxf ii − yi fi fiyi
2)( yyf ii − xi* yi
1 1 1 1 4 90 1 90 1474.56 90 2 2 1 2 1 75 1 75 547.56 150 3 3 1 3 0 42 1 42 92.16 126 4 4 1 4 1 30 1 30 466.56 120 5 5 1 5 4 21 1 21 936.36 105
Sumas 5 15 10 5 258 3517.20 591 3=x 6.51=y
8.1546.51*3 ==⋅ yx

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 123
Paso 7.Calcular la Recta de Regresión de Y sobre X
A partir de la Media de X, Media de Y, Varianza de X (s2x) y la Covarianza (sxy)
se calcula la recta de regresión de Y sobre X
meses 35
15)(=== ∑
nxf
x ii rest Act. %6.515
258)(=== ∑
nyf
y ii
5.24
101
)(1
2
2 ==−
−=∑
=
n
xxfs
n
iii
x 6.368.1545
5911 −=−=−=∑
= yxn
yxs
n
iii
yx
Recta de Regresión de Y sobre Xbaxy +=
65.145.2
6.36
2
−=
−=
=x
xy
ss
a
52.95)52.95(
)5.5192.43()6.51365.14(
6.5135.2
5.36
2
=−−=
−−−=−∗−−=
−−
−=
−−= yx
ss
bx
xy
Esta recta encontrada la podemos utilizar para predecir resultados, por ejemplo: en 2.5 meses, ¿Qué % de actividad restante tendrá el compuesto?
5992.5852.956.36
52.955.265.14
≈=+−=
+∗=+= baxy
Estimación: Se espera que en 2.5 meses el compuesto tenga un 59 % de actividad restante.

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 124
Paso 8. Calcular la Recta de Regresión de X sobre Y
A partir de la Media de X, Media de Y, Varianza de Y (s2x) y la Covarianza (sxy)
se calcula la recta de regresión de Y sobre X.
meses 35
15)(=== ∑
nxf
x ii rest Act. %6.515
258)(=== ∑
nyf
y ii
3.8794
2.35171
)(1
2
2 ==−
−=∑
=
n
yyfs
n
iii
y 6.368.1545
5911 −=−=−=∑
= yxn
yxs
n
iii
yx
Recta de Regresión de X sobre Ybayx +=
0416.03.8796.36
2
−=
−=
=y
xy
ss
a
147.5)147.5(
)31477.2()36.510416.0(
36.513.8795.36
2
=−−=
−−−=−∗−−=
−−
−=
−−= xy
ss
by
xy
Esta recta encontrada la podemos utilizar para predecir resultados, por ejemplo: ¿en cuánto tiempo tendrá el compuesto aún un 50% de actividad restante?
306.3147.508.2
147.5500416.0
≈=+−=
+∗−=+= bayx
Estimación: Se espera que en 3 meses el compuesto aun tenga un 50% de actividad restante.

PROBABILIDAD Regresión y Correlación Simple
µλτϖ 125
Paso 9. Calcular el coeficiente de correlación de Pearson (r) a partir de las desviaciones típicas (sx y sy) y la covarianza (sxy) ya calculadas.
58.15.21
)(1
2
==−
−=∑
=
n
xxfs
n
iii
x 65.293.8791
)(1
2
==−
−=∑
=
n
yyfs
n
iii
y
6.368.1545
5911 −=−=−=∑
= yxn
yxs
n
iii
yx
78.088.45
6.3665.29*58.1
6.36
−=
−=
−=
=yx
xy
sss
r
r = -0.78 dado que tiende a -1, indica una correlación fuerte negativa
-1 0 1
Correlación negativa perfecta
Correlación positiva perfecta
No existe correlación
r = -0.78
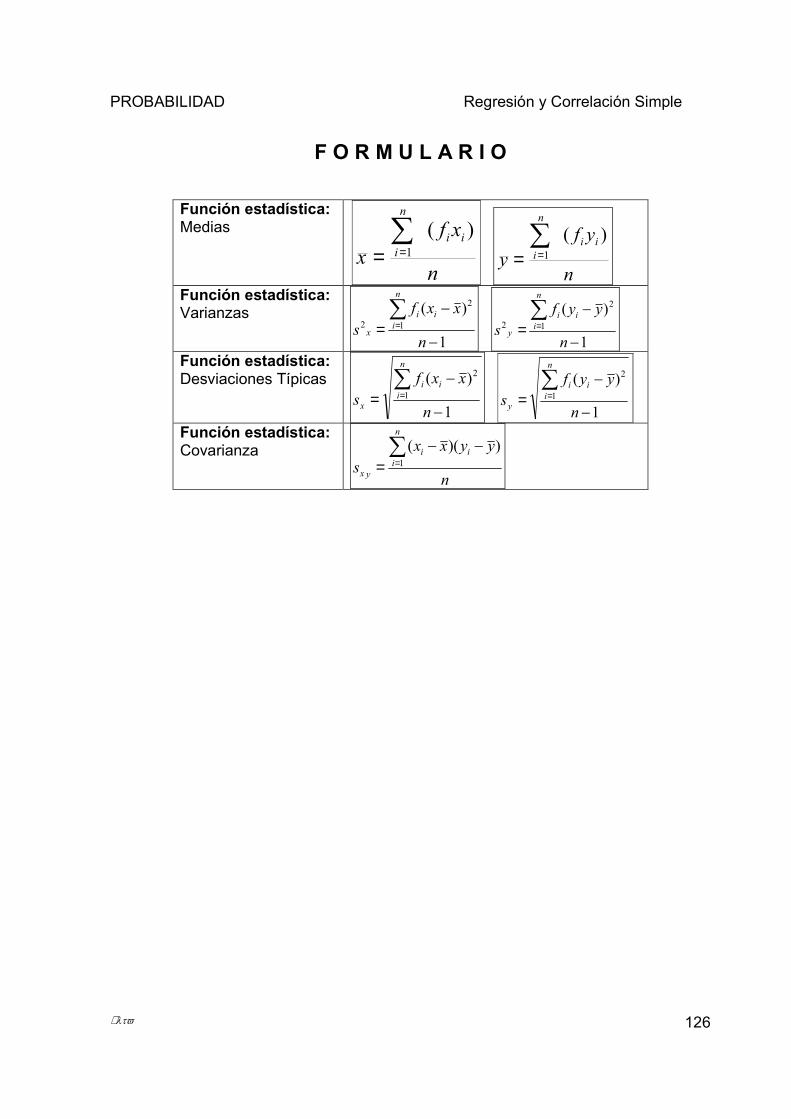
PROBABILIDAD Regresión y Correlación Simple
µλτϖ 126
F O R M U L A R I O
Función estadística: Medias
n
xfx
ii
n
i)(
1∑
==n
yfy
ii
n
i)(
1∑
==
Función estadística: Varianzas
1
)(1
2
2
−
−=∑
=
n
xxfs
n
iii
x1
)(1
2
2
−
−=∑
=
n
yyfs
n
iii
y
Función estadística: Desviaciones Típicas
1
)(1
2
−
−=∑
=
n
xxfs
n
iii
x 1
)(1
2
−
−=∑
=
n
yyfs
n
iii
y
Función estadística: Covarianza
n
yyxxs
n
iii
yx
∑=
−−= 1
))((

µλτϖ 127
Anexos
µλτϖ 128
Simbología
SÍMBOLO SIGNIFICADO
A, B, C, … Indican conjuntos
A, b, c, … Indican elementos
∈ Pertenece a, es elemento de
∉ No pertenece a, no es igual a
Tal que, dado que
= Es igual a, esta formado por
≠ No es igual a, es distinto a
→ Implica que
↔ Equivale a, si y sólo si
⊂ Está incluido en, es subconjunto propio de
⊄ No está incluido en, no es subconjunto de
⊆ Es subconjunto impropio de
Ω Conjunto Universal
∅ Conjunto Vacío
∪ Operación de Unión
∩ Operación de Intersección
A’; A Operación de Complemento
A\B; A - B Operación de Diferencia
( )n A Número de elementos del conjunto A

µλτϖ 129
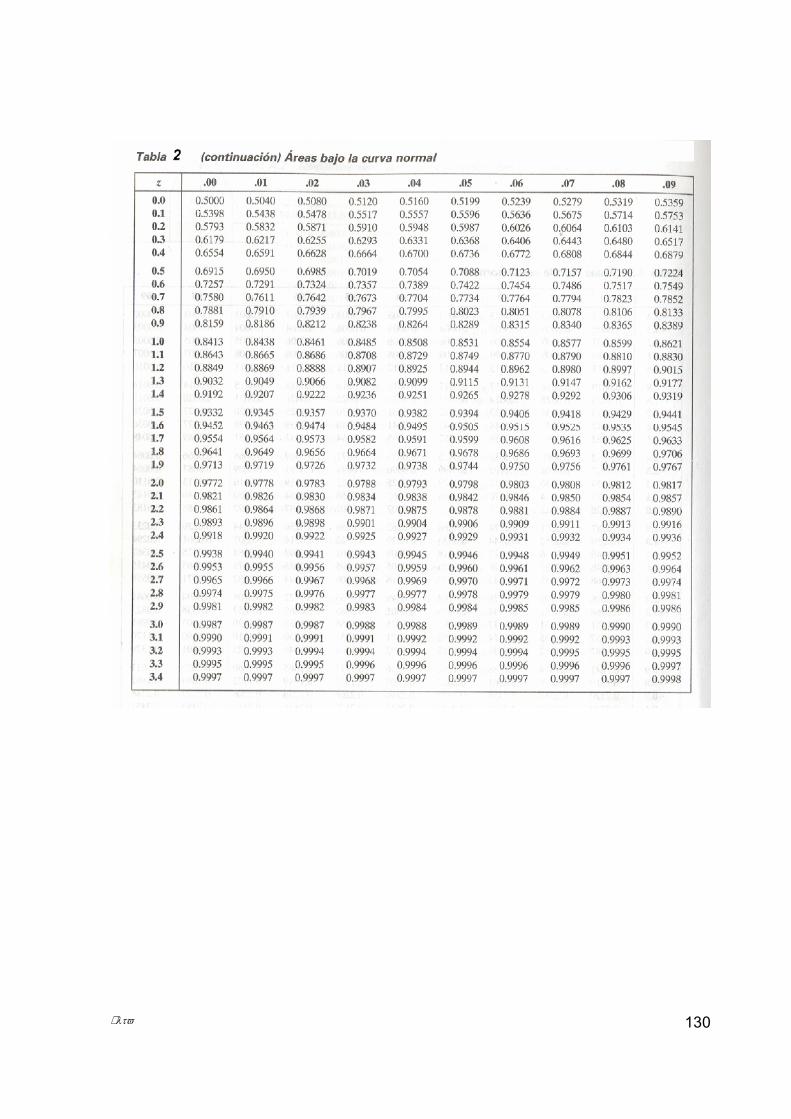
µλτϖ 130

µλτϖ 131
Referencias Bibliográficas
De la Barrera Frayre, Yolanda (2004). Probabilidad, Instituto Tecnológico de Durango, Durango, Dgo. México.
Devore, Jay L (1988). Probabilidad y Estadística para ingenieros y ciencias,Internacional Thomson, México, D. F.
Diccionario de la Lengua Española, Vigésima segunda edición, internet 2005.
Glover Danny. Tele-Serie Los números en la vida, “Introducción a la Probabilidad”, transmitida en el canal Edusat
Johnson, Richard A.(1997). Probabilidad y Estadística para Ingenieros de Millar y Freund, 5ª. Edición. Prentice Hall, México, D. F.
Lectus Vergara. Enciclopedia Universal del Saber. Las matemáticas como herramienta de la sociología; “Azar y Estadística”. Producido por CWD MEXICO, S.A. de C.V. México, dirección electrónica http://www.cwdmexico.com
Lipschutz, Seymour y Lipson, Marc Lars(2001). Teoría y Problemas de Probabilidad,Mc. Graw Hill, Colombia, 2ª. Edición
Márquez de Cantú, Maria José (1991). Probabilidad y Estadística para Ciencias Químico-Biológicas, Preedición, Ed. Mc Graw Hill, México.
Moriarty, James (Guinista) y Chamberlan, David (productor) Serie Concepts Matemáticos. Probabilidad. “Sucesos simples”, “Sucesos no tan simples”, Intento Bernoulli”. Producido por TVONTARIO y transmitido en el canal Edusat.
Montgomery, Douglas C. y Runger, George C(2002). Probabilidad y Estadística aplicada a la ingeniería, segunda edición, Ed Limusa Wiley, México

µλτϖ 132
Spiegel, Murray R. et al(2003). Probabilidad y Estadística, Mc. Graw Hill. México, D. F.
Torres Valles Maria de la Luz y Torres Alba Liborio (2004). Guía Didáctica de Probabilidad, Presentaciones Multimedia: “Estadística Descriptiva”, “Teoría de Conjuntos”, “Modelos Analíticos Discretos” y “Modelos Analíticos Continuos”. Durango, México: Instituto Tecnológico de Durango
Torres Valles Maria de la Luz y Torres Alba Liborio (2004). Guía Didáctica de Probabilidad, Autoevaluaciones Electrónicas: “Estadística Descriptiva”, “Fundamentos de Probabilidad”, “Modelos Analíticos Discretos” y “Modelos Analíticos Contínuos”. Durango, México: Instituto Tecnológico de Durango.
Walpole, Ronald E., Myers, Raymond H. y Myers Sharon L. (1999). Probabilidad y Estadística para Ingenieros, Pearson Educación. México.